
При работе с базой данных SQL вам может понадобиться найти записи, содержащие определенные строки. В этой статье мы разберем, как искать строки и подстроки в MySQL и SQL Server.
Содержание
- Использование операторов WHERE и LIKE для поиска подстроки
- Поиск подстроки в SQL Server с помощью функции CHARINDEX
- Поиск подстроки в SQL Server с помощью функции PATINDEX
- MySQL-запрос для поиска подстроки с применением функции SUBSTRING_INDEX()
Я буду использовать таблицу products_data в базе данных products_schema. Выполнение команды SELECT * FROM products_data покажет мне все записи в таблице:

Поскольку я также буду показывать поиск подстроки в SQL Server, у меня есть таблица products_data в базе данных products:

Поиск подстроки при помощи операторов WHERE и LIKE
Оператор WHERE позволяет получить только те записи, которые удовлетворяют определенному условию. А оператор LIKE позволяет найти определенный шаблон в столбце. Эти два оператора можно комбинировать для поиска строки или подстроки.
Например, объединив WHERE с LIKE, я смог получить все товары, в которых есть слово «computer»:
SELECT * FROM products_data WHERE product_name LIKE '%computer%'

Знаки процента слева и справа от «computer» указывают искать слово «computer» в конце, середине или начале строки.
Если поставить знак процента в начале подстроки, по которой вы ищете, это будет указанием найти такую подстроку, стоящую в конце строки. Например, выполнив следующий запрос, я получил все продукты, которые заканчиваются на «er»:
SELECT * FROM products_data WHERE product_name LIKE '%er'

А если написать знак процента после искомой подстроки, это будет означать, что нужно найти такую подстроку, стоящую в начале строки. Например, я смог получить продукт, начинающийся на «lap», выполнив следующий запрос:
SELECT * FROM products_data WHERE product_name LIKE 'lap%'

Этот метод также отлично работает в SQL Server:

Поиск подстроки в SQL Server с помощью функции CHARINDEX
CHARINDEX() — это функция SQL Server для поиска индекса подстроки в строке.
Функция CHARINDEX() принимает 3 аргумента: подстроку, строку и стартовую позицию для поиска. Синтаксис выглядит следующим образом:
CHARINDEX(substring, string, start_position)
Если функция находит совпадение, она возвращает индекс, по которому найдено совпадение, а если совпадение не найдено, возвращает 0. В отличие от многих других языков, отсчет в SQL начинается с единицы.
Пример:
SELECT CHARINDEX('free', 'free is the watchword of freeCodeCamp') position;

Как видите, слово «free» было найдено на позиции 1. Это потому, что на позиции 1 стоит его первая буква — «f»:

Можно задать поиск с конкретной позиции. Например, если указать в качестве позиции 25, SQL Server найдет совпадение, начиная с текста «freeCodeCamp»:
SELECT CHARINDEX('free', 'free is the watchword of freeCodeCamp', 25);

При помощи CHARINDEX можно найти все продукты, в которых есть слово «computer», выполнив этот запрос:
SELECT * FROM products_data WHERE CHARINDEX('computer', product_name, 0) > 0
Этот запрос диктует следующее: «Начиная с индекса 0 и до тех пор, пока их больше 0, ищи все продукты, названия которых содержат слово «computer», в столбце product_name». Вот результат:

Поиск подстроки в SQL Server с помощью функции PATINDEX
PATINDEX означает «pattern index», т. е. «индекс шаблона». Эта функция позволяет искать подстроку с помощью регулярных выражений.
PATINDEX принимает два аргумента: шаблон и строку. Синтаксис выглядит следующим образом:
PATINDEX(pattern, string)
Если PATINDEX находит совпадение, он возвращает позицию этого совпадения. Если совпадение не найдено, возвращается 0. Вот пример:
SELECT PATINDEX('%ava%', 'JavaScript is a Jack of all trades');

Чтобы применить PATINDEX к таблице, я выполнил следующий запрос:
SELECT product_name, PATINDEX('%ann%', product_name) position
FROM products_data
Но он только перечислил все товары и вернул индекс, под которым нашел совпадение:

Как видите, подстрока «ann» нашлась под индексом 3 продукта Scanner. Но скорее всего вы захотите, чтобы выводился только тот товар, в котором было найдено совпадение с шаблоном.
Чтобы обеспечить такое поведение, можно использовать операторы WHERE и LIKE:
SELECT product_name, PATINDEX('%ann%', product_name) position
FROM products_data
WHERE product_name LIKE '%ann%'

Теперь запрос возвращает то, что нужно.
MySQL-запрос для поиска строки с применением функции SUBSTRING_INDEX()
Помимо решений, которые я уже показал, MySQL имеет встроенную функцию SUBSTRING_INDEX(), с помощью которой можно найти часть строки.
Функция SUBSTRING_INDEX() принимает 3 обязательных аргумента: строку, разделитель и число. Числом обозначается количество вхождений разделителя.
Если вы укажете обязательные аргументы, функция SUBSTRING_INDEX() вернет подстроку до n-го разделителя, где n — указанное число вхождений разделителя. Вот пример:
SELECT SUBSTRING_INDEX("Learn on freeCodeCamp with me", "with", 1);
В этом запросе «Learn on freeCodeCamp with me» — это строка, «with» — разделитель, а 1 — количество вхождений разделителя. В этом случае запрос выдаст вам «Learn on freeCodeCamp»:

