Продолжаем изучать элементарные задачи по математике. Сегодня мы поговорим о статистике.
Статистика — это раздел математики в котором изучаются вопросы сбора, измерения и анализа информации, представленной в числовой форме. Происходит слово статистика от латинского слова status (состояние или положение дел).
Так, с помощью статистики мы можем узнать свое положение дел, касающихся финансов. С начала месяца можно вести дневник расходов и по окончании месяца, воспользовавшись статистикой, узнать сколько денег в среднем мы тратили каждый день или какая потраченная сумма была наибольшей в этом месяце либо узнать какую сумму мы тратили наиболее часто.
На основе этой информации можно провести анализ и сделать определенные выводы: следует ли в следующем месяце немного сбавить аппетит, чтобы тратить меньше денег, либо наоборот позволить себе не только хлеб с водой, но и колбасу.
Выборка. Объем. Размах
Что такое выборка? Если говорить простым языком, то это отобранная нами информация для исследования. Например, мы можем сформировать следующую выборку — суммы денег, потраченных в каждый из шести дней. Давайте нарисуем таблицу в которую занесем расходы за шесть дней

Выборка состоит из n-элементов. Вместо переменной n может стоять любое число. У нас имеется шесть элементов, поэтому переменная n равна 6
n = 6
Элементы выборки обозначаются с помощью переменных с индексами ![]() . Последний
. Последний ![]() элемент является шестым элементом выборки, поэтому вместо n будет стоять число 6.
элемент является шестым элементом выборки, поэтому вместо n будет стоять число 6.

Обозначим элементы нашей выборки через переменные ![]()
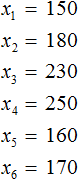
Количество элементов выборки называют объемом выборки. В нашем случае объем равен шести.
Размахом выборки называют разницу между самым большим и маленьким элементом выборки.
В нашем случае, самым большим элементом выборки является элемент 250, а самым маленьким — элемент 150. Разница между ними равна 100
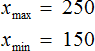
Среднее арифметическое
Понятие среднего значения часто используется в повседневной жизни.
Примеры:
- средняя зарплата жителей страны;
- средний балл учащихся;
- средняя скорость движения;
- средняя производительность труда.
Речь идет о среднем арифметическом — результате деления суммы элементов выборки на их количество.
Среднее арифметическое — это результат деления суммы элементов выборки на их количество.
![]()
Вернемся к нашему примеру
Узнаем сколько в среднем мы тратили в каждом из шести дней:
![]()
Средняя скорость движения
При изучении задач на движение мы определяли скорость движения следующим образом: делили пройденное расстояние на время. Но тогда подразумевалось, что тело движется с постоянной скоростью, которая не менялась на протяжении всего пути.
В реальности, это происходит довольно редко или не происходит совсем. Тело, как правило, движется с различной скоростью.
Когда мы ездим на автомобиле или велосипеде, наша скорость часто меняется. Когда впереди нас помехи, нам приходиться сбавлять скорость. Когда же трасса свободна, мы ускоряемся. При этом за время нашего ускорения скорость изменяется несколько раз.
Речь идет о средней скорости движения. Чтобы её определить нужно сложить скорости движения, которые были в каждом часе/минуте/секунде и результат разделить на время движения.
Задача 1. Автомобиль первые 3 часа двигался со скоростью 66,2 км/ч, а следующие 2 часа — со скоростью 78,4 км/ч. С какой средней скоростью он ехал?

Сложим скорости, которые были у автомобиля в каждом часе и разделим на время движения (5ч)
![]()
Значит автомобиль ехал со средней скоростью 71,08 км/ч.
Определять среднюю скорость можно и по другому — сначала найти расстояния, пройденные с одной скоростью, затем сложить эти расстояния и результат разделить на время. На рисунке видно, что первые три часа скорость у автомобиля не менялась. Тогда можно найти расстояние, пройденное за три часа:
66,2 × 3 = 198,6 км.
Аналогично можно определить расстояние, которое было пройдено со скоростью 78,4 км/ч. В задаче сказано, что с такой скоростью автомобиль двигался 2 часа:
78,4 × 2 = 156,8 км.
Сложим эти расстояния и результат разделим на 5
![]()
Задача 2. Велосипедист за первый час проехал 12,6 км, а в следующие 2 часа он ехал со скоростью 13,5 км/ч. Определить среднюю скорость велосипедиста.

