This stored procedure will provide you with a hierarchical tree of relationship. Based on this article from Technet. It will also optionally provide you a query for reading or deleting all the related data.
IF OBJECT_ID('GetForeignKeyRelations','P') IS NOT NULL
DROP PROC GetForeignKeyRelations
GO
CREATE PROC GetForeignKeyRelations
@Schemaname Sysname = 'dbo'
,@Tablename Sysname
,@WhereClause NVARCHAR(2000) = ''
,@GenerateDeleteScripts bit = 0
,@GenerateSelectScripts bit = 0
AS
SET NOCOUNT ON
DECLARE @fkeytbl TABLE
(
ReferencingObjectid int NULL
,ReferencingSchemaname Sysname NULL
,ReferencingTablename Sysname NULL
,ReferencingColumnname Sysname NULL
,PrimarykeyObjectid int NULL
,PrimarykeySchemaname Sysname NULL
,PrimarykeyTablename Sysname NULL
,PrimarykeyColumnname Sysname NULL
,Hierarchy varchar(max) NULL
,level int NULL
,rnk varchar(max) NULL
,Processed bit default 0 NULL
);
WITH fkey (ReferencingObjectid,ReferencingSchemaname,ReferencingTablename,ReferencingColumnname
,PrimarykeyObjectid,PrimarykeySchemaname,PrimarykeyTablename,PrimarykeyColumnname,Hierarchy,level,rnk)
AS
(
SELECT
soc.object_id
,scc.name
,soc.name
,convert(sysname,null)
,convert(int,null)
,convert(sysname,null)
,convert(sysname,null)
,convert(sysname,null)
,CONVERT(VARCHAR(MAX), scc.name + '.' + soc.name ) as Hierarchy
,0 as level
,rnk=convert(varchar(max),soc.object_id)
FROM SYS.objects soc
JOIN sys.schemas scc
ON soc.schema_id = scc.schema_id
WHERE scc.name =@Schemaname
AND soc.name =@Tablename
UNION ALL
SELECT sop.object_id
,scp.name
,sop.name
,socp.name
,soc.object_id
,scc.name
,soc.name
,socc.name
,CONVERT(VARCHAR(MAX), f.Hierarchy + ' --> ' + scp.name + '.' + sop.name ) as Hierarchy
,f.level+1 as level
,rnk=f.rnk + '-' + convert(varchar(max),sop.object_id)
FROM SYS.foreign_key_columns sfc
JOIN Sys.Objects sop
ON sfc.parent_object_id = sop.object_id
JOIN SYS.columns socp
ON socp.object_id = sop.object_id
AND socp.column_id = sfc.parent_column_id
JOIN sys.schemas scp
ON sop.schema_id = scp.schema_id
JOIN SYS.objects soc
ON sfc.referenced_object_id = soc.object_id
JOIN SYS.columns socc
ON socc.object_id = soc.object_id
AND socc.column_id = sfc.referenced_column_id
JOIN sys.schemas scc
ON soc.schema_id = scc.schema_id
JOIN fkey f
ON f.ReferencingObjectid = sfc.referenced_object_id
WHERE ISNULL(f.PrimarykeyObjectid,0) <> f.ReferencingObjectid
)
INSERT INTO @fkeytbl
(ReferencingObjectid,ReferencingSchemaname,ReferencingTablename,ReferencingColumnname
,PrimarykeyObjectid,PrimarykeySchemaname,PrimarykeyTablename,PrimarykeyColumnname,Hierarchy,level,rnk)
SELECT ReferencingObjectid,ReferencingSchemaname,ReferencingTablename,ReferencingColumnname
,PrimarykeyObjectid,PrimarykeySchemaname,PrimarykeyTablename,PrimarykeyColumnname,Hierarchy,level,rnk
FROM fkey
SELECT F.Relationshiptree
FROM
(
SELECT DISTINCT Replicate('------',Level) + CASE LEVEL WHEN 0 THEN '' ELSE '>' END + ReferencingSchemaname + '.' + ReferencingTablename 'Relationshiptree'
,RNK
FROM @fkeytbl
) F
ORDER BY F.rnk ASC
-------------------------------------------------------------------------------------------------------------------------------
-- Generate the Delete / Select script
-------------------------------------------------------------------------------------------------------------------------------
DECLARE @Sql VARCHAR(MAX)
DECLARE @RnkSql VARCHAR(MAX)
DECLARE @Jointables TABLE
(
ID INT IDENTITY
,Object_id int
)
DECLARE @ProcessTablename SYSNAME
DECLARE @ProcessSchemaName SYSNAME
DECLARE @JoinConditionSQL VARCHAR(MAX)
DECLARE @Rnk VARCHAR(MAX)
DECLARE @OldTablename SYSNAME
IF @GenerateDeleteScripts = 1 or @GenerateSelectScripts = 1
BEGIN
WHILE EXISTS ( SELECT 1
FROM @fkeytbl
WHERE Processed = 0
AND level > 0 )
BEGIN
SELECT @ProcessTablename = ''
SELECT @Sql = ''
SELECT @JoinConditionSQL = ''
SELECT @OldTablename = ''
SELECT TOP 1 @ProcessTablename = ReferencingTablename
,@ProcessSchemaName = ReferencingSchemaname
,@Rnk = RNK
FROM @fkeytbl
WHERE Processed = 0
AND level > 0
ORDER BY level DESC
SELECT @RnkSql ='SELECT ' + REPLACE (@rnk,'-',' UNION ALL SELECT ')
DELETE FROM @Jointables
INSERT INTO @Jointables
EXEC(@RnkSql)
IF @GenerateDeleteScripts = 1
SELECT @Sql = 'DELETE [' + @ProcessSchemaName + '].[' + @ProcessTablename + ']' + CHAR(10) + ' FROM [' + @ProcessSchemaName + '].[' + @ProcessTablename + ']' + CHAR(10)
IF @GenerateSelectScripts = 1
SELECT @Sql = 'SELECT [' + @ProcessSchemaName + '].[' + @ProcessTablename + '].*' + CHAR(10) + ' FROM [' + @ProcessSchemaName + '].[' + @ProcessTablename + ']' + CHAR(10)
SELECT @JoinConditionSQL = @JoinConditionSQL
+ CASE
WHEN @OldTablename <> f.PrimarykeyTablename THEN 'JOIN [' + f.PrimarykeySchemaname + '].[' + f.PrimarykeyTablename + '] ' + CHAR(10) + ' ON '
ELSE ' AND '
END
+ ' [' + f.PrimarykeySchemaname + '].[' + f.PrimarykeyTablename + '].[' + f.PrimarykeyColumnname + '] = [' + f.ReferencingSchemaname + '].[' + f.ReferencingTablename + '].[' + f.ReferencingColumnname + ']' + CHAR(10)
, @OldTablename = CASE
WHEN @OldTablename <> f.PrimarykeyTablename THEN f.PrimarykeyTablename
ELSE @OldTablename
END
FROM @fkeytbl f
JOIN @Jointables j
ON f.Referencingobjectid = j.Object_id
WHERE charindex(f.rnk + '-',@Rnk + '-') <> 0
AND F.level > 0
ORDER BY J.ID DESC
SELECT @Sql = @Sql + @JoinConditionSQL
IF LTRIM(RTRIM(@WhereClause)) <> ''
SELECT @Sql = @Sql + ' WHERE (' + @WhereClause + ')'
PRINT @SQL
PRINT CHAR(10)
UPDATE @fkeytbl
SET Processed = 1
WHERE ReferencingTablename = @ProcessTablename
AND rnk = @Rnk
END
IF @GenerateDeleteScripts = 1
SELECT @Sql = 'DELETE FROM [' + @Schemaname + '].[' + @Tablename + ']'
IF @GenerateSelectScripts = 1
SELECT @Sql = 'SELECT * FROM [' + @Schemaname + '].[' + @Tablename + ']'
IF LTRIM(RTRIM(@WhereClause)) <> ''
SELECT @Sql = @Sql + ' WHERE ' + @WhereClause
PRINT @SQL
END
SET NOCOUNT OFF
go
Для просмотра связей между таблицами в SQL можно использовать системную таблицу INFORMATION_SCHEMA. INFORMATION_SCHEMA содержит метаданные о базе данных, включая информацию о таблицах, столбцах и связях.
Чтобы просмотреть связи между таблицами, можно использовать запрос следующего вида:
SELECT
tc.constraint_name,
tc.table_name,
kcu.column_name,
ccu.table_name AS foreign_table_name,
ccu.column_name AS foreign_column_name
FROM
information_schema.table_constraints AS tc
JOIN information_schema.key_column_usage AS kcu
ON tc.constraint_name = kcu.constraint_name
AND tc.table_schema = kcu.table_schema
JOIN information_schema.constraint_column_usage AS ccu
ON ccu.constraint_name = tc.constraint_name
AND ccu.table_schema = tc.table_schema
WHERE tc.constraint_type = 'FOREIGN KEY' AND tc.table_name='имя_таблицы';
Здесь имя_таблицы – это имя таблицы, связи которой вы хотите просмотреть.
Этот запрос вернет список всех внешних ключей в таблице, включая имя ключа, имя таблицы, столбец таблицы, связанный с внешним ключом, имя таблицы, связанной с внешним ключом, и соответствующий столбец в этой таблице. Эти данные могут помочь вам понять, как связаны различные таблицы в вашей базе данных.
Связи между таблицами базы данных
Время на прочтение
9 мин
Количество просмотров 431K
1. Введение
