try this:
declare @YourTable table (id int, name varchar(10), email varchar(50))
INSERT @YourTable VALUES (1,'John','John-email')
INSERT @YourTable VALUES (2,'John','John-email')
INSERT @YourTable VALUES (3,'fred','John-email')
INSERT @YourTable VALUES (4,'fred','fred-email')
INSERT @YourTable VALUES (5,'sam','sam-email')
INSERT @YourTable VALUES (6,'sam','sam-email')
SELECT
name,email, COUNT(*) AS CountOf
FROM @YourTable
GROUP BY name,email
HAVING COUNT(*)>1
OUTPUT:
name email CountOf
---------- ----------- -----------
John John-email 2
sam sam-email 2
(2 row(s) affected)
if you want the IDs of the dups use this:
SELECT
y.id,y.name,y.email
FROM @YourTable y
INNER JOIN (SELECT
name,email, COUNT(*) AS CountOf
FROM @YourTable
GROUP BY name,email
HAVING COUNT(*)>1
) dt ON y.name=dt.name AND y.email=dt.email
OUTPUT:
id name email
----------- ---------- ------------
1 John John-email
2 John John-email
5 sam sam-email
6 sam sam-email
(4 row(s) affected)
to delete the duplicates try:
DELETE d
FROM @YourTable d
INNER JOIN (SELECT
y.id,y.name,y.email,ROW_NUMBER() OVER(PARTITION BY y.name,y.email ORDER BY y.name,y.email,y.id) AS RowRank
FROM @YourTable y
INNER JOIN (SELECT
name,email, COUNT(*) AS CountOf
FROM @YourTable
GROUP BY name,email
HAVING COUNT(*)>1
) dt ON y.name=dt.name AND y.email=dt.email
) dt2 ON d.id=dt2.id
WHERE dt2.RowRank!=1
SELECT * FROM @YourTable
OUTPUT:
id name email
----------- ---------- --------------
1 John John-email
3 fred John-email
4 fred fred-email
5 sam sam-email
(4 row(s) affected)
I have a table with a varchar column, and I would like to find all the records that have duplicate values in this column. What is the best query I can use to find the duplicates?
asked Mar 27, 2009 at 4:22
![]()
Jon TackaburyJon Tackabury
47.4k50 gold badges129 silver badges167 bronze badges
3
Do a SELECT with a GROUP BY clause. Let’s say name is the column you want to find duplicates in:
SELECT name, COUNT(*) c FROM table GROUP BY name HAVING c > 1;
This will return a result with the name value in the first column, and a count of how many times that value appears in the second.
![]()
the Tin Man
158k41 gold badges214 silver badges302 bronze badges
answered Mar 27, 2009 at 4:24
![]()
12
SELECT varchar_col
FROM table
GROUP BY varchar_col
HAVING COUNT(*) > 1;
![]()
simhumileco
31.2k16 gold badges137 silver badges112 bronze badges
answered Mar 27, 2009 at 4:27
![]()
maxyfcmaxyfc
11.1k7 gold badges36 silver badges46 bronze badges
2
SELECT *
FROM mytable mto
WHERE EXISTS
(
SELECT 1
FROM mytable mti
WHERE mti.varchar_column = mto.varchar_column
LIMIT 1, 1
)
ORDER BY varchar_column
This query returns complete records, not just distinct varchar_column‘s.
This query doesn’t use COUNT(*). If there are lots of duplicates, COUNT(*) is expensive, and you don’t need the whole COUNT(*), you just need to know if there are two rows with same value.
This is achieved by the LIMIT 1, 1 at the bottom of the correlated query (essentially meaning “return the second row”). EXISTS would only return true if the aforementioned second row exists (i. e. there are at least two rows with the same value of varchar_column) .
Having an index on varchar_column will, of course, speed up this query greatly.
![]()
techtheatre
5,4887 gold badges31 silver badges51 bronze badges
answered Mar 27, 2009 at 10:54
![]()
QuassnoiQuassnoi
411k91 gold badges612 silver badges612 bronze badges
11
Building off of levik’s answer to get the IDs of the duplicate rows you can do a GROUP_CONCAT if your server supports it (this will return a comma separated list of ids).