Скорость велосипедиста в первый час составляла 12,6 км/ч. Во второй и третий час он ехал со скоростью 13,5. Определим среднюю скорость движения велосипедиста:
![]()
Мода и медиана
Модой называют элемент, который встречается в выборке чаще других.
Рассмотрим следующую выборку: шестеро спортсменов, а также время в секундах за которое они пробегают 100 метров

Элемент 14 встречается в выборке чаще других, поэтому элемент 14 назовем модой.
Рассмотрим еще одну выборку. Тех же спортсменов, а также смартфоны, которые им принадлежат

Элемент iphone встречается в выборке чаще других, значит элемент iphone является модой. Говоря простым языком, носить iphone модно.
Конечно элементы выборки в этот раз выражены не числами, а другими объектами (смартфонами), но для общего представления о моде этот пример вполне приемлем.
Рассмотрим следующую выборку: семеро спортсменов, а также их рост в сантиметрах:

Упорядочим данные в таблице так, чтобы рост спортсменов шел по возрастанию. Другими словами, построим спортсменов по росту:

Выпишем рост спортсменов отдельно:
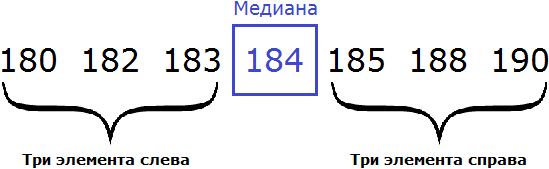
180, 182, 183, 184, 185, 188, 190
В получившейся выборке 7 элементов. Посередине этой выборки располагается элемент 184. Слева и справа от него по три элемента. Такой элемент как 184 называют медианой упорядоченной выборки.
Медианой упорядоченной выборки называют элемент, располагающийся посередине.
Отметим, что данное определение справедливо в случае, если количество элементов упорядоченной выборки является нечётным.
В рассмотренном выше примере, количество элементов упорядоченной выборки было нечётным. Это позволило нам быстро указать медиану
Но возможны случаи, когда количество элементов выборки чётно.
К примеру, рассмотрим выборку в которой не семеро спортсменов, а шестеро:

Построим этих шестерых спортсменов по росту:

Выпишем рост спортсменов отдельно:
180, 182, 184, 186, 188, 190
В данной выборке не получается указать элемент, который находился бы посередине. Если указать элемент 184 как медиану, то слева от этого элемента будут располагаться два элемента, а справа — три. Если как медиану указать элемент 186, то слева от этого элемента будут располагаться три элемента, а справа — два.
В таких случаях для определения медианы выборки, нужно взять два элемента выборки, находящихся посередине и найти их среднее арифметическое. Полученный результат будет являться медианой.
Вернемся к нашим спортсменам. В упорядоченной выборке 180, 182, 184, 186, 188, 190 посередине располагаются элементы 184 и 186