Связи — это довольна важная тема, которую следует понимать при проектировании баз данных. По своему личному опыту скажу, что осознав связи, мне намного легче далось понимание нормализации базы данных.
1.1. Для кого эта статья?
Эта статья будет полезна тем, кто хочет разобраться со связями между таблицами базы данных. В ней я постарался рассказать на понятном языке, что это такое. Для лучшего понимания темы, я чередую теоретический материал с практическими примерами, представленными в виде диаграммы и запроса, создающего нужные нам таблицы. Я использую СУБД Microsoft SQL Server и запросы пишу на T-SQL. Написанный мною код должен работать и на других СУБД, поскольку запросы являются универсальными и не используют специфических конструкций языка T-SQL.
1.2. Как вы можете применить эти знания?
- Процесс создания баз данных станет для вас легче и понятнее.
- Понимание связей между таблицами поможет вам легче освоить нормализацию, что является очень важным при проектировании базы данных.
- Разобраться с чужой базой данных будет значительно проще.
- На собеседовании это будет очень хорошим плюсом.
2. Благодарности
Учтены были советы и критика авторов jobgemws, unfilled, firnind, Hamaruba.
Спасибо!
3.1. Как организовываются связи?
Связи создаются с помощью внешних ключей (foreign key).
Внешний ключ — это атрибут или набор атрибутов, которые ссылаются на primary key или unique другой таблицы. Другими словами, это что-то вроде указателя на строку другой таблицы.
3.2. Виды связей
Связи делятся на:
- Многие ко многим.
- Один ко многим.
- с обязательной связью;
- с необязательной связью;
- Один к одному.
- с обязательной связью;
- с необязательной связью;
Рассмотрим подробно каждый из них.
4. Многие ко многим
Представим, что нам нужно написать БД, которая будет хранить работником IT-компании. При этом существует некий стандартный набор должностей. При этом:
- Работник может иметь одну и более должностей. Например, некий работник может быть и админом, и программистом.
- Должность может «владеть» одним и более работников. Например, админами является определенный набор работников. Другими словами, к админам относятся некие работники.
Работников представляет таблица «Employee» (id, имя, возраст), должности представляет таблица «Position» (id и название должности). Как видно, обе эти таблицы связаны между собой по правилу многие ко многим: каждому работнику соответствует одна и больше должностей (многие должности), каждой должности соответствует один и больше работников (многие работники).
4.1. Как построить такие таблицы?
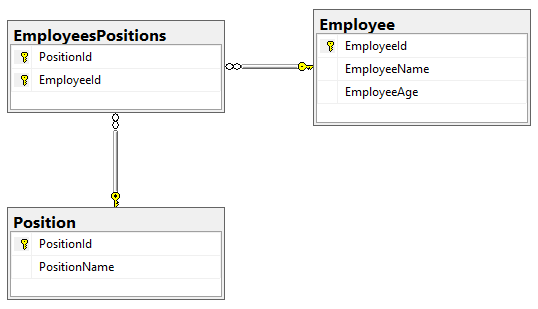
Мы уже имеем две таблицы, описывающие работника и профессию. Теперь нам нужно установить между ними связь многие ко многим. Для реализации такой связи нам нужен некий посредник между таблицами «Employee» и «Position». В нашем случае это будет некая таблица «EmployeesPositions» (работники и должности). Эта таблица-посредник связывает между собой работника и должность следующим образом:
Слева указаны работники (их id), справа — должности (их id). Работники и должности на этой таблице указываются с помощью id’шников.
На эту таблицу можно посмотреть с двух сторон:
- Таким образом, мы говорим, что работник с id 1 находится на должность с id 1. При этом обратите внимание на то, что в этой таблице работник с id 1 имеет две должности: 1 и 2. Т.е., каждому работнику слева соответствует некая должность справа.
- Мы также можем сказать, что должности с id 3 принадлежат пользователи с id 2 и 3. Т.е., каждой роли справа принадлежит некий работник слева.
4.2. Реализация
Диаграмма
Код на T-SQL
create table dbo.Employee
(
EmployeeId int primary key,
EmployeeName nvarchar(128) not null,
EmployeeAge int not null
)
-- Заполним таблицу Employee данными.
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (1, N'John Smith', 22)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (2, N'Hilary White', 22)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (3, N'Emily Brown', 22)
create table dbo.Position
(
PositionId int primary key,
PositionName nvarchar(64) not null
)
-- Заполним таблицу Position данными.
insert into dbo.Position(PositionId, PositionName) values(1, N'IT-director')
insert into dbo.Position(PositionId, PositionName) values(2, N'Programmer')
insert into dbo.Position(PositionId, PositionName) values(3, N'Engineer')
-- Заполним таблицу EmployeesPositions данными.
create table dbo.EmployeesPositions
(
PositionId int foreign key references dbo.Position(PositionId),
EmployeeId int foreign key references dbo.Employee(EmployeeId),
primary key(PositionId, EmployeeId)
)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (1, 1)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (1, 2)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (2, 3)
insert into dbo.EmployeesPositions(EmployeeId, PositionId) values (3, 3)
Объяснения
С помощью ограничения foreign key мы можем ссылаться на primary key или unique другой таблицы. В этом примере мы
- ссылаемся атрибутом PositionId таблицы EmployeesPositions на атрибут PositionId таблицы Position;
- атрибутом EmployeeId таблицы EmployeesPositions — на атрибут EmployeeId таблицы Employee;
4.3. Вывод
Для реализации связи многие ко многим нам нужен некий посредник между двумя рассматриваемыми таблицами. Он должен хранить два внешних ключа, первый из которых ссылается на первую таблицу, а второй — на вторую.
5. Один ко многим
Эта самая распространенная связь между базами данных. Мы рассматриваем ее после связи многие ко многим для сравнения.
Предположим, нам нужно реализовать некую БД, которая ведет учет данных о пользователях. У пользователя есть: имя, фамилия, возраст, номера телефонов. При этом у каждого пользователя может быть от одного и больше номеров телефонов (многие номера телефонов).
В этом случае мы наблюдаем следующее: пользователь может иметь многие номера телефонов, но нельзя сказать, что номеру телефона принадлежит определенный пользователь.
Другими словами, телефон принадлежит только одному пользователю. А пользователю могут принадлежать 1 и более телефонов (многие).
Как мы видим, это отношение один ко многим.
5.1. Как построить такие таблицы?
Пользователей будет представлять некая таблица «Person» (id, имя, фамилия, возраст), номера телефонов будет представлять таблица «Phone». Она будет выглядеть так:
Данная таблица представляет три номера телефона. При этом номера телефона с id 1 и 2 принадлежат пользователю с id 5. А вот номер с id 3 принадлежит пользователю с id 17.
Заметка
. Если бы у таблицы «Phones» было бы больше атрибутов, то мы смело бы их добавляли в эту таблицу.
5.2. Почему мы не делаем тут таблицу-посредника?
Таблица-посредник нужна только в том случае, если мы имеем связь многие-ко-многим. По той простой причине, что мы можем рассматривать ее с двух сторон. Как, например, таблицу EmployeesPositions ранее:
- Каждому работнику принадлежат несколько должностей (многие).
- Каждой должности принадлежит несколько работников (многие).
Но в нашем случае мы не можем сказать, что каждому телефону принадлежат несколько пользователей — номеру телефона может принадлежать только один пользователь.
Теперь прочтите еще раз заметку в конце пункта 5.1. — она станет для вас более понятной.
5.3. Реализация
Диаграмма