SELECT GROUP_CONCAT(id), name, COUNT(*) c
FROM documents
GROUP BY name
HAVING c > 1;
![]()
Novocaine
4,6434 gold badges43 silver badges66 bronze badges
answered Feb 19, 2015 at 0:56
![]()
Matt R.Matt R.
2,1291 gold badge16 silver badges19 bronze badges
3
to get all the data that contains duplication i used this:
SELECT * FROM TableName INNER JOIN(
SELECT DupliactedData FROM TableName GROUP BY DupliactedData HAVING COUNT(DupliactedData) > 1 order by DupliactedData)
temp ON TableName.DupliactedData = temp.DupliactedData;
TableName = the table you are working with.
DupliactedData = the duplicated data you are looking for.
![]()
slfan
8,920115 gold badges65 silver badges78 bronze badges
answered May 8, 2019 at 8:40
![]()
udiudi
2413 silver badges5 bronze badges
2
Assuming your table is named TableABC and the column which you want is Col and the primary key to T1 is Key.
SELECT a.Key, b.Key, a.Col
FROM TableABC a, TableABC b
WHERE a.Col = b.Col
AND a.Key <> b.Key
The advantage of this approach over the above answer is it gives the Key.
answered Mar 27, 2009 at 4:29
![]()
TechTravelThinkTechTravelThink
2,9843 gold badges20 silver badges13 bronze badges
3
Taking @maxyfc’s answer further, I needed to find all of the rows that were returned with the duplicate values, so I could edit them in MySQL Workbench:
SELECT * FROM table
WHERE field IN (
SELECT field FROM table GROUP BY field HAVING count(*) > 1
) ORDER BY field
answered Aug 1, 2017 at 22:29
![]()
AbsoluteƵERØAbsoluteƵERØ
7,8162 gold badges24 silver badges35 bronze badges
SELECT *
FROM `dps`
WHERE pid IN (SELECT pid FROM `dps` GROUP BY pid HAVING COUNT(pid)>1)
![]()
demongolem
9,42036 gold badges90 silver badges105 bronze badges
answered May 22, 2014 at 14:48
![]()
strustamstrustam
1211 silver badge2 bronze badges
1
To find how many records are duplicates in name column in Employee, the query below is helpful;
Select name from employee group by name having count(*)>1;
![]()
davejal
5,98910 gold badges39 silver badges82 bronze badges
answered Nov 24, 2015 at 12:12
![]()
0
My final query incorporated a few of the answers here that helped – combining group by, count & GROUP_CONCAT.
SELECT GROUP_CONCAT(id), `magento_simple`, COUNT(*) c
FROM product_variant
GROUP BY `magento_simple` HAVING c > 1;
This provides the id of both examples (comma separated), the barcode I needed, and how many duplicates.
Change table and columns accordingly.
answered May 5, 2017 at 2:38
![]()
I am not seeing any JOIN approaches, which have many uses in terms of duplicates.
This approach gives you actual doubled results.
SELECT t1.* FROM my_table as t1
LEFT JOIN my_table as t2
ON t1.name=t2.name and t1.id!=t2.id
WHERE t2.id IS NOT NULL
ORDER BY t1.name
![]()
Mahbub
4,7321 gold badge31 silver badges34 bronze badges
answered Apr 20, 2018 at 10:33
![]()
Adam FischerAdam Fischer
1,07511 silver badges23 bronze badges
1
I saw the above result and query will work fine if you need to check single column value which are duplicate. For example email.