Найдем среднее арифметическое элементов 184 и 186
![]()
Элемент 185 является медианой выборки, несмотря на то, что этот элемент не является членом исходной и упорядоченной выборки. Спортсмена с ростом 185 нет среди остальных спортсменов. Рост в 185 см используется в данном случае для статистики, чтобы можно было сказать о том, что срединный рост спортсменов составляет 185 см.
Поэтому более точное определение медианы зависит от количества элементов в выборке.
Если количество элементов упорядоченной выборки нечётно, то медианой выборки называют элемент, располагающийся посередине.
Если количество элементов упорядоченной выборки чётно, то медианой выборки называют среднее арифметическое двух чисел, располагающихся посередине этой выборки.
Медиана и среднее арифметическое по сути являются «близкими родственниками», поскольку и то и другое используют для определения среднего значения. Например, для предыдущей упорядоченной выборки 180, 182, 184, 186, 188, 190 мы определили медиану, равную 185. Этот же результат можно получить путем определения среднего арифметического элементов 180, 182, 184, 186, 188, 190
![]()
Но медиана в некоторых случаях отражает более реальную ситуацию. Например, рассмотрим следующий пример:
Было подсчитано количество имеющихся очков у каждого спортсмена. В результате получилась следующая выборка:
0, 1, 1, 1, 2, 1, 2, 3, 5, 4, 5, 0, 1, 6, 1
Определим среднее арифметическое для данной выборки — получим значение 2,2
![]()
По данному значению можно сказать, что в среднем у спортсменов 2,2 очка
Теперь определим медиану для этой же выборки. Упорядочим элементы выборки и укажем элемент, находящийся посередине:
0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 3, 4, 5, 5, 6
В данном примере медиана лучше отражает реальную ситуацию, поскольку половина спортсменов имеет не более одного очка.
Частота
Частота это число, которое показывает сколько раз в выборке встречается тот или иной элемент.
Предположим, что в школе проходят соревнования по подтягиваниям. В соревнованиях участвует 36 школьников. Составим таблицу в которую будем заносить число подтягиваний, а также число участников, которые выполнили столько подтягиваний.
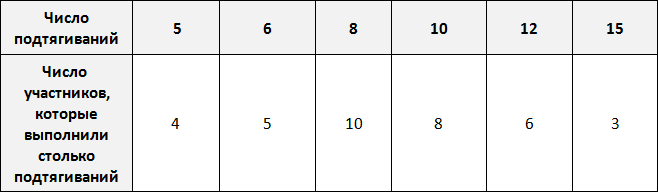
По таблице можно узнать сколько человек выполнило 5, 10 или 15 подтягиваний. Так, 5 подтягиваний выполнили четыре человека, 10 подтягиваний выполнили восемь человек, 15 подтягиваний выполнили три человека.
Количество человек, повторяющих одно и то же число подтягиваний в данном случае являются частотой. Поэтому вторую строку таблицы переименуем в название «частота»:

Такие таблицы называют таблицами частот.
Частота обладает следующим свойством: сумма частот равна общему числу данных в выборке.
Это означает, что сумма частот равна общему числу школьников, участвующих в соревнованиях, то есть тридцати шести. Проверим так ли это. Сложим частоты, приведенные в таблице:
4 + 5 + 10 + 8 + 6 + 3 = 36
Относительная частота
Относительная частота это в принципе та же самая частота, которая была рассмотрена ранее, но только выраженная в процентах.
Относительная частота равна отношению частоты на общее число элементов выборки.
Вернемся к нашей таблице:
Пять подтягиваний выполнили 4 человека из 36. Шесть подтягиваний выполнили 5 человек из 36. Восемь подтягиваний выполнили 10 человек из 36 и так далее. Давайте заполним таблицу с помощью таких отношений:

Выполним деление в этих дробях:

Выразим эти частоты в процентах. Для этого умножим их на 100. Умножение на 100 удобно выполнить передвижением запятой на две цифры вправо:

Теперь можно сказать, что пять подтягиваний выполнили 11% участников, 6 подтягиваний выполнили 14% участников, 8 подтягиваний выполнили 28% участников и так далее.
Понравился урок?
Вступай в нашу новую группу Вконтакте и начни получать уведомления о новых уроках
Возникло желание поддержать проект?
Используй кнопку ниже


![]()
Загрузить PDF
![]()
Загрузить PDF
С абсолютной частотой все довольно просто: она определяет, сколько раз конкретное число содержится в имеющемся наборе данных (объектов или значений). А вот относительная частота характеризует отношение количества конкретного числа в наборе данных. Другими словами, относительная частота – это отношение количества определенного числа к общему количеству чисел в наборе данных. Имейте в виду, что вычислить относительную частоту достаточно легко.
-

1
Соберите данные. Если вы решаете математическую задачу, в ее условии должен быть дан набор данных (чисел). В противном случае проведите эксперимент или исследование и соберите необходимые данные. Подумайте, в какой форме записать исходные данные.
- Например, нужно собрать данные о возрасте людей, которые посмотрели определенный фильм. Конечно, можно записать точный возраст каждого человека, но в этом случае вы получите довольно большой набор данных с 60-70 числами в пределах от 10 до 70 или 80. Поэтому лучше сгруппировать данные по категориям, таким как «Моложе 20», «20-29», «30-39» «40-49», «50-59» и «Старше 60». Получится упорядоченный набор данных с шестью группами чисел.
- Другой пример: врач собирает данные о температуре пациентов в определенный день. Если записать округленные числа, например, 37, 38, 39, то результат будет не слишком точным, поэтому здесь данные нужно представить в виде десятичных дробей.
-