Код на T-SQL
create table dbo.Person
(
PersonId int primary key,
FirstName nvarchar(64) not null,
LastName nvarchar(64) not null,
PersonAge int not null
)
insert into dbo.Person(PersonId, FirstName, LastName, PersonAge) values (5, N'John', N'Doe', 25)
insert into dbo.Person(PersonId, FirstName, LastName, PersonAge) values (17, N'Izabella', N'MacMillan', 19)
create table dbo.Phone
(
PhoneId int primary key,
PersonId int foreign key references dbo.Person(PersonId),
PhoneNumber varchar(64) not null
)
insert into dbo.Phone(PhoneId, PersonId, PhoneNumber) values (1, 5, '11 091-10')
insert into dbo.Phone(PhoneId, PersonId, PhoneNumber) values (2, 5, '19 124-66')
insert into dbo.Phone(PhoneId, PersonId, PhoneNumber) values (3, 17, '21 972-02')
Объяснения
Наша таблица Phone хранит всего один внешний ключ. Он ссылается на некого пользователя (на строку из таблицы Person). Таким образом, мы как бы говорим: «этот пользователь является владельцем данного телефона». Другими словами, телефон знает id своего владельца.
6. Один к одному
Представим, что на работе вам дали задание написать БД для учета всех работников для HR. Начальник уверял, что компании нужно знать только об имени, возрасте и телефоне работника. Вы разработали такую БД и поместили в нее всю 1000 работников компании. И тут начальник говорит, что им зачем-то нужно знать о том, является ли работник инвалидом или нет. Наиболее простое, что приходит в голову — это добавить новый столбец типа bool в вашу таблицу. Но это слишком долго вписывать 1000 значений и ведь true вы будете вписывать намного реже, чем false (2% будут true, например).
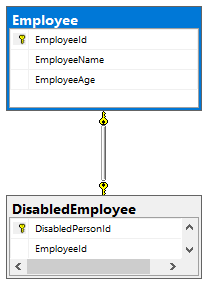
Более простым решением будет создать новую таблицу, назовем ее «DisabledEmployee». Она будет выглядеть так:
Но это еще не связь один к одному. Дело в том, что в такую таблицу работник может быть вписан более одного раза, соответственно, мы получили отношение один ко многим: работник может быть несколько раз инвалидом. Нужно сделать так, чтобы работник мог быть вписан в таблицу только один раз, соответственно, мог быть инвалидом только один раз. Для этого нам нужно указать, что столбец EmployeeId может хранить только уникальные значения. Нам нужно просто наложить на столбец EmloyeeId ограничение unique. Это ограничение сообщает, что атрибут может принимать
только
уникальные значения.
Выполнив это мы получили связь один к одному.
Заметка
. Обратите внимание на то, что мы могли также наложить на атрибут EmloyeeId ограничение primary key. Оно отличается от ограничения unique лишь тем, что не может принимать значения null.
6.1. Вывод
Можно сказать, что отношение один к одному — это разделение одной и той же таблицы на две.
6.2. Реализация
Диаграмма
Код на T-SQL
create table dbo.Employee
(
EmployeeId int primary key,
EmployeeName nvarchar(128) not null,
EmployeeAge int not null
)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (159, N'John Smith', 22)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (722, N'Hilary White', 29)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (937, N'Emily Brown', 19)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (100, N'Frederic Miller', 16)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (99, N'Henry Lorens', 20)
insert into dbo.Employee(EmployeeId, EmployeeName, EmployeeAge) values (189, N'Bob Red', 25)
create table dbo.DisabledEmployee
(
DisabledPersonId int primary key,
EmployeeId int unique foreign key references dbo.Employee(EmployeeId)
)
insert into dbo.DisabledEmployee(DisabledPersonId, EmployeeId) values (1, 159)
insert into dbo.DisabledEmployee(DisabledPersonId, EmployeeId) values (2, 722)
insert into dbo.DisabledEmployee(DisabledPersonId, EmployeeId) values (3, 937)
Объяснения
Таблица DisabledEmployee имеет атрибут EmployeeId, что является внешним ключом. Он ссылается на атрибут EmployeeId таблицы Employee. Кроме того, этот атрибут имеет ограничение unique, что говорит о том, что в него могут быть записаны только уникальные значения. Соответственно, работник может быть записан в эту таблицу не более одного раза.
7. Обязательные и необязательные связи
Связи можно поделить на обязательные и необязательные.
7.1. Один ко многим
- Один ко многим с обязательной связью:
К одному полку относятся многие бойцы. Один боец относится только к одному полку. Обратите внимание, что любой солдат обязательно принадлежит к одному полку, а полк не может существовать без солдат. - Один ко многим с необязательной связью:
На планете Земля живут все люди. Каждый человек живет только на Земле. При этом планета может существовать и без человечества. Соответственно, нахождение нас на Земле не является обязательным
Одну и ту же связь можно рассматривать как обязательную и как необязательную. Рассмотрим вот такой пример:
У одной биологической матери может быть много детей. У ребенка есть только одна биологическая мать.
А) У женщины необязательно есть свои дети. Соответственно, связь необязательна.
Б) У ребенка обязательно есть только одна биологическая мать – в таком случае, связь обязательна.
7.2. Один к одному
- Один к одному с обязательной связью:
У одного гражданина определенной страны обязательно есть только один паспорт этой страны. У одного паспорта есть только один владелец. - Один к одному с необязательной связью:
У одной страны может быть только одна конституция. Одна конституция принадлежит только одной стране. Но конституция не является обязательной. У страны она может быть, а может и не быть, как, например, у Израиля и Великобритании.
Одну и ту же связь можно рассматривать как обязательную и как необязательную:
У одного человека может быть только один загранпаспорт. У одного загранпаспорта есть только один владелец.
А) Наличие загранпаспорта необязательно – его может и не быть у гражданина. Это необязательная связь.
Б) У загранпаспорта обязательно есть только один владелец. В этом случае, это уже обязательная связь.
7.3. Многие ко многим
Любая связь многие ко многим является необязательной. Например:
Человек может инвестировать в акции разных компаний (многих). Инвесторами какой-то компании являются определенные люди (многие).
А) Человек может вообще не инвестировать свои деньги в акции.
Б) Акции компании мог никто не купить.
8. Как читать диаграммы?
Выше я приводил диаграммы созданных нами таблиц. Но для того, чтобы их понимать, нужно знать, как их «читать». Разберемся в этом на примере диаграммы из пункта 5.3.
Мы видим отношение один ко многим. Одной персоне принадлежит много телефонов.
- Возле таблицы Person находится золотой ключик. Он обозначает слово «один».
- Возле таблицы Phone находится знак бесконечности. Он обозначает слово «многие».
9. Итоги
- Связи бывают:
- Многие ко многим.
- Один ко многим.
1) с обязательной связью;
2) с необязательной связью. - Один к одному.
1) с обязательной связью;
2) с необязательной связью.
- Связи организовываются с помощью внешних ключей.
- Foreign key (внешний ключ) — это атрибут или набор атрибутов, которые ссылаются на primary key или unique другой таблицы. Другими словами, это что-то вроде указателя на строку другой таблицы.
10. Задачи
Для лучшего усвоения материала предлагаю вам решить следующие задачи:
- Описать таблицу фильм: id, название, длительность, режиссер, жанр фильма. Обратите внимание на то, что у фильма может быть более одного жанра, а к одному жанру может относится более, чем один фильм.
- Описать таблицу песня: id, название, длительность, певец. При этом у песни может быть более одного певца, а певец мог записать более одной песни.
- Реализовать таблицу машина: модель, производитель, цвет, цена
- Описать отдельную таблицу производитель: id, название, рейтинг.
- Описать отдельную таблицу цвета: id, название.
У одной машины может быть только один производитель, а у производителя — много машин. У одной машины может быть много цветов, а у одного цвета может быть много машин.
- Добавить в БД из пункта 6.2. таблицу военно-обязанных по типу того, как мы описали отдельную таблицу DisabledEmployee.
SQL Server Management Studio is decent tool but far from perfect if you want to discover database schema. Here I want to show you a few ways to find table foreign keys.
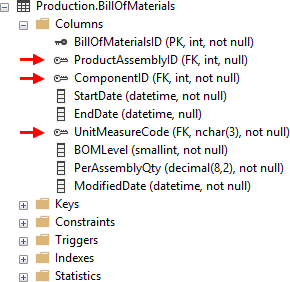
Option 1: View table columns
In SSMS you can see which columns are foreign keys in Columns list under the table in Object Explorer. FKs have a gray/light key icon (depending on SSMS version).
This option doesn’t enable you to see the table FK references.
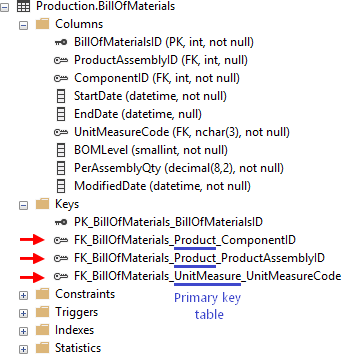
Option 2: View table keys
You can also see the list of foreign keys in Keys folder under the table.
With this option, if the naming is right, you see referenced table but usually not which column has a foreign key.
Names of FKs
SSMS by default names new foreign keys in following way:
- FK_Mytable_Othertable
where Mytable is a table that holds foreign key and Othertable is the primary key table.
Note: This is not always true though. DBAs/architects or other tools can name keys differently
Option 3: Designer
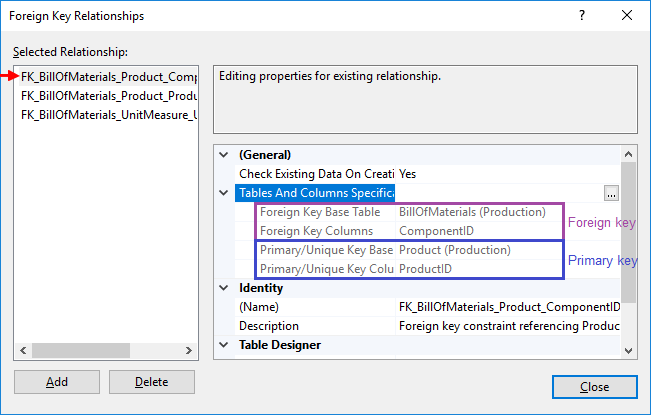
You can see all the details of foreign key in table designer.
Please be careful not to change anything and save. You can open key definition in one of two ways:
Option 1: select key → right click → Modify
Option 1: select table → right click → Design → Relationships icon in toolbar or right click and choose Relationships → select key in Selected Relationship list on the left
When you select the right key on the left expand Tables And Columns Specification option in the right panel. There are 4 fields defining foreign key – foreign and primary key tables and columns.
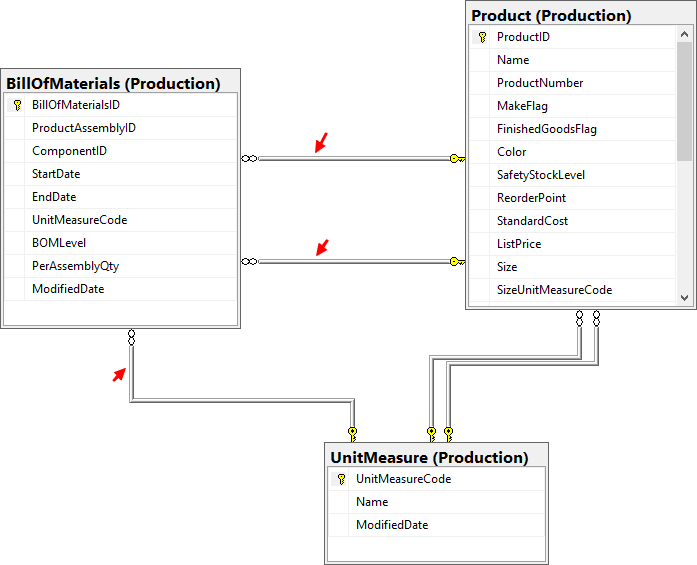
Option 4: Diagrams
Another way to see table foreign keys is to create diagram, add table and their related tables. Links will show you existing foreign keys.
See complete tutorial on diagrams in SSMS or use this simplified guide:
- Create new diagram in Diagrams folder under database
- Click Add table… and choose your table
- Right click table and chose Add Related Tables
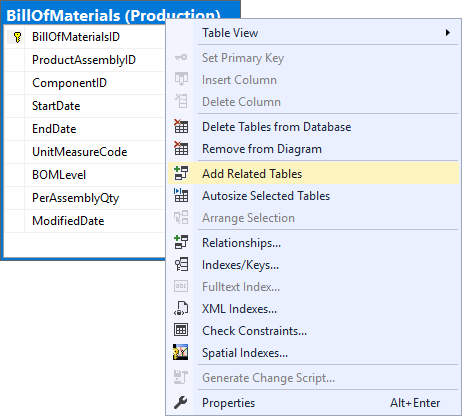
Arrange diagram and relationships will be visible as links from your table to the other tables.
Bonus 1: SQL query
You can also query system catalog with an SQL to list foreign keys. In our query database we have one that would return this:
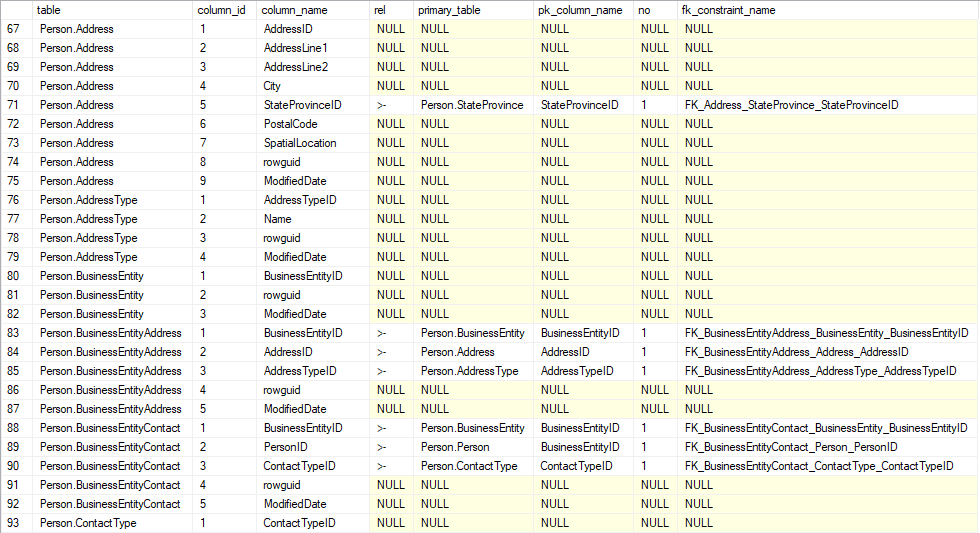
Get a query (and many more)
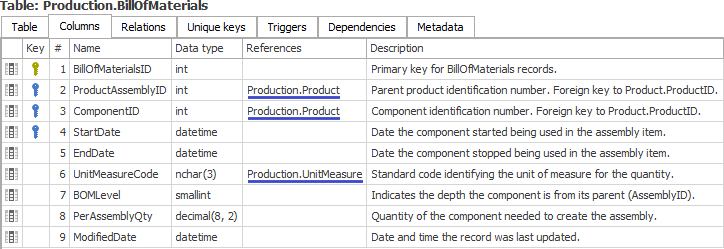
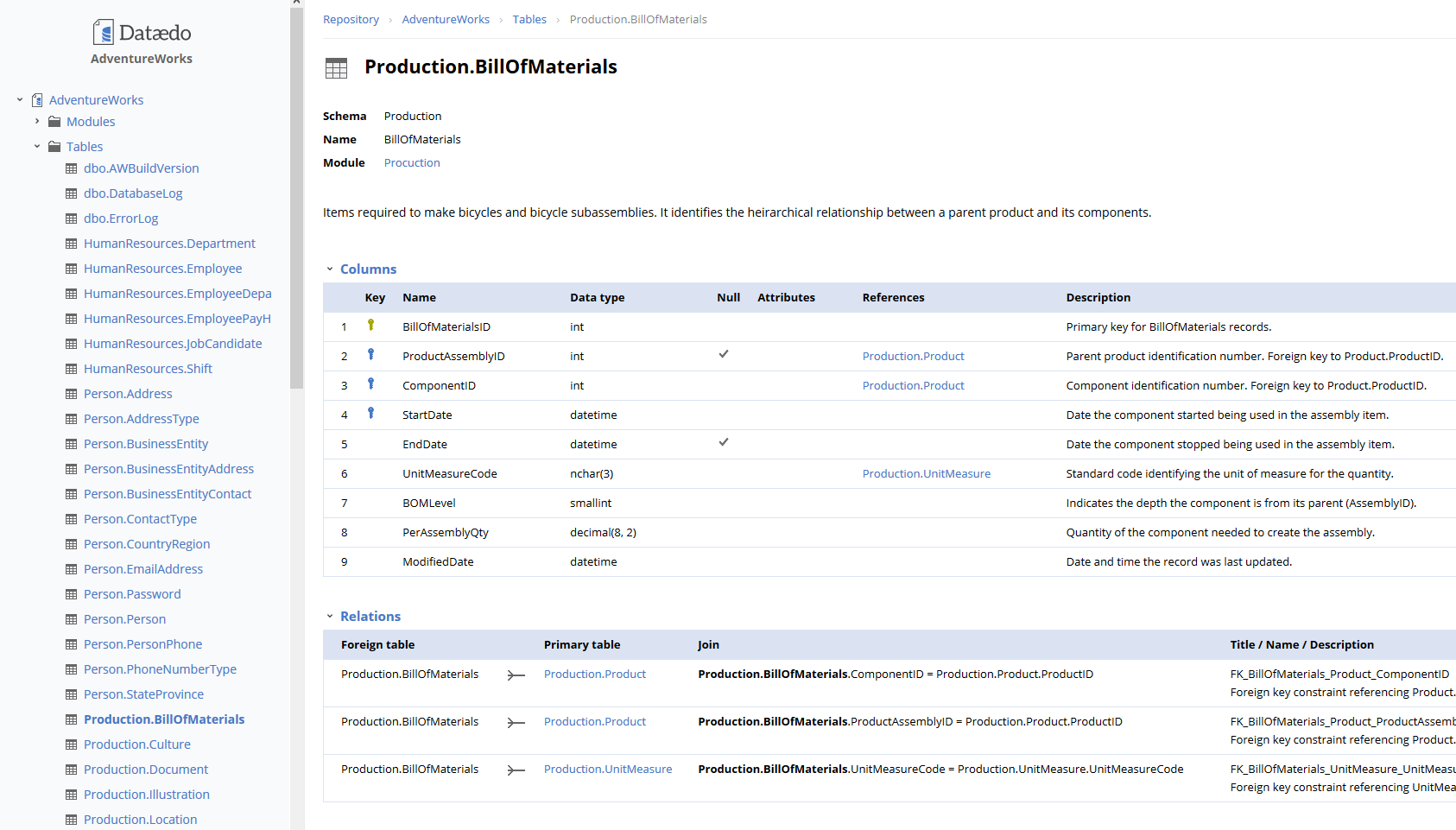
Bonus 2: Dataedo
You can also use tool called Dataedo to import your schema and view relationships in UI or HTML as shown below:
View live sample
Other benefits besides better view of FKs is
- to be able to define table and view relationships where there are no FK constraints in the database,
- describe each schema element,
- store metadata in global repository and easily share with your team in HTML
- and much more.
Try it for free now
Просмотр зависимостей таблицы
Зависимости таблицы в SQL Server можно просмотреть в среде SQL Server Management Studio или с помощью Transact-SQL.
В этом разделе
Перед началом работы
Просмотр зависимостей таблицы с помощью следующих средств:
Перед началом
безопасность
Permissions