But if you need to check with more columns and would like to check the combination of the result so this query will work fine:
SELECT COUNT(CONCAT(name,email)) AS tot,
name,
email
FROM users
GROUP BY CONCAT(name,email)
HAVING tot>1 (This query will SHOW the USER list which ARE greater THAN 1
AND also COUNT)
![]()
davejal
5,98910 gold badges39 silver badges82 bronze badges
answered May 30, 2016 at 7:42
1
I prefer to use windowed functions(MySQL 8.0+) to find duplicates because I could see entire row:
WITH cte AS (
SELECT *
,COUNT(*) OVER(PARTITION BY col_name) AS num_of_duplicates_group
,ROW_NUMBER() OVER(PARTITION BY col_name ORDER BY col_name2) AS pos_in_group
FROM table
)
SELECT *
FROM cte
WHERE num_of_duplicates_group > 1;
DB Fiddle Demo
answered Jul 12, 2018 at 17:40
![]()
Lukasz SzozdaLukasz Szozda
159k23 gold badges221 silver badges263 bronze badges
SELECT t.*,(select count(*) from city as tt
where tt.name=t.name) as count
FROM `city` as t
where (
select count(*) from city as tt
where tt.name=t.name
) > 1 order by count desc
Replace city with your Table.
Replace name with your field name
![]()
AbsoluteƵERØ
7,8162 gold badges24 silver badges35 bronze badges
answered Jan 25, 2013 at 5:59
![]()
0
SELECT ColumnA, COUNT( * )
FROM Table
GROUP BY ColumnA
HAVING COUNT( * ) > 1
![]()
AsgarAli
2,2011 gold badge20 silver badges32 bronze badges
answered Mar 27, 2009 at 4:28
![]()
Scott FergusonScott Ferguson
7,6707 gold badges41 silver badges64 bronze badges
1
I improved from this:
SELECT
col,
COUNT(col)
FROM
table_name
GROUP BY col
HAVING COUNT(col) > 1;
answered Oct 29, 2020 at 22:57
![]()
As a variation on Levik’s answer that allows you to find also the ids of the duplicate results, I used the following:
SELECT * FROM table1 WHERE column1 IN (SELECT column1 AS duplicate_value FROM table1 GROUP BY column1 HAVING COUNT(*) > 1)
answered Feb 24, 2021 at 1:07
![]()
SELECT
t.*,
(SELECT COUNT(*) FROM city AS tt WHERE tt.name=t.name) AS count
FROM `city` AS t
WHERE
(SELECT count(*) FROM city AS tt WHERE tt.name=t.name) > 1 ORDER BY count DESC
![]()
Moseleyi
2,5161 gold badge22 silver badges45 bronze badges
answered Feb 21, 2013 at 8:37
![]()
1
CREATE TABLE tbl_master
(`id` int, `email` varchar(15));
INSERT INTO tbl_master
(`id`, `email`) VALUES
(1, 'test1@gmail.com'),
(2, 'test2@gmail.com'),
(3, 'test1@gmail.com'),
(4, 'test2@gmail.com'),
(5, 'test5@gmail.com');
QUERY : SELECT id, email FROM tbl_master
WHERE email IN (SELECT email FROM tbl_master GROUP BY email HAVING COUNT(id) > 1)
![]()
kodabear
3401 silver badge14 bronze badges
answered Mar 4, 2016 at 7:55
![]()
SELECT DISTINCT a.email FROM `users` a LEFT JOIN `users` b ON a.email = b.email WHERE a.id != b.id;
![]()
answered Jul 1, 2013 at 18:17
![]()
Pawel FurmaniakPawel Furmaniak
4,6203 gold badges29 silver badges33 bronze badges
5
For removing duplicate rows with multiple fields , first cancate them to the new unique key which is specified for the only distinct rows, then use “group by” command to removing duplicate rows with the same new unique key:
Create TEMPORARY table tmp select concat(f1,f2) as cfs,t1.* from mytable as t1;
Create index x_tmp_cfs on tmp(cfs);
Create table unduptable select f1,f2,... from tmp group by cfs;
answered Feb 4, 2016 at 9:58
2
One very late contribution… in case it helps anyone waaaaaay down the line… I had a task to find matching pairs of transactions (actually both sides of account-to-account transfers) in a banking app, to identify which ones were the ‘from’ and ‘to’ for each inter-account-transfer transaction, so we ended up with this:
SELECT
LEAST(primaryid, secondaryid) AS transactionid1,
GREATEST(primaryid, secondaryid) AS transactionid2
FROM (
SELECT table1.transactionid AS primaryid,
table2.transactionid AS secondaryid
FROM financial_transactions table1
INNER JOIN financial_transactions table2
ON table1.accountid = table2.accountid
AND table1.transactionid <> table2.transactionid
AND table1.transactiondate = table2.transactiondate
AND table1.sourceref = table2.destinationref
AND table1.amount = (0 - table2.amount)
) AS DuplicateResultsTable
GROUP BY transactionid1
ORDER BY transactionid1;
The result is that the DuplicateResultsTable provides rows containing matching (i.e. duplicate) transactions, but it also provides the same transaction id’s in reverse the second time it matches the same pair, so the outer SELECT is there to group by the first transaction ID, which is done by using LEAST and GREATEST to make sure the two transactionid’s are always in the same order in the results, which makes it safe to GROUP by the first one, thus eliminating all the duplicate matches. Ran through nearly a million records and identified 12,000+ matches in just under 2 seconds. Of course the transactionid is the primary index, which really helped.