2
Упорядочьте данные. Когда вы соберете данные, у вас, скорее всего, получится хаотичный набор чисел, например, такой: 1, 2, 5, 4, 6, 4, 3, 7, 1, 5, 6, 5, 3, 4, 5, 1. Такая запись кажется практически бессмысленной и с ней сложно работать. Поэтому упорядочьте числа по возрастанию (от меньшего к большему), например, так: 1,1,1,2,3,3,4,4,4,5,5,5,5,6,6,7.[1]
- Упорядочивая данные, будьте внимательны, чтобы не пропустить ни одного числа. Посчитайте общее количество чисел в наборе данных, чтобы убедиться, что вы записали все числа.
-

3
Создайте таблицу с данными. Собранные данные можно организовать в виде таблицы. Такая таблица будет включать три столбца и использоваться для вычисления относительной частоты. Столбцы обозначьте следующим образом:[2]
Реклама
-

1
Найдите количество чисел в наборе данных. Относительная частота характеризует, сколько раз конкретное число содержится в имеющемся наборе данных по отношению к общему количеству чисел. Чтобы найти относительную частоту, нужно посчитать общее количество чисел в наборе данных. Общее количество чисел станет знаменателем дроби, с помощью которой будет вычислена относительная частота.[3]
- В нашем примере набор данных содержит 16 чисел.
-
2
Найдите количество определенного числа. То есть посчитайте, сколько раз конкретное число встречается в наборе данных. Это можно сделать как для одного числа, так и для всех чисел из набора данных.[4]
- Например, в нашем примере число
встречается в наборе данных три раза.
- Например, в нашем примере число
-

3
Разделите количество конкретного числа на общее количество чисел. Так вы найдете относительную частоту для определенного числа. Вычисление можно представить в виде дроби или воспользоваться калькулятором или электронной таблицей, чтобы разделить два числа.[5]
Реклама
-

1
Результаты вычислений запишите в созданную ранее таблицу. Она позволит представить результаты в наглядной форме. По мере вычисления относительной частоты результаты записывайте в таблицу напротив соответствующего числа. Как правило, значение относительной частоты можно округлить до второго знака после десятичной запятой, но это на ваше усмотрение (в зависимости от требований задачи или исследования). Помните, что округленный результат не равен точному ответу.[6]
- В нашем примере таблица относительных частот будет выглядеть следующим образом:
- x : n(x) : P(x)
- 1 : 3 : 0,19
- 2 : 1 : 0,06
- 3 : 2 : 0,13
- 4 : 3 : 0,19
- 5 : 4 : 0,25
- 6 : 2 : 0,13
- 7 : 1 : 0,06
- Итого : 16 : 1,01
-

2
Представьте числа (элементы), которых нет в наборе данных. Иногда представление чисел с нулевой частотой так же важно, как и представление чисел с ненулевой частотой. Обратите внимание на собранные данные; если между данными имеются пробелы, их нужно заполнить нулями.
- В нашем примере набор данных включает все числа от 1 до 7. Но предположим, что числа 3 нет в наборе. Возможно, это немаловажный факт, поэтому нужно записать, что относительная частота числа 3 равна 0.
-