Количество вхождений разделителя может быть как положительным, так и отрицательным. Если это отрицательное число, то вы получите часть строки после указанного числа разделителей. Вот пример:
SELECT SUBSTRING_INDEX("Learn on freeCodeCamp with me", "with", -1);

От редакции Techrocks: также предлагаем почитать «Индексы и оптимизация MySQL-запросов».
Заключение
Из этой статьи вы узнали, как найти подстроку в строке в SQL, используя MySQL и SQL Server.
CHARINDEX() и PATINDEX() — это функции, с помощью которых можно найти подстроку в строке в SQL Server. Функция PATINDEX() является более мощной, так как позволяет использовать регулярные выражения.
Поскольку в MySQL нет CHARINDEX() и PATINDEX(), в первом примере мы рассмотрели, как найти подстроку в строке с помощью операторов WHERE и LIKE.
Перевод статьи «SQL Where Contains String – Substring Query Example».

От автора: вы тут запись мою не видели? Выпала из базы, теперь не знаю, что и делать! Наверное, сегодня возьмемся за поиск в MySQL. А я как раз вспомню, как более эффективно просеивать данные в СУБД и заодно свою строку постараюсь найти.
Зачем просеивать?
Просеивание в MySQL – одна из самых часто выполняемых задач. Для этого в системах управления БД, поддерживающих SQL, используется команда SELECT. В предыдущих материалах мы уже сталкивались с ней, применяя ее для нахождения и вывода строк, отвечающих «простеньким» критериям сортировки. На самом деле данная команда является одной из главных, и ее возможности в сфере поиска записей почти безграничны.
При этом написание правильных запросов на выборку данных в MySQL очень часто похоже на составление заклинаний. Особенно такое впечатление складывается у новичков, которые только ступили на путь изучения СУБД. Но сегодня мы постараемся развеять это «сюрреалистическое» наваждение, и научимся составлять правильные запросы для поиска по MySQL базе.
Как уже у нас заведено, начнем с обзора возможностей phpMYAdmin. Посмотрим, каким встроенным функционалом для сортировки данных обладает эта программа.
Просеиваем строки через phpMyAdmin
Зайдите в программу, выберите любую БД и таблицу в ней. Я бы советовал вам использовать таблицу поменьше, в которой всего несколько срок. В них лучше видны результаты сортировки.
Выбрав слева в меню базу и таблицу, перейдите сверху в раздел «Обзор». После этого СУБД выведет все строки, которые содержатся в данной структуре. Для этого программа направила на выполнение серверу БД запрос на выборку. Его код отображается выше результатов выборки.

Ниже находится весь встроенный функционал программы для поиска по MySQL базе. Чтобы установить способ «просеивания» по первичному ключу (по убыванию или возрастанию), используется переключатель «Сортировать по индексу».

Кроме этого можно «просеять» все строки, изменив порядок вывода данных по значению каждого из столбцов (убыванию и возрастанию). Для этого нужно нажать на имя столбца вверху списка. При этом для строковых значений порядок вывода будет изменяться в алфавитном порядке.

Но весь этот функционал пригодится вам только для осуществления поиска в небольших таблицах. Для более внушительных объемов данных придется использовать SQL.
Мощные средства SQL
Как уже упоминалось, для поиска в MySQL используется команда SELECT. Ее синтаксис я приводить не буду, поскольку его размер может испугать даже самого опытного разработчика. Поэтому только на скриншоте, чтобы вы не упали в обморок :).

Будет «постигать» данную команду на примерах ее использования, которые могут пригодиться вам для построения более сложных запросов. Стартуем! Я все-таки опять «поиграюсь» со своими «зверушками», и все запросы буду адресовать таблице animal:
Находим строку по номеру id:
|
SELECT * FROM `animal` WHERE id=1; |

В этом запросе мы используем оператор WHERE, после которого задаем критерий поиска. Выводим определенные столбцы искомой строки:
|
SELECT name FROM `animal` WHERE id=1; |

В данном примере мы вывели не полностью искомую строку, а только значение столбца name. Поиск по строковому значению:
|
SELECT * FROM `animal` WHERE name=‘gala’; |

Здесь мы использовали в качестве параметра для поиска по MySQL базе строчное значение. Сортировка результатов выборки по возрастанию или убыванию:
|
SELECT * FROM `animal` ORDER BY name; |

Для сортировки результатов выборки мы использовали директиву ORDER BY. По умолчанию, установлена сортировка по возрастанию (ключевое слово ASC). Чтобы задать обратный порядок (по убыванию) нужно использовать слово DESC.
|
SELECT * FROM `animal` ORDER BY name DESC; |