![]()
answered Sep 6, 2016 at 13:52
![]()
0
Select column_name, column_name1,column_name2, count(1) as temp from table_name group by column_name having temp > 1
answered Dec 18, 2015 at 18:21
![]()
Vipin JainVipin Jain
3,67816 silver badges35 bronze badges
If you want to remove duplicate use DISTINCT
Otherwise use this query:
SELECT users.*,COUNT(user_ID) as user FROM users GROUP BY user_name HAVING user > 1;
![]()
benc
1,3435 gold badges31 silver badges39 bronze badges
answered Jan 14, 2019 at 7:21
![]()
Thanks to @novocaine for his great answer and his solution worked for me. I altered it slightly to include a percentage of the recurring values, which was needed in my case. Below is the altered version. It reduces the percentage to two decimal places. If you change the ,2 to 0, it will display no decimals, and to 1, then it will display one decimal place, and so on.
SELECT GROUP_CONCAT(id), name, COUNT(*) c,
COUNT(*) OVER() AS totalRecords,
CONCAT(FORMAT(COUNT(*)/COUNT(*) OVER()*100,2),'%') as recurringPecentage
FROM table
GROUP BY name
HAVING c > 1
answered Sep 21, 2021 at 14:36
![]()
Iwan RossIwan Ross
1962 silver badges10 bronze badges
Try using this query:
SELECT name, COUNT(*) value_count FROM company_master GROUP BY name HAVING value_count > 1;
![]()
answered Nov 15, 2018 at 9:16
![]()
Приветствую всех на сайте Info-Comp.ru! В этой небольшой заметке я покажу, как можно на SQL вывести повторяющиеся значения в столбце таблицы в Microsoft SQL Server. Все будет рассмотрено очень подробно и с примерами.

Заметка! Профессиональный видеокурс по T-SQL для начинающих.
Содержание
- Исходные данные для примеров
- Выводим повторяющиеся значения в столбце на T-SQL
- Выводим все строки с повторяющимися значениями на T-SQL
Исходные данные для примеров
Сначала давайте я расскажу, какие данные я буду использовать в статье, чтобы Вы четко понимали и видели, какие результаты будут возвращаться, если выполнять те или иные действия.
Сразу скажу, что все данные тестовые.
Следующей инструкцией мы создаем таблицу Goods и добавляем в нее несколько строк, в некоторых из которых значение столбца Price будет повторяться.
Останавливаться на том, что делает та или иная инструкция, я не буду, так как это другая тема, если Вам интересно, можете более подробно посмотреть в следующих статьях:
- Создание таблиц в Microsoft SQL Server (CREATE TABLE);
- Добавление данных в таблицы Microsoft SQL Server (INSERT INTO).