3
Выразите результаты в процентах. Иногда результаты вычислений нужно преобразовать из десятичных дробей в проценты. Это общепринятая практика, потому что относительная частота характеризует процент случаев появления определенного числа в наборе данных. Чтобы преобразовать десятичную дробь в проценты, нужно десятичную запятую передвинуть на две позиции вправо и приписать символ процента.
- Например, десятичная дробь 0,13 равна 13%.
- Десятичная дробь 0,06 равна 6% (обратите внимание, что перед 6 стоит 0).
Реклама
Советы
- Относительная частота характеризует наличие или возникновение определенного события в наборе событий.
- Если сложить относительные частоты всех чисел из набора данных, вы получите единицу. Помните, что при сложении округленных результатов сумма не будет равна 1,0.
- Если набор данных слишком большой, чтобы обработать его вручную, воспользуйтесь программой MS Excel или MATLAB; это позволит избежать ошибок в процессе вычисления.
Реклама
Источники
Об этой статье
Эту страницу просматривали 144 719 раз.
Была ли эта статья полезной?
Относительная частота и статистическая вероятность. Основные формулы и решения типовых задач
Относительная частота (частость) события А определяется равенством
где n – общее число проведенных испытаний; m – число испытаний, в которых событие А наступило (иначе – частота события А).
При статистическом определении за вероятность события принимают его относительную частоту, найденную по результатам большого числа испытаний.
Задача №1. При определении всхожести партии семян взяли пробу из 1000 единиц. Из отобранных семян не взошло 90. Какова относительная частота появления всхожего семени?
Решение. Обозначим событие: А – отобрано всхожее семя. Найдем относительную частоту события А, применив формулу (5). Общее число проведенных испытаний n = 1000. Число испытаний, в которых событие А наступило, равно m = 1000 – 90 = 910.
Относительная частота события А равна
Задача №2. Для проведения исследований на некотором поле взяли случайную выборку из 200 колосьев пшеницы. Относительная частота (частость) колосьев, имеющих по 12 колосков в колосе, оказалась равной 0,123, а по 18 колосков – 0,05. Найти для этой выборки частоты колосьев, имущих по 12 и по 18 колосков.
Решение. Рассмотрим события: A – взят колос, имеющий 12 колосков; В – взят колос, имеющий 18 колосков.
Найдем частоты и
событий А и В применив формулу (5).
Обозначим через относительную частоту события A, а через
относительную частоту события В. Так как число проведенных испытаний n = 200, то
Задача №3. Многолетними наблюдениями установлено, что в некоторой области ежегодно в среднем в тридцати хозяйствах из каждых ста среднегодовой удой молока от одной коровы составляет 4 100 – 4 300 кг. Какова вероятность того, что в текущем году в одном из хозяйств этой области, отобранном случайным образом, будет получен такой среднегодовой удой?
Решение. Обозначим событие: А – в текущем году в хозяйстве области, отобранном случайным образом, среднегодовой удой молока от одной коровы составит 4 100 – 4 300 кг.
Вероятность события А найдем, воспользовавшись ее статистическим определением.
Располагая статистическими данными, найдем, что относительная частота хозяйств области, в которых ежегодно имеют указанный средне-годовой удой молока от одной коровы, равна 0,3. Так как эти данные получены в результате проведения большого числа наблюдений, выполняемых в течение многих лет, то можно принять, что вероятность события А равна Р(А) = 0,3.
From Wikipedia, the free encyclopedia
In statistics, the frequency (or absolute frequency) of an event 

Types[edit]
The cumulative frequency is the total of the absolute frequencies of all events at or below a certain point in an ordered list of events.[1]: 17–19
The relative frequency (or empirical probability) of an event is the absolute frequency normalized by the total number of events:

The values of 
In the case when 
Depicting frequency distributions[edit]
A frequency distribution shows us a summarized grouping of data divided into mutually exclusive classes and the number of occurrences in a class. It is a way of showing unorganized data notably to show results of an election, income of people for a certain region, sales of a product within a certain period, student loan amounts of graduates, etc. Some of the graphs that can be used with frequency distributions are histograms, line charts, bar charts and pie charts. Frequency distributions are used for both qualitative and quantitative data.
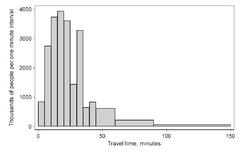
Histogram of travel time (to work), US 2000 census.