Если нужно найти значения, отвечающие определенным параметрам, и отсортировать результаты выборки по убыванию:
|
SELECT * FROM `animal` WHERE name=‘dog’ ORDER BY ID DESC; |

Углубляемся
Давайте покинем наше «зверье» и перенесемся в базу данных world. На ней я продемонстрирую еще несколько примеров выборки данных, соответствующих заданным параметрам. Все запросы я буду демонстрировать на основе таблицы country. Иногда (особенно в больших по размеру таблицах) требуется задать не один критерий для поиска, а несколько. Тогда запрос на получения списка стран из Европы и Африки будет выглядеть следующим образом:
|
SELECT Name, Continent FROM `country` WHERE Continent=‘Africa’ OR Continent=‘Europe’; |

Этот же запрос на поиск по MySQL базе можно укоротить, если использовать ключевое слово in. Например:
|
SELECT Name, Continent FROM `country` WHERE Continent in (‘Africa’,‘Europe’); |
Для указания диапазона выборки применяется ключевое слово Between. Давайте выведем страны с численностью населения от 10 до 50 тыс. За основу возьмем предыдущий запрос:
|
SELECT Name, Continent, Population FROM `country` WHERE Population BETWEEN 10000 and 50000; |

Пример в PHP
Теперь приведем пример, как запустить поиск в PHP MySQL данных. Используем предыдущий запрос.
|
<?php $load= mysqli_connect(‘localhost’, ‘root’, ”, ‘world’); $res= mysqli_query($load, “SELECT Name,Continent,Population FROM `country` WHERE Population BETWEEN 10000 and 50000”); $r=mysqli_fetch_assoc($res); while ($r = mysqli_fetch_assoc($res)) { printf(“%s (%s)n”,$r[“Name”],$r[“Continent”]); } mysqli_free_result($res); mysqli_close($load); ?> |

Ну, вроде бы я вкратце рассказал вам все о поиске в MySQL. Надеюсь, из этой статьи вы почерпнули для себя что-то новенькое. А свою строку я так и не нашел. Наверное, кот утащил, пока я отходил от компа. Ох, уж это зверье :).
Время на прочтение
8 мин
Количество просмотров 587K
Надо “
SELECT * WHERE a=b FROM c” или “SELECT WHERE a=b FROM c ON *” ?
Если вы похожи на меня, то согласитесь: SQL — это одна из тех штук, которые на первый взгляд кажутся легкими (читается как будто по-английски!), но почему-то приходится гуглить каждый простой запрос, чтобы найти правильный синтаксис.
А потом начинаются джойны, агрегирование, подзапросы, и получается совсем белиберда. Вроде такой:
SELECT members.firstname || ' ' || members.lastname
AS "Full Name"
FROM borrowings
INNER JOIN members
ON members.memberid=borrowings.memberid
INNER JOIN books
ON books.bookid=borrowings.bookid
WHERE borrowings.bookid IN (SELECT bookid
FROM books
WHERE stock>(SELECT avg(stock)
FROM books))
GROUP BY members.firstname, members.lastname;Буэ! Такое спугнет любого новичка, или даже разработчика среднего уровня, если он видит SQL впервые. Но не все так плохо.
Легко запомнить то, что интуитивно понятно, и с помощью этого руководства я надеюсь снизить порог входа в SQL для новичков, а уже опытным предложить по-новому взглянуть на SQL.
Не смотря на то, что синтаксис SQL почти не отличается в разных базах данных, в этой статье для запросов используется PostgreSQL. Некоторые примеры будут работать в MySQL и других базах.
1. Три волшебных слова
В SQL много ключевых слов, но SELECT, FROM и WHERE присутствуют практически в каждом запросе. Чуть позже вы поймете, что эти три слова представляют собой самые фундаментальные аспекты построения запросов к базе, а другие, более сложные запросы, являются всего лишь надстройками над ними.
2. Наша база
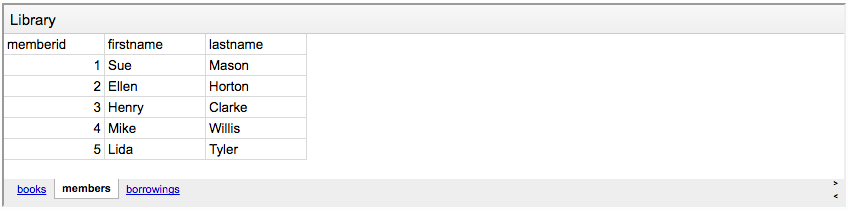
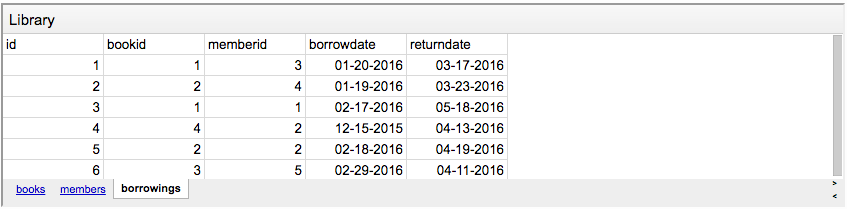
Давайте взглянем на базу данных, которую мы будем использовать в качестве примера в этой статье:

(ссылка на таблицу)
У нас есть книжная библиотека и люди. Также есть специальная таблица для учета выданных книг.
- В таблице “books” хранится информация о заголовке, авторе, дате публикации и наличии книги. Все просто.
- В таблице “members” — имена и фамилии всех записавшихся в библиотеку людей.
- В таблице “borrowings” хранится информация о взятых из библиотеки книгах. Колонка
bookidотносится к идентификатору взятой книги в таблице “books”, а колонкаmemberidотносится к соответствующему человеку из таблицы “members”. У нас также есть дата выдачи и дата, когда книгу нужно вернуть.
3. Простой запрос
Давайте начнем с простого запроса: нам нужны имена и идентификаторы (id) всех книг, написанных автором “Dan Brown”
Запрос будет таким:
SELECT bookid AS "id", title
FROM books
WHERE author='Dan Brown';А результат таким:
| id | title |
|---|---|
| 2 | The Lost Symbol |
| 4 | Inferno |
Довольно просто. Давайте разберем запрос чтобы понять, что происходит.
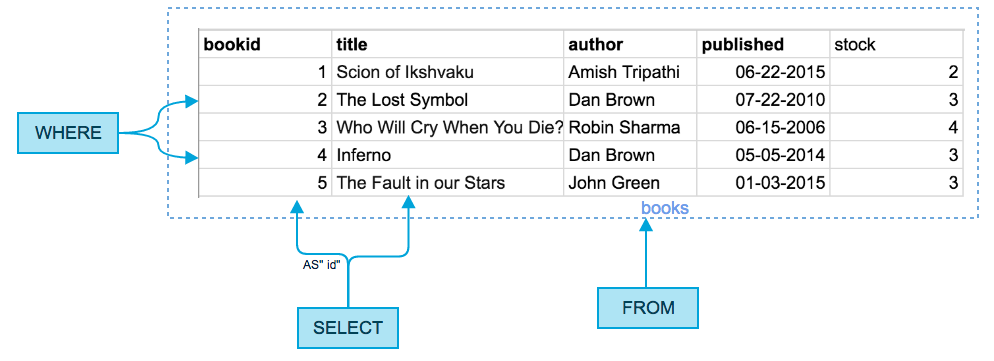
3.1 FROM — откуда берем данные
Сейчас это может показаться очевидным, но FROM будет очень важен позже, когда мы перейдем к соединениям и подзапросам.
FROM указывает на таблицу, по которой нужно делать запрос. Это может быть уже существующая таблица (как в примере выше), или таблица, создаваемая на лету через соединения или подзапросы.
3.2 WHERE — какие данные показываем
WHERE просто-напросто ведет себя как фильтр строк, которые мы хотим вывести. В нашем случае мы хотим видеть только те строки, где значение в колонке author — это “Dan Brown”.
3.3 SELECT — как показываем данные
Теперь, когда у нас есть все нужные нам колонки из нужной нам таблицы, нужно решить, как именно показывать эти данные. В нашем случае нужны только названия и идентификаторы книг, так что именно это мы и выберем с помощью SELECT. Заодно можно переименовать колонку используя AS.
Весь запрос можно визуализировать с помощью простой диаграммы:
4. Соединения (джойны)
Теперь мы хотим увидеть названия (не обязательно уникальные) всех книг Дэна Брауна, которые были взяты из библиотеки, и когда эти книги нужно вернуть:
SELECT books.title AS "Title", borrowings.returndate AS "Return Date"
FROM borrowings JOIN books ON borrowings.bookid=books.bookid
WHERE books.author='Dan Brown';Результат:
| Title | Return Date |
|---|---|
| The Lost Symbol | 2016-03-23 00:00:00 |
| Inferno | 2016-04-13 00:00:00 |
| The Lost Symbol | 2016-04-19 00:00:00 |
По большей части запрос похож на предыдущий за исключением секции FROM. Это означает, что мы запрашиваем данные из другой таблицы. Мы не обращаемся ни к таблице “books”, ни к таблице “borrowings”. Вместо этого мы обращаемся к новой таблице, которая создалась соединением этих двух таблиц.
borrowings JOIN books ON borrowings.bookid=books.bookid — это, считай, новая таблица, которая была сформирована комбинированием всех записей из таблиц “books” и “borrowings”, в которых значения bookid совпадают. Результатом такого слияния будет:

А потом мы делаем запрос к этой таблице так же, как в примере выше. Это значит, что при соединении таблиц нужно заботиться только о том, как провести это соединение. А потом запрос становится таким же понятным, как в случае с «простым запросом» из пункта 3.
Давайте попробуем чуть более сложное соединение с двумя таблицами.
Теперь мы хотим получить имена и фамилии людей, которые взяли из библиотеки книги автора “Dan Brown”.
На этот раз давайте пойдем снизу вверх:
Шаг Step 1 — откуда берем данные? Чтобы получить нужный нам результат, нужно соединить таблицы “member” и “books” с таблицей “borrowings”. Секция JOIN будет выглядеть так:
borrowings
JOIN books ON borrowings.bookid=books.bookid
JOIN members ON members.memberid=borrowings.memberidРезультат соединения можно увидеть по ссылке.
Шаг 2 — какие данные показываем? Нас интересуют только те данные, где автор книги — “Dan Brown”
WHERE books.author='Dan Brown'Шаг 3 — как показываем данные? Теперь, когда данные получены, нужно просто вывести имя и фамилию тех, кто взял книги:
SELECT
members.firstname AS "First Name",
members.lastname AS "Last Name"Супер! Осталось лишь объединить три составные части и сделать нужный нам запрос:
SELECT
members.firstname AS "First Name",
members.lastname AS "Last Name"
FROM borrowings
JOIN books ON borrowings.bookid=books.bookid
JOIN members ON members.memberid=borrowings.memberid
WHERE books.author='Dan Brown';Что даст нам:
| First Name | Last Name |
|---|---|
| Mike | Willis |
| Ellen | Horton |
| Ellen | Horton |
Отлично! Но имена повторяются (они не уникальны). Мы скоро это исправим.
5. Агрегирование
Грубо говоря, агрегирования нужны для конвертации нескольких строк в одну. При этом, во время агрегирования для разных колонок используется разная логика.
Давайте продолжим наш пример, в котором появляются повторяющиеся имена. Видно, что Ellen Horton взяла больше одной книги, но это не самый лучший способ показать эту информацию. Можно сделать другой запрос:
SELECT
members.firstname AS "First Name",
members.lastname AS "Last Name",
count(*) AS "Number of books borrowed"
FROM borrowings
JOIN books ON borrowings.bookid=books.bookid
JOIN members ON members.memberid=borrowings.memberid
WHERE books.author='Dan Brown'
GROUP BY members.firstname, members.lastname;Что даст нам нужный результат:
| First Name | Last Name | Number of books borrowed |
|---|---|---|
| Mike | Willis | 1 |
| Ellen | Horton | 2 |
Почти все агрегации идут вместе с выражением GROUP BY. Эта штука превращает таблицу, которую можно было бы получить запросом, в группы таблиц. Каждая группа соответствует уникальному значению (или группе значений) колонки, которую мы указали в GROUP BY. В нашем примере мы конвертируем результат из прошлого упражнения в группу строк. Мы также проводим агрегирование с count, которая конвертирует несколько строк в целое значение (в нашем случае это количество строк). Потом это значение приписывается каждой группе.
Каждая строка в результате представляет собой результат агрегирования каждой группы.

Можно прийти к логическому выводу, что все поля в результате должны быть или указаны в GROUP BY, или по ним должно производиться агрегирование. Потому что все другие поля могут отличаться друг от друга в разных строках, и если выбирать их SELECT‘ом, то непонятно, какие из возможных значений нужно брать.
В примере выше функция count обрабатывала все строки (так как мы считали количество строк). Другие функции вроде sum или max обрабатывают только указанные строки. Например, если мы хотим узнать количество книг, написанных каждым автором, то нужен такой запрос:
SELECT author, sum(stock)
FROM books
GROUP BY author;Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
| Dan Brown | 6 |
| John Green | 3 |
| Amish Tripathi | 2 |
Здесь функция sum обрабатывает только колонку stock и считает сумму всех значений в каждой группе.
6. Подзапросы