--Создание таблицы Goods
CREATE TABLE Goods (
ProductId INT IDENTITY(1,1) NOT NULL CONSTRAINT PK_ProductId PRIMARY KEY,
ProductName VARCHAR(100) NOT NULL,
Price MONEY NULL,
);
GO
--Добавление строк в таблицу Goods
INSERT INTO Goods(ProductName, Price)
VALUES ('Системный блок', 100),
('Монитор', 200),
('Сканер', 150),
('Принтер', 200),
('Клавиатура', 50),
('Смартфон', 300),
('Мышь', 20),
('Планшет', 300),
('Процессор', 200);
GO
--Выборка данных
SELECT ProductId, ProductName, Price
FROM Goods;
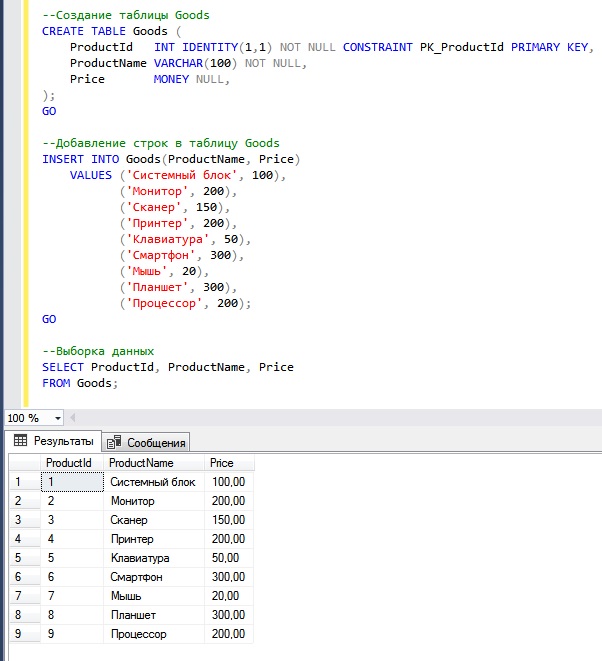
Вы видите, какие данные есть, именно к ним я буду посылать SQL запрос, который будет определять и выводить повторяющиеся значения в столбце Price.
Основной алгоритм определения повторяющихся значений в столбце состоит в том, что нам нужно сгруппировать все строки по столбцу, в котором необходимо найти повторяющиеся значения, и подсчитать количество строк в каждой сгруппированной строке, а затем просто поставить фильтр (>1) на итоговое количество, отбросив тем самым строки со значением 1, т.е. если значение встречается всего один раз, значит, оно не повторяется, и нам не нужно.

Вот пример всего вышесказанного.
--Определяем повторяющиеся значения в столбце SELECT Price, COUNT(*) AS CNT FROM Goods GROUP BY Price HAVING COUNT(*) > 1;
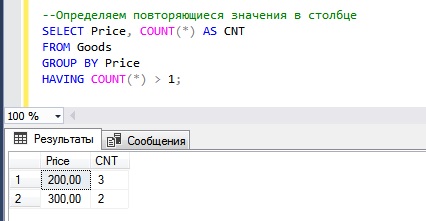
Мы видим, что у нас есть всего два значения, которые повторяются — это 200 и 300. Первое значение, т.е. 200, повторяется 3 раза, второе — 2 раза.
Данные сгруппировали мы конструкцией GROUP BY, подсчитали количество значений встроенной функцией COUNT, а отфильтровали сгруппированные строки конструкцией HAVING.
Выводим все строки с повторяющимися значениями на T-SQL
Но в большинстве случаев просто узнать повторяющиеся в столбце значения недостаточно, иногда необходимо вывести все записи в этой таблице, которые содержат эти повторяющиеся значения.
Это можно реализовать с помощью подзапроса, но использовать подзапрос, в котором будет группировка, не очень удобно, и уж точно неудобочитаемо. Поэтому мне нравится в каких-то подобных случаях использовать CTE (обобщённое табличное выражение) для повышения читабельности кода. Также чтобы сделать результирующий набор данных более наглядным, его можно отсортировать по целевому столбцу, тем самым мы сразу увидим строки с повторяющимися значениями.
Вот пример, в котором мы выводим все строки с повторяющимися значениями в столбце, отсортированные по столбцу Price.