Необходимо разрешение VIEW DEFINITION в базе данных и разрешение SELECT на представление sys.sql_expression_dependencies в базе данных. По умолчанию разрешение SELECT предоставляется только членам предопределенной роли базы данных db_owner. Если разрешения SELECT и VIEW DEFINITION предоставлены другому пользователю, он может просматривать все зависимости в базе данных.
Использование среды SQL Server Management Studio
Просмотр объектов, от которых зависит таблица
В Обозревателе объектов разверните узел Базы данных, разверните саму базу данных, а затем разверните узел Таблицы.
Щелкните таблицу правой кнопкой мыши и выберите Просмотр зависимостей.
В диалоговом окне Зависимости объектов <object name> выберите либо вариант Объекты, которые зависят от <object name> , либо вариант Объекты, от которых зависит <object name> .
Выберите объект в сетке Зависимости . Тип объекта (например, “Триггер” или “Хранимая процедура”) появится в поле Тип .
Использование Transact-SQL
Просмотр объектов, зависящих от таблицы
В обозревателе объектов подключитесь к экземпляру компонента Компонент Database Engine.
На стандартной панели выберите пункт Создать запрос.
Скопируйте следующий пример в окно запроса и нажмите кнопку Выполнить.
Просмотр зависимостей таблицы
В обозревателе объектов подключитесь к экземпляру компонента Компонент Database Engine.
Связи между таблицами базы данных
Связи — это довольна важная тема, которую следует понимать при проектировании баз данных. По своему личному опыту скажу, что осознав связи, мне намного легче далось понимание нормализации базы данных.
1.1. Для кого эта статья?
Эта статья будет полезна тем, кто хочет разобраться со связями между таблицами базы данных. В ней я постарался рассказать на понятном языке, что это такое. Для лучшего понимания темы, я чередую теоретический материал с практическими примерами, представленными в виде диаграммы и запроса, создающего нужные нам таблицы. Я использую СУБД Microsoft SQL Server и запросы пишу на T-SQL. Написанный мною код должен работать и на других СУБД, поскольку запросы являются универсальными и не используют специфических конструкций языка T-SQL.
1.2. Как вы можете применить эти знания?
- Процесс создания баз данных станет для вас легче и понятнее.
- Понимание связей между таблицами поможет вам легче освоить нормализацию, что является очень важным при проектировании базы данных.
- Разобраться с чужой базой данных будет значительно проще.
- На собеседовании это будет очень хорошим плюсом.
2. Благодарности
Учтены были советы и критика авторов jobgemws, unfilled, firnind, Hamaruba.
Спасибо!
3.1. Как организовываются связи?
Связи создаются с помощью внешних ключей (foreign key).
Внешний ключ — это атрибут или набор атрибутов, которые ссылаются на primary key или unique другой таблицы. Другими словами, это что-то вроде указателя на строку другой таблицы.
3.2. Виды связей
Связи делятся на:
- Многие ко многим.
- Один ко многим.
- с обязательной связью;
- с необязательной связью;
- Один к одному.
- с обязательной связью;
- с необязательной связью;
4. Многие ко многим
Представим, что нам нужно написать БД, которая будет хранить работником IT-компании. При этом существует некий стандартный набор должностей. При этом:
- Работник может иметь одну и более должностей. Например, некий работник может быть и админом, и программистом.
- Должность может «владеть» одним и более работников. Например, админами является определенный набор работников. Другими словами, к админам относятся некие работники.
4.1. Как построить такие таблицы?
| EmployeeId | PositionId |
|---|---|
| 1 | 1 |
| 1 | 2 |
| 2 | 3 |
| 3 | 3 |
Слева указаны работники (их id), справа — должности (их id). Работники и должности на этой таблице указываются с помощью id’шников.
На эту таблицу можно посмотреть с двух сторон:
- Таким образом, мы говорим, что работник с id 1 находится на должность с id 1. При этом обратите внимание на то, что в этой таблице работник с id 1 имеет две должности: 1 и 2. Т.е., каждому работнику слева соответствует некая должность справа.
- Мы также можем сказать, что должности с id 3 принадлежат пользователи с id 2 и 3. Т.е., каждой роли справа принадлежит некий работник слева.
4.2. Реализация
С помощью ограничения foreign key мы можем ссылаться на primary key или unique другой таблицы. В этом примере мы
- ссылаемся атрибутом PositionId таблицы EmployeesPositions на атрибут PositionId таблицы Position;
- атрибутом EmployeeId таблицы EmployeesPositions — на атрибут EmployeeId таблицы Employee;
4.3. Вывод
Для реализации связи многие ко многим нам нужен некий посредник между двумя рассматриваемыми таблицами. Он должен хранить два внешних ключа, первый из которых ссылается на первую таблицу, а второй — на вторую.
5. Один ко многим
Эта самая распространенная связь между базами данных. Мы рассматриваем ее после связи многие ко многим для сравнения.
Предположим, нам нужно реализовать некую БД, которая ведет учет данных о пользователях. У пользователя есть: имя, фамилия, возраст, номера телефонов. При этом у каждого пользователя может быть от одного и больше номеров телефонов (многие номера телефонов).
В этом случае мы наблюдаем следующее: пользователь может иметь многие номера телефонов, но нельзя сказать, что номеру телефона принадлежит определенный пользователь.
Другими словами, телефон принадлежит только одному пользователю. А пользователю могут принадлежать 1 и более телефонов (многие).
Как мы видим, это отношение один ко многим.
5.1. Как построить такие таблицы?
| PhoneId | PersonId | PhoneNumber |
|---|---|---|
| 1 | 5 | 11 091-10 |
| 2 | 5 | 19 124-66 |
| 3 | 17 | 21 972-02 |
Данная таблица представляет три номера телефона. При этом номера телефона с id 1 и 2 принадлежат пользователю с id 5. А вот номер с id 3 принадлежит пользователю с id 17.