Подзапросы это обычные SQL-запросы, встроенные в более крупные запросы. Они делятся на три вида по типу возвращаемого результата.
6.1 Двумерная таблица
Есть запросы, которые возвращают несколько колонок. Хороший пример это запрос из прошлого упражнения по агрегированию. Будучи подзапросом, он просто вернет еще одну таблицу, по которой можно делать новые запросы. Продолжая предыдущее упражнение, если мы хотим узнать количество книг, написанных автором “Robin Sharma”, то один из возможных способов — использовать подзапросы:
SELECT *
FROM (
SELECT author, sum(stock)
FROM books
GROUP BY author
) AS results
WHERE author='Robin Sharma';Результат:
| author | sum |
|---|---|
| Robin Sharma | 4 |
6.2 Одномерный массив
Запросы, которые возвращают несколько строк одной колонки, можно использовать не только как двумерные таблицы, но и как массивы.
Допустим, мы хотим узнать названия и идентификаторы всех книг, написанных определенным автором, но только если в библиотеке таких книг больше трех. Разобьем это на два шага:
1. Получаем список авторов с количеством книг больше 3. Дополняя наш прошлый пример:
SELECT author
FROM (
SELECT author, sum(stock)
FROM books
GROUP BY author
) AS results
WHERE sum > 3;Результат:
| author |
|---|
| Robin Sharma |
| Dan Brown |
Можно записать как: ['Robin Sharma', 'Dan Brown']
2. Теперь используем этот результат в новом запросе:
SELECT title, bookid
FROM books
WHERE author IN (
SELECT author
FROM (
SELECT author, sum(stock)
FROM books
GROUP BY author
) AS results
WHERE sum > 3);Результат:
| title | bookid |
|---|---|
| The Lost Symbol | 2 |
| Who Will Cry When You Die? | 3 |
| Inferno | 4 |
Это то же самое, что:
SELECT title, bookid
FROM books
WHERE author IN ('Robin Sharma', 'Dan Brown');6.3 Отдельные значения
Бывают запросы, результатом которых являются всего одна строка и одна колонка. К ним можно относиться как к константным значениям, и их можно использовать везде, где используются значения, например, в операторах сравнения. Их также можно использовать в качестве двумерных таблиц или массивов, состоящих из одного элемента.
Давайте, к примеру, получим информацию о всех книгах, количество которых в библиотеке превышает среднее значение в данный момент.
Среднее количество можно получить таким образом:
select avg(stock) from books;Что дает нам:
| avg |
|---|
| 3.000 |
И это можно использовать в качестве скалярной величины 3.
Теперь, наконец, можно написать весь запрос:
SELECT *
FROM books
WHERE stock>(SELECT avg(stock) FROM books);Это то же самое, что:
SELECT *
FROM books
WHERE stock>3.000И результат:
| bookid | title | author | published | stock |
|---|---|---|---|---|
| 3 | Who Will Cry When You Die? | Robin Sharma | 2006-06-15 00:00:00 | 4 |
7. Операции записи
Большинство операций записи в базе данных довольно просты, если сравнивать с более сложными операциями чтения.
7.1 Update
Синтаксис запроса UPDATE семантически совпадает с запросом на чтение. Единственное отличие в том, что вместо выбора колонок SELECT‘ом, мы задаем знаения SET‘ом.
Если все книги Дэна Брауна потерялись, то нужно обнулить значение количества. Запрос для этого будет таким:
UPDATE books
SET stock=0
WHERE author='Dan Brown';WHERE делает то же самое, что раньше: выбирает строки. Вместо SELECT, который использовался при чтении, мы теперь используем SET. Однако, теперь нужно указать не только имя колонки, но и новое значение для этой колонки в выбранных строках.