--Выводим все строки с повторяющимися значениями
WITH DuplicateValue AS (
SELECT Price, COUNT(*) AS CNT
FROM Goods
GROUP BY Price
HAVING COUNT(*) > 1
)
SELECT ProductId, ProductName, Price
FROM Goods
WHERE Price IN (SELECT Price FROM DuplicateValue)
ORDER BY Price, ProductId;
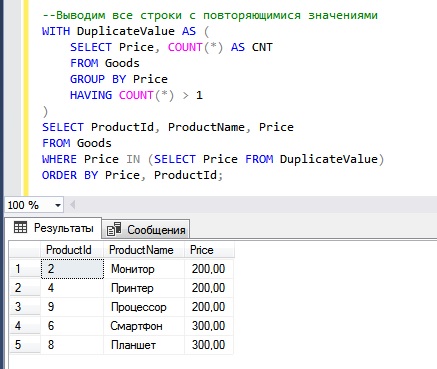
Как видим, сначала у нас идут все строки со значением 200, а затем строки со значением 300. Сортировку мы осуществили конструкцией ORDER BY. Если у Вас возникает вопрос, что такое DuplicateValue, то это всего лишь название CTE выражения, в принципе Вы его можете назвать и по-другому.
Заметка!
Для комплексного изучения языка T-SQL рекомендую почитать мои книги и пройти курсы:
- SQL код – самоучитель по языку SQL для начинающих;
- Стиль программирования на T-SQL – основы правильного написания кода. Книга, направленная на повышение качества T-SQL кода;
- Профессиональные видеокурсы по T-SQL.
У меня на этом все, надеюсь, материал был Вам полезен. Удачи Вам, пока!
Сборник запросов для поиска, изменения и удаления дублей в таблице MySQL по одному и нескольким полям. В примерах все запросы будут применятся к следующий таблице:
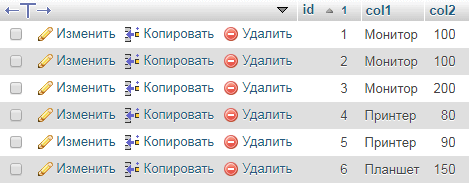
1
Поиск дубликатов
Подсчет дублей
Запрос подсчитает количество всех записей с одинаковыми значениями в поле `col1`.
SELECT
`col1`,
COUNT(`col1`) AS `count`
FROM
`table`
GROUP BY
`col1`
HAVING
`count` > 1SQL

Подсчет дубликатов по нескольким полям:
SELECT
`col1`,
`col2`,
COUNT(*) AS `count`
FROM
`table`
GROUP BY
`col1`,`col2`
HAVING
`count` > 1SQL

Все записи с одинаковыми значениями
Запрос найдет все записи с одинаковыми значениями в `col1`.
SELECT
*
FROM
`table`
WHERE
`col1` IN (SELECT `col1` FROM `table` GROUP BY `col1` HAVING COUNT(*) > 1)
ORDER BY
`col1`SQL
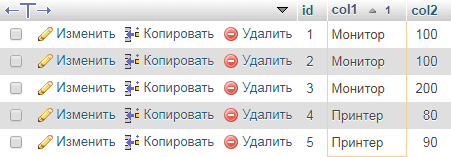
Для одинаковых значений в `col1` и `col2`:
SELECT
*
FROM
`table`
WHERE
`col1` IN (SELECT `col1` FROM `table` GROUP BY `col1` HAVING COUNT(*) > 1)
AND `col2` IN (SELECT `col2` FROM `table` GROUP BY `col2` HAVING COUNT(*) > 1)
ORDER BY
`col1`SQL
Получить только дубликаты
Запрос получит только дубликаты, в результат не попадают записи с самым ранним `id`.
SELECT
`table`.*
FROM
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1` FROM `table` GROUP BY `col1`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
WHERE
`tmp`.`id` IS NULLSQL

Для нескольких полей:
SELECT
`table`.*
FROM
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1`, `col2` FROM `table` GROUP BY `col1`, `col2`) AS `tmp`
ON
`a`.`id` = `tmp`.`id`
WHERE
`tmp`.`id` IS NULLSQL
2
Уникализация записей
Запрос сделает уникальные названия только у дублей, дописав `id` в конец `col1`.