Заметка. Если бы у таблицы «Phones» было бы больше атрибутов, то мы смело бы их добавляли в эту таблицу.
5.2. Почему мы не делаем тут таблицу-посредника?
Таблица-посредник нужна только в том случае, если мы имеем связь многие-ко-многим. По той простой причине, что мы можем рассматривать ее с двух сторон. Как, например, таблицу EmployeesPositions ранее:
- Каждому работнику принадлежат несколько должностей (многие).
- Каждой должности принадлежит несколько работников (многие).
5.3. Реализация
6. Один к одному
Представим, что на работе вам дали задание написать БД для учета всех работников для HR. Начальник уверял, что компании нужно знать только об имени, возрасте и телефоне работника. Вы разработали такую БД и поместили в нее всю 1000 работников компании. И тут начальник говорит, что им зачем-то нужно знать о том, является ли работник инвалидом или нет. Наиболее простое, что приходит в голову — это добавить новый столбец типа bool в вашу таблицу. Но это слишком долго вписывать 1000 значений и ведь true вы будете вписывать намного реже, чем false (2% будут true, например).
Более простым решением будет создать новую таблицу, назовем ее «DisabledEmployee». Она будет выглядеть так:
| DisabledPersonId | EmployeeId |
|---|---|
| 1 | 159 |
| 2 | 722 |
| 3 | 937 |
Но это еще не связь один к одному. Дело в том, что в такую таблицу работник может быть вписан более одного раза, соответственно, мы получили отношение один ко многим: работник может быть несколько раз инвалидом. Нужно сделать так, чтобы работник мог быть вписан в таблицу только один раз, соответственно, мог быть инвалидом только один раз. Для этого нам нужно указать, что столбец EmployeeId может хранить только уникальные значения. Нам нужно просто наложить на столбец EmloyeeId ограничение unique. Это ограничение сообщает, что атрибут может принимать только уникальные значения.
Выполнив это мы получили связь один к одному.
Заметка. Обратите внимание на то, что мы могли также наложить на атрибут EmloyeeId ограничение primary key. Оно отличается от ограничения unique лишь тем, что не может принимать значения null.
6.1. Вывод
Можно сказать, что отношение один к одному — это разделение одной и той же таблицы на две.
6.2. Реализация
7. Обязательные и необязательные связи
Связи можно поделить на обязательные и необязательные.
7.1. Один ко многим
- Один ко многим с обязательной связью:
К одному полку относятся многие бойцы. Один боец относится только к одному полку. Обратите внимание, что любой солдат обязательно принадлежит к одному полку, а полк не может существовать без солдат. - Один ко многим с необязательной связью:
На планете Земля живут все люди. Каждый человек живет только на Земле. При этом планета может существовать и без человечества. Соответственно, нахождение нас на Земле не является обязательным
А) У женщины необязательно есть свои дети. Соответственно, связь необязательна.
Б) У ребенка обязательно есть только одна биологическая мать – в таком случае, связь обязательна.
7.2. Один к одному
- Один к одному с обязательной связью:
У одного гражданина определенной страны обязательно есть только один паспорт этой страны. У одного паспорта есть только один владелец. - Один к одному с необязательной связью:
У одной страны может быть только одна конституция. Одна конституция принадлежит только одной стране. Но конституция не является обязательной. У страны она может быть, а может и не быть, как, например, у Израиля и Великобритании.
А) Наличие загранпаспорта необязательно – его может и не быть у гражданина. Это необязательная связь.
Б) У загранпаспорта обязательно есть только один владелец. В этом случае, это уже обязательная связь.
7.3. Многие ко многим
А) Человек может вообще не инвестировать свои деньги в акции.
Б) Акции компании мог никто не купить.
8. Как читать диаграммы?
Выше я приводил диаграммы созданных нами таблиц. Но для того, чтобы их понимать, нужно знать, как их «читать». Разберемся в этом на примере диаграммы из пункта 5.3.
Мы видим отношение один ко многим. Одной персоне принадлежит много телефонов.
Сегодня мы продолжаем наше путешествие в мир SQL и связанных баз данных. В третьей части этой серии мы узнаем, как работать с несколькими таблицами, которые имеют отношения друг с другом. Во-первых, мы рассмотрим некоторые базовые концепции, а затем начнем работать с JOIN queries в SQL.
Вы также можете увидеть базы данных SQL в действии, просмотрев SQL scripts, apps and add-ons на рынке Envato.
Напоминание
Введение
При создании базы данных здравый смысл подсказывает, что мы используем отдельные таблицы для разных типов сущностей. Например: клиенты, заказы, предметы, сообщения. Но нам также нужно иметь отношения между этими таблицами. Например, клиенты делают заказы, а заказы содержат предметы. Эти отношения должны быть представлены в базе данных. Кроме того, при получении данных с помощью SQL нам нужно использовать определённые типы запросов JOIN, чтобы получить то, что нам нужно.
Существует несколько типов отношений базы данных. Сегодня мы рассмотрим следующее:
- Отношения один к одному
- Отношения «один ко многим» и «многие к одному»
- «Многие ко многим» отношения
- Самостоятельные ссылки
При выборе данных из нескольких таблиц с отношениями мы будем использовать запрос JOIN. Существует несколько типов JOIN, и мы собираемся узнать следующее:
- Перекрестные соединения
- Обычные соединения
- Внутренние соединения
- Левые (внешние) соединения
- Правые (внешние) соединения
Мы также узнаем об оговорках ON и USING.
Отношения один к одному
Предположим, у вас есть таблица для клиентов:


Мы можем поместить информацию об адресе клиента в отдельную таблицу:


Теперь мы имеем отношение между таблицей Customers и таблицей Addresses. Если каждый адрес может принадлежать только одному клиенту, это отношение «Один к одному». Имейте в виду, что такого рода отношения не очень распространены. Наша начальная таблица, которая включала адрес вместе с клиентом, в большинстве случаев могла работать нормально.
Обратите внимание: теперь в таблице Customers есть поле с именем «address_id», которое ссылается на запись соответствия в таблице Address. Это называется «Foreign Key» и используется для всех видов отношений баз данных. Мы рассмотрим этот вопрос позже.
Мы можем показать отношения между клиентскими и адресными записями следующим образом:


Обратите внимание, что существование отношений может быть необязательным, например, есть запись клиента, у которой нет связанной записи адреса.
Отношения «один ко многим» и «многие к одному»
Это наиболее часто используемый тип отношений. Рассмотрим веб-сайт e-commerce со следующим:
- Клиенты могут делать много заказов.
- Заказы могут содержать много позиций.
- Позиции могут иметь описания на многих языках.
В этих случаях нам необходимо создать отношения «один ко многим». Вот пример:

У каждого клиента может быть ноль, один или несколько заказов. Но заказ может принадлежать только одному клиенту.