7.2 Delete
Запрос DELETE это просто запрос SELECT или UPDATE без названий колонок. Серьезно. Как и в случае с SELECT и UPDATE, блок WHERE остается таким же: он выбирает строки, которые нужно удалить. Операция удаления уничтожает всю строку, так что не имеет смысла указывать отдельные колонки. Так что, если мы решим не обнулять количество книг Дэна Брауна, а вообще удалить все записи, то можно сделать такой запрос:
DELETE FROM books
WHERE author='Dan Brown';7.3 Insert
Пожалуй, единственное, что отличается от других типов запросов, это INSERT. Формат такой:
INSERT INTO x
(a,b,c)
VALUES
(x, y, z);Где a, b, c это названия колонок, а x, y и z это значения, которые нужно вставить в эти колонки, в том же порядке. Вот, в принципе, и все.
Взглянем на конкретный пример. Вот запрос с INSERT, который заполняет всю таблицу “books”:
INSERT INTO books
(bookid,title,author,published,stock)
VALUES
(1,'Scion of Ikshvaku','Amish Tripathi','06-22-2015',2),
(2,'The Lost Symbol','Dan Brown','07-22-2010',3),
(3,'Who Will Cry When You Die?','Robin Sharma','06-15-2006',4),
(4,'Inferno','Dan Brown','05-05-2014',3),
(5,'The Fault in our Stars','John Green','01-03-2015',3);8. Проверка
Мы подошли к концу, предлагаю небольшой тест. Посмотрите на тот запрос в самом начале статьи. Можете разобраться в нем? Попробуйте разбить его на секции SELECT, FROM, WHERE, GROUP BY, и рассмотреть отдельные компоненты подзапросов.
Вот он в более удобном для чтения виде:
SELECT members.firstname || ' ' || members.lastname AS "Full Name"
FROM borrowings
INNER JOIN members
ON members.memberid=borrowings.memberid
INNER JOIN books
ON books.bookid=borrowings.bookid
WHERE borrowings.bookid IN (SELECT bookid FROM books WHERE stock> (SELECT avg(stock) FROM books) )
GROUP BY members.firstname, members.lastname;Этот запрос выводит список людей, которые взяли из библиотеки книгу, у которой общее количество выше среднего значения.
Результат:
| Full Name |
|---|
| Lida Tyler |
Надеюсь, вам удалось разобраться без проблем. Но если нет, то буду рад вашим комментариям и отзывам, чтобы я мог улучшить этот пост.
Где-то месяц назад ко мне обратился коллега с просьбой помочь составить комплексный запрос (если это можно так назвать), который можно было бы скопировать и вставить в phpMyAdmin, для выборки всех данных из таблиц плагина, оставшихся после удаления сайта/сайтов из сети WordPress.
Что? Объясняю. Допустим, у нас есть сеть на WordPress, в которой имеется N число сайтов. Установлен сетевой плагин, который для каждого сайта создает собственную таблицу в базе данных. Таблицы имеют следующие имена: wp_table для первого сайта и wp_N_table для N-го сайта (например, wp_10_table для десятого сайта в сети). В нашем случае, сайт X, Y и Z были удалены, но таблицы остались. Задача: одним запросом получить данные из этих таблиц для дальнейшего анализа.
Я не считаю себя огромным специалистом SQL и мне данная задача изначально показалась если не невыполнимой, то уж точно не той, которую я мог бы решить за пару минут. Пришлось покопаться в сети и найти как такое решают другие. Ниже представлено мое видение потенциального решения данной проблемы. Не беру на себя ответственность утверждать, что это самое оптимальное решение, но оно позволило мне поближе познакомиться с процедурным расширением SQL.
Итак, приступим. Изначально я разбил задачу на несколько этапов:
- Получить список всех таблиц от плагина
- Найти «таблицы-сироты»
- Получить данные из найденных таблиц
Чтобы всего этого добиться, мы будем использовать хранимые процедуры в SQL.
Хранимая процедура — объект базы данных, представляющий собой набор SQL-инструкций, который компилируется один раз и хранится на сервере. Хранимые процедуры очень похожи на обыкновенные процедуры языков высокого уровня, у них могут быть входные и выходные параметры и локальные переменные, в них могут производиться числовые вычисления и операции над символьными данными, результаты которых могут присваиваться переменным и параметрам. В хранимых процедурах могут выполняться стандартные операции с базами данных (как DDL, так и DML). Кроме того, в хранимых процедурах возможны циклы и ветвления, то есть в них могут использоваться инструкции управления процессом исполнения.
Базовый синтаксис для них следующий:
DELIMITER $$
CREATE PROCEDURE GetAllTables()
BEGIN
...
END
$$
CALL GetAllTables();С помощью DELIMITER $$ мы задаем последовательность символов, которая будет завершать хранимую процедуру, без этого при наборе первой же строчки SQL будет исполнять набранный код. Данная последовательность может быть произвольной. В конце $$ укажет на завершение процедуры.
Создаем процедуру GetAllTables() с помощью CREATE PROCEDURE, она будет иметь начало BEGIN и конец END.
CALL GetAllTables(); — это выполнение всей процедуры.
В теле GetAllTables() мы объявляем переменные с помощью инструкции DECLARE, задаем тип и значение по умолчанию:
DECLARE v_finished INTEGER DEFAULT 0;
DECLARE v_table VARCHAR(100) DEFAULT "";В переменной v_finished мы будем хранить статус обработки, в v_table — текущую таблицу.
Далее мы будем использовать курсор, чтобы осуществить построчную обработку нашего запроса. Задаем курсор table_cursor, который будет получать название таблиц из базы данных, соответствующих определенной маске.
DECLARE table_cursor CURSOR FOR
SELECT table_name FROM information_schema.tables
WHERE table_schema = 'local' AND table_name LIKE '%mp_product_attributes';Указываем что мы будем делать, когда не найдем больше результатов. Обработчик ошибок объявляется следующим образом:
DECLARE action HANDLER FOR condition_value statement;Здесь action может принимать значение CONTINUE или EXIT, которые указывают на то что нужно продолжить или прекратить исполнение кода при достижении определенных условий. В нашем случае условием является NOT FOUND (результатов больше нет), при достижении которого мы задаем значение переменной v_finished равной 1.
DECLARE CONTINUE HANDLER
FOR NOT FOUND SET v_finished = 1;Теперь мы отобразим все таблицы, которые были найдены в базе данных по заданной маске. Для этого лишь надо выполнить SQL запрос:
SELECT table_name FROM information_schema.tables
WHERE table_schema = 'local' AND table_name LIKE '%mp_product_attributes';Наверное, повторение одного запроса здесь и выше, когда мы задавали курсор, является не самым оптимальным решением, но зато оно понятно для начинающих и не требует каких-то углубленных знаний SQL.
Далее мы откроем установленный раннее курсор и задаем цикл get_data, где будем последовательно присваивать переменной v_table результаты нашего запроса.
OPEN table_cursor;
get_data: LOOP
FETCH table_cursor INTO v_table;
...
END LOOP get_data;
CLOSE table_cursor;Проверяем закончилась ли выборка и есть ли еще результаты. Напоминаю, что если результатов нет, то переменная v_finished будет равна 1. Это мы задавали выше. Если больше результатов нет, то мы выходим из цикла.
IF v_finished = 1 THEN
LEAVE get_data;
END IF;Здесь у меня возникла небольшая проблема: таблицы-то я нахожу, но как определить что именно данная таблица — это оставшаяся таблица от удаленного сайта. Как я писал выше, все таблицы в базе данных имеют вид wp_N_table. Нам лишь нужно получить значение N, присвоить его переменной v_id и посмотреть есть ли сайт с данным индексом в таблице wp_blogs. Но есть одно условие — у первого сайта в сети не будет индекса N, таблица будет иметь вид wp_table. Но, в то же время, сайт с индексом 1 все равно будет присутствовать в таблице wp_blogs. Чтобы избежать ошибок, мы сделаем небольшую проверку и установим v_id = 1, если N не будет задана в названии таблицы:
SET @v_id = substr(v_table, 4, length(v_table) - 25);
IF @v_id = '' THEN
SET @v_id = 1;
END IF;Теперь осталось самое простое — для всех таблиц, индекс которых мы не нашли в wp_blogs, нужно выполнить запрос выборки данных и отобразить все это пользователю:
IF (SELECT COUNT(*) FROM wp_blogs WHERE blog_id = @v_id) = 0 THEN
SET @sql_query = concat("SELECT * FROM ", v_table);
PREPARE stmt FROM @sql_query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END IF;Чтобы подставить значение v_table в запрос, необходимо использовать команду concat, результат которой мы присваиваем переменной sql_query. Кстати, переменные в коде задаются с символом @ перед именем.
Подготавливаем запрос к исполнению PREPARE и исполняем EXECUTE.
Вот итоговый результат:
DELIMITER $$
DROP PROCEDURE IF EXISTS GetAllTables$$
CREATE PROCEDURE GetAllTables()
BEGIN
DECLARE v_finished INTEGER DEFAULT 0;
DECLARE v_table VARCHAR(100) DEFAULT "";
DECLARE table_cursor CURSOR FOR
SELECT table_name FROM information_schema.tables
WHERE table_schema = 'local' AND table_name LIKE '%mp_product_attributes';
DECLARE CONTINUE HANDLER
FOR NOT FOUND SET v_finished = 1;
SELECT table_name FROM information_schema.tables
WHERE table_schema = 'local' AND table_name LIKE '%mp_product_attributes';
OPEN table_cursor;
get_data: LOOP
FETCH table_cursor INTO v_table;
IF v_finished = 1 THEN
LEAVE get_data;
END IF;
SET @v_id = substr(v_table, 4, length(v_table) - 25);
IF @v_id = '' THEN
SET @v_id = 1;
END IF;
IF (SELECT COUNT(*) FROM wp_blogs WHERE blog_id = @v_id) = 0 THEN
SET @sql_query = concat("SELECT * FROM ", v_table);
PREPARE stmt FROM @sql_query;
EXECUTE stmt;
DEALLOCATE PREPARE stmt;
END IF;
END LOOP get_data;
CLOSE table_cursor;
END$$
CALL GetAllTables();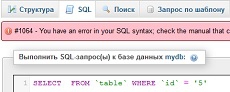
SQL-запрос – это то, что либо работает хорошо, либо не работает вообще, частично он никак работать не может, в отличие, например, от того же PHP. Как следствие, найти ошибку в SQL-запросе, просто рассматривая его – трудно, особенно если этот запрос снабжён целой кучей JOIN и UNION. Однако, в этой статье я расскажу о методе поиска ошибок в SQL-запросе.
Поскольку обычно в SQL-запрос подставляются какие-то переменные в PHP, то необходимо его сначала вывести. Сделать это можно, например, так:
<?php
$a = 5;
$query = "SELECT FROM `table` WHERE `id` = '$a'";
$result_set = $mysqli->query($query); // Не работает
echo $query; // Выводим запрос, который отправляется
?>
В результате, скрипт выведет такой запрос: SELECT FROM `table` WHERE `id` = ‘5’. Теперь чтобы найти ошибку в нём, надо зайти в phpMyAdmin, открыть базу данных, с которой происходит работа, открыть вкладку “SQL” и попытаться выполнить запрос.
И вот здесь уже ошибка будет показана, не в самой понятной форме (иногда прямо точно описывает ошибку), но она будет. Вот что написал phpMyAdmin: “#1064 – You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ‘FROM `table` WHERE `id` = ‘5’ ORDER BY `table`.`id` ASC LIMIT 0, 30′ at line 1“. Это означает, что ошибка рядом с FROM. Присматриваемся к этому выделенному нами небольшому участку и обнаруживаем, что мы забыли поставить “*“. Исправляем сразу в phpMyAdmin эту ошибку, убеждаемся, что запрос сработал и после этого идём исправлять ошибку уже в коде.
С помощью этого метода я нахожу абсолютно все ошибки в SQL-запросе, которые мне не удаётся обнаружить непосредственно при осмотре в PHP-коде.
Надеюсь, теперь и Вы сможете найти ошибку в любом SQL-запросе.
-

Создано 01.05.2013 10:54:01
-

Михаил Русаков
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov.ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
Она выглядит вот так:

-
Текстовая ссылка:
Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):