UPDATE
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1` FROM `table` GROUP BY `col1`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
SET
`table`.`col1` = CONCAT(`table`.`col1`, '-', `table`.`id`)
WHERE
`tmp`.`id` IS NULLSQL
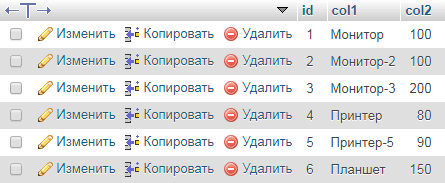
По нескольким полям:
UPDATE
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1`, `col2` FROM `table` GROUP BY `col1`, `col2`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
SET
`table`.`col1` = CONCAT(`table`.`col1`, '-', `table`.`id`)
WHERE
`tmp`.`id` IS NULLSQL
3
Удаление дубликатов
Удаление дублирующихся записей, останутся только уникальные.
DELETE
`table`
FROM
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1` FROM `table` GROUP BY `col1`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
WHERE
`tmp`.`id` IS NULLSQL
По нескольким полям:
DELETE
`table`
FROM
`table`
LEFT OUTER JOIN
(SELECT MIN(`id`) AS `id`, `col1`, `col2` FROM `table` GROUP BY `col1`, `col2`) AS `tmp`
ON
`table`.`id` = `tmp`.`id`
WHERE
`tmp`.`id` IS NULLSQL
Избыточные данные могут храниться в таблице программой базы данных, влияя на вывод базы данных в MySQL. Однако репликация данных выполняется для разных целей, и идентификация повторяющихся значений в таблице является важной задачей при работе с базой данных MySQL. В общем, разумно часто использовать четкие ограничения для таблицы, чтобы хранить информацию, которая предотвращает появление избыточных строк. Иногда в базе данных MySQL вам может потребоваться подсчитать количество повторяющихся значений. Мы рассмотрели этот вопрос в этой теме, в которой вы узнаете, как находить повторяющиеся значения разными способами и как подсчитывать повторяющиеся значения.
Для начала у вас должен быть установлен MySQL в вашей системе со своими утилитами: рабочая среда MySQL и клиентская оболочка командной строки. После этого у вас должны быть дубликаты некоторых данных или значений в таблицах базы данных. Давайте рассмотрим это на нескольких примерах. Прежде всего, откройте клиентскую оболочку командной строки с панели задач рабочего стола и введите свой пароль MySQL по запросу.
Мы нашли разные методы поиска дубликатов в таблице. Взгляните на них один за другим.
Поиск дубликатов в одном столбце
Во-первых, вы должны знать синтаксис запроса, используемого для проверки и подсчета дубликатов для одного столбца.
>> SELECT col COUNT(col) FROM table GROUP BY col HAVING COUNT(col) > 1;
Вот объяснение вышеуказанного запроса:
- Столбец: имя проверяемого столбца.
- COUNT(): функция, используемая для подсчета множества повторяющихся значений.
- GROUP BY: предложение, используемое для группировки всех строк в соответствии с этим конкретным столбцом.
Мы создали новую таблицу под названием «animals» в «data» нашей базы данных MySQL, имеющую повторяющиеся значения. Он имеет шесть столбцов с разными значениями, например, id, Name, Species, Gender, Age и Price, предоставляя информацию о различных домашних животных. После вызова этой таблицы с помощью запроса SELECT мы получаем следующий вывод в нашей клиентской оболочке командной строки MySQL.
>> SELECT * FROM data.animals;
Теперь мы попытаемся найти повторяющиеся и повторяющиеся значения из приведенной выше таблицы, используя функцию COUNT и GROUP BY в запросе SELECT. Этот запрос будет считать имена домашних животных, которые встречаются в таблице менее трех раз. После этого он отобразит эти имена, как показано ниже.
>> SELECT Name COUNT(Name) FROM data.animals GROUP BY Name HAVING COUNT(Name) < 3;
Использование того же запроса для получения разных результатов при изменении числа COUNT для имен домашних животных, как показано ниже.
>> SELECT Name COUNT(Name) FROM data.animals GROUP BY Name HAVING COUNT(Name) > 3;
Чтобы получить результаты для 3 повторяющихся значений для имен домашних животных, как показано ниже.