Отношения «многие ко многим»
В некоторых случаях вам может потребоваться несколько экземпляров с обеих сторон. Например, каждый заказ может содержать несколько элементов. И каждый элемент также может быть в нескольких заказах.
Для этих отношений нам нужно создать дополнительную таблицу:


Таблица Items_Orders имеет только одну цель, а именно, чтобы создать отношение «многие ко многим» между элементами и заказами.
Вот картинка таких отношений:


Если вы хотите включить записи items_orders в график, это может выглядеть так:


Самостоятельные ссылки
Это используется, когда таблица должна иметь отношения с самой собой. Например, у вас есть реферальная программа. Клиенты могут направлять других клиентов на ваш веб-сайт. Таблица может выглядеть так:


Клиенты 102 и 103 были переданы клиентом 101.
На самом деле это может быть похоже на отношение «один ко многим», поскольку один клиент может ссылаться на нескольких клиентов. Также он может выглядеть, как древовидная структура:


Один клиент может ссылаться на ноль, одного или несколько клиентов. К каждому клиенту может обращаться только один клиент, или вообще никто.
Если вы хотите создать самостоятельную ссылку «многие ко многим», вам понадобится дополнительная таблица, вроде той, что мы говорили в предыдущем разделе.
Foreign Keys
До сих пор мы узнали только о некоторых концепциях. Теперь пришло время воплотить их в жизнь с помощью SQL. Для этой части нам нужно понять, что такое Foreign Keys.
В приведённых выше примерах отношений мы всегда имели эти поля «**** _ id», которые ссылались на столбец в другой таблице. В этом примере столбец customer_id в таблице Orders является столбцом Foreign Key:
В базе данных типа MySQL есть два способа создания столбцов внешних ключей:
Чёткое определение Foreign Key
Давайте создадим простую таблицу клиентов:
Теперь таблицу заказов, в которой будет Foreign Key:
Оба столбца (customers.customer_id и orders.customer_id) должны иметь одинаковую структуру данных. Если один является INT, другой не должен быть BIGINT, например.
Обратите внимание, что в MySQL только механизм InnoDB имеет полную поддержку Foreign Keys. Но другие механизмы хранения данных по-прежнему позволят вам указывать их без каких-либо ошибок. Кроме того, столбец Foreign Key индексируется автоматически, если не указать для него другой индекс.
Без явной декларации
Та же таблица заказов может быть создана без явного объявления столбца customer_id как Foreign Key:
При получении данных с помощью запроса JOIN вы всё равно можете рассматривать этот столбец как Foreign Key , хотя механизм базы данных не знает об этом отношении.
Далее мы собираемся узнать о JOIN-запросах.
Визуализация отношений
Моим любимым программным обеспечением для проектирования баз данных и визуализации отношений Foreign Key является MySQL Workbench.


После разработки базы данных вы можете экспортировать SQL и запустить его на своем сервере. Это очень удобно для больших и сложных баз данных.


JOIN Queries
Для извлечения данных из базы, имеющей отношения, нам часто приходится использовать JOIN queries.
Прежде чем начать, давайте создадим таблицы и некоторые образцы данных для работы.
У нас 4 клиента. У одного клиента два заказа, у двух клиентов по одному заказу, а у одного клиента нет заказа. Теперь давайте посмотрим различные виды JOIN queries, которые мы можем запустить в этих таблицах.
Перекрестное соединение
Это тип JOIN query по умолчанию, если условие не указано.


Результатом является так называемый «Cartesian product» таблиц. Это означает, что каждая строка из первой таблицы сопоставляется с каждой строкой второй таблицы. Так как каждая таблица имела 4 строки, мы получили результат из 16 строк.
Ключевое слово JOIN может быть опционально заменено запятой.


Конечно, такой результат не очень полезен. Давайте посмотрим на другие типы соединений.
Обычное соединение
При таком типе JOIN query таблицы должны иметь имя соответствующего столбца. В нашем случае обе таблицы имеют столбец customer_id. Таким образом, MySQL будет присоединяться к записям только тогда, когда значение этого столбца соответствует двум записям.


Как вы можете видеть, столбец customer_id отображается только один раз, потому что ядро базы данных рассматривает это как общий столбец. Мы видим два заказа Адама, а два других — Джо и Сэнди. Наконец, мы получаем некоторую полезную информацию.
Внутреннее соединение
Когда указано условие соединения, выполняется Inner Join. В этом случае было бы неплохо иметь поле customer_id в обеих таблицах. Результаты должны быть похожими на Natural Join.


Результаты те же, за исключением небольшой разницы. Столбец customer_id повторяется дважды, один раз для каждой таблицы. Причина в том, что мы просто попросили базу данных соответствовать значениям этих двух столбцов. Но сами они не знают, что представляют одну и ту же информацию.
Давайте добавим еще несколько условий в запрос.


На этот раз мы получили заказы на сумму более $15.
ON Clause
Прежде чем перейти к другим типам соединений, нам нужно посмотреть ON clause. Это полезно для помещения условий JOIN в отдельное предложение.


Теперь мы можем отличить условие JOIN от условий WHERE. Но есть и небольшая разница в функциональности. Мы увидим это в примерах LEFT JOIN.
USING Clause
USING clause похоже на предложение ON, но оно короче. Если столбец имеет одинаковое имя в обеих таблицах, мы можем указать его здесь.


На самом деле это похоже на NATURAL JOIN, поэтому столбец join (customer_id) не повторяется дважды в результатах.
Левое (внешнее) соединение
LEFT JOIN — это тип внешнего соединения. В этих запросах, если во второй таблице не найдено совпадений, запись из первой таблицы по-прежнему отображается.


Хотя у Энди нет заказов, его запись все ещё отображается. Значения под столбцами второй таблицы имеют значение NULL.
Это полезно для поиска записей, которые не имеют отношений. Например, мы можем искать клиентов, которые не разместили какие-либо заказы.


Всё, что мы сделали, это нашли NULL для order_id.
Также обратите внимание, что ключевое слово OUTER является необязательным. Вы можете просто использовать LEFT JOIN вместо LEFT OUTER JOIN.
Условия
Теперь давайте рассмотрим запрос с условием.


Так что случилось с Энди и Сэнди? LEFT JOIN должен был вернуть клиентов без соответствующих заказов. Проблема в том, что предложение WHERE блокирует эти результаты. Чтобы их получить, мы можем попытаться включить условие NULL.


У нас Энди, но нет Сэнди. Тем не менее это выглядит не так. Чтобы получить то, что мы хотим, нам нужно использовать ON clause.


Теперь у нас есть все, и все заказы выше $ 15. Как я уже говорил, ON clause иногда имеет несколько иную функциональность, чем WHERE clause. В условии Outer Join , таком как этот, строки включаются, даже если они не соответствуют условиям ON clause.
Правое (внешнее) соединение
RIGHT OUTER JOIN работает точно так же, но порядок таблиц обратный.


На этот раз у нас нет результатов NULL, потому что каждый заказ имеет соответствующую запись клиента. Мы можем изменить порядок таблиц и получить те же результаты, что и в LEFT OUTER JOIN.


Теперь у нас есть эти значения NULL, потому что таблица Customers находится на правой стороне соединения.
Заключение
Спасибо, что прочитали статью. Надеюсь, вам понравилось! Пожалуйста, оставляйте свои комментарии и вопросы, и хорошего дня!
Не забудьте проверить SQL scripts, apps and add-ons на рынке Envato. Вы получите представление о возможностях баз данных SQL, и сможете найти идеальное решение, которое поможет вам в текущем проекте разработки.
Следуйте за нами на Twitter или подпишитесь на Nettuts + RSS Feed для получения лучших обучающих материалов по веб-разработке в Интернете.