>> SELECT Name COUNT(Name) FROM data.animals GROUP BY Name HAVING COUNT(Name) = 3;
Искать дубликаты в нескольких столбцах
Синтаксис запроса для проверки или подсчета дубликатов для нескольких столбцов следующий:
>> SELECT col1, COUNT(col1), col2, COUNT(col2) FROM table GROUP BY col1, col2 HAVING COUNT(col1) > 1 AND COUNT(col2) > 1;
Вот объяснение вышеуказанного запроса:
- col1, col2: имя проверяемых столбцов.
- COUNT(): функция, используемая для подсчета нескольких повторяющихся значений.
- GROUP BY: предложение, используемое для группировки всех строк в соответствии с этим конкретным столбцом.
Мы использовали ту же таблицу под названием «животные» с повторяющимися значениями. Мы получили приведенный ниже результат, используя указанный выше запрос для проверки повторяющихся значений в нескольких столбцах. Мы проверяли и подсчитывали повторяющиеся значения для столбцов «Gender» и «Price», сгруппированные по столбцу «Price». Он покажет пол домашних животных и их цены, которые находятся в таблице, как дубликаты не более 5.
>> SELECT Gender, COUNT(Gender), Price, COUNT(Price) FROM data.animals GROUP BY Price HAVING COUNT(Price) < 5 AND COUNT(Gender) < 5;
Поиск дубликатов в одной таблице с помощью INNER JOIN
Вот основной синтаксис для поиска дубликатов в одной таблице:
>> SELECT col1, col2, table.col FROM table INNER JOIN(SELECT col FROM table GROUP BY col HAVING COUNT(col1) > 1) temp ON table.col= temp.col;
Вот описание служебного запроса:
- Col: имя столбца, который нужно проверить и выбрать для дублирования.
- Temp: ключевое слово для применения внутреннего соединения к столбцу.
- Таблица: имя проверяемой таблицы.
У нас есть новая таблица order2 с повторяющимися значениями в столбце OrderNo, как показано ниже.
>> SELECT * FROM data.order2;
Мы выбираем три столбца: Item, Sales, OrderNo, которые будут отображаться в выводе. В то время как столбец OrderNo используется для проверки дубликатов. Внутреннее соединение выберет значения или строки, имеющие значения элементов более одного в таблице. После выполнения мы получим следующие результаты.
>> SELECT Item, Sales, order2.OrderNo FROM data.order2 INNER JOIN(SELECT OrderNo FROM data.order2 GROUP BY OrderNo HAVING COUNT(Item) > 1) temp ON order2.OrderNo= temp.OrderNo;
Поиск дубликатов в нескольких таблицах с помощью INNER JOIN
Вот упрощенный синтаксис для поиска дубликатов в нескольких таблицах:
>> SELECT col FROM table1 INNER JOIN table2 ON table1.col = table2.col;
Вот описание служебного запроса:
- col: имя столбцов, которые нужно проверить и выбрать.
- INNER JOIN: функция, используемая для соединения двух таблиц.
- ВКЛ: используется для объединения двух таблиц в соответствии с предоставленными столбцами.
У нас есть две таблицы, «order1» и «order2», в нашей базе данных со столбцом «OrderNo» в обеих, как показано ниже.
Мы будем использовать INNER join для объединения дубликатов двух таблиц в соответствии с указанным столбцом. Предложение INNER JOIN получит все данные из обеих таблиц, объединив их, а предложение ON будет связывать столбцы с одинаковыми именами из обеих таблиц, например, OrderNo.
>> SELECT * FROM data.order1 INNER JOIN data.order2 ON order1.OrderNo = order2.OrderNO;
Чтобы получить определенные столбцы в выходных данных, попробуйте следующую команду:
>> SELECT Region, Status, Item, Sales FROM data.order1 INNER JOIN data.order2 ON order1.OrderNo = order2.OrderNO;
Вывод
Теперь мы могли искать несколько копий в одной или нескольких таблицах информации MySQL и распознавать функции GROUP BY, COUNT и INNER JOIN. Убедитесь, что вы правильно построили таблицы и что выбраны правильные столбцы.
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