Horizontal 3D bar chart
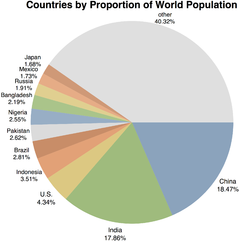
Pie chart of world population by country
Different ways of depicting frequency distributions
Construction[edit]
- Decide the number of classes. Too many classes or too few classes might not reveal the basic shape of the data set, also it will be difficult to interpret such frequency distribution. The ideal number of classes may be determined or estimated by formula:
(log base 10), or by the square-root choice formula
where n is the total number of observations in the data. (The latter will be much too large for large data sets such as population statistics.) However, these formulas are not a hard rule and the resulting number of classes determined by formula may not always be exactly suitable with the data being dealt with.
- Calculate the range of the data (Range = Max – Min) by finding the minimum and maximum data values. Range will be used to determine the class interval or class width.
- Decide the width of the classes, denoted by h and obtained by
(assuming the class intervals are the same for all classes).
Generally the class interval or class width is the same for all classes. The classes all taken together must cover at least the distance from the lowest value (minimum) in the data to the highest (maximum) value. Equal class intervals are preferred in frequency distribution, while unequal class intervals (for example logarithmic intervals) may be necessary in certain situations to produce a good spread of observations between the classes and avoid a large number of empty, or almost empty classes.[2]
- Decide the individual class limits and select a suitable starting point of the first class which is arbitrary; it may be less than or equal to the minimum value. Usually it is started before the minimum value in such a way that the midpoint (the average of lower and upper class limits of the first class) is properly[clarification needed] placed.
- Take an observation and mark a vertical bar (|) for a class it belongs. A running tally is kept till the last observation.
- Find the frequencies, relative frequency, cumulative frequency etc. as required.
The following are some commonly used methods of depicting frequency:[3]
Histograms[edit]
A histogram is a representation of tabulated frequencies, shown as adjacent rectangles or squares (in some of situations), erected over discrete intervals (bins), with an area proportional to the frequency of the observations in the interval. The height of a rectangle is also equal to the frequency density of the interval, i.e., the frequency divided by the width of the interval. The total area of the histogram is equal to the number of data. A histogram may also be normalized displaying relative frequencies. It then shows the proportion of cases that fall into each of several categories, with the total area equaling 1. The categories are usually specified as consecutive, non-overlapping intervals of a variable. The categories (intervals) must be adjacent, and often are chosen to be of the same size.[4] The rectangles of a histogram are drawn so that they touch each other to indicate that the original variable is continuous.[5]
Bar graphs[edit]
A bar chart or bar graph is a chart with rectangular bars with lengths proportional to the values that they represent. The bars can be plotted vertically or horizontally. A vertical bar chart is sometimes called a column bar chart.
Frequency distribution table[edit]
A frequency distribution table is an arrangement of the values that one or more variables take in a sample. Each entry in the table contains the frequency or count of the occurrences of values within a particular group or interval, and in this way, the table summarizes the distribution of values in the sample.
This is an example of a univariate (=single variable) frequency table. The frequency of each response to a survey question is depicted.
| Rank | Degree of agreement | Number |
|---|---|---|
| 1 | Strongly agree | 22 |
| 2 | Agree somewhat | 30 |
| 3 | Not sure | 20 |
| 4 | Disagree somewhat | 15 |
| 5 | Strongly disagree | 15 |
A different tabulation scheme aggregates values into bins such that each bin encompasses a range of values. For example, the heights of the students in a class could be organized into the following frequency table.
| Height range | Number of students | Cumulative number |
|---|---|---|
| less than 5.0 feet | 25 | 25 |
| 5.0–5.5 feet | 35 | 60 |
| 5.5–6.0 feet | 20 | 80 |
| 6.0–6.5 feet | 20 | 100 |
Joint frequency distributions[edit]
Bivariate joint frequency distributions are often presented as (two-way) contingency tables:
| Dance | Sports | TV | Total | |
|---|---|---|---|---|
| Men | 2 | 10 | 8 | 20 |
| Women | 16 | 6 | 8 | 30 |
| Total | 18 | 16 | 16 | 50 |
The total row and total column report the marginal frequencies or marginal distribution, while the body of the table reports the joint frequencies.[6]
Interpretation[edit]
Under the frequency interpretation of probability, it is assumed that as the length of a series of trials increases without bound, the fraction of experiments in which a given event occurs will approach a fixed value, known as the limiting relative frequency.[7][8]
This interpretation is often contrasted with Bayesian probability. In fact, the term ‘frequentist’ was first used by M. G. Kendall in 1949, to contrast with Bayesians, whom he called “non-frequentists”.[9][10] He observed
- 3….we may broadly distinguish two main attitudes. One takes probability as ‘a degree of rational belief’, or some similar idea…the second defines probability in terms of frequencies of occurrence of events, or by relative proportions in ‘populations’ or ‘collectives’; (p. 101)
- …
- 12. It might be thought that the differences between the frequentists and the non-frequentists (if I may call them such) are largely due to the differences of the domains which they purport to cover. (p. 104)
- …
- I assert that this is not so … The essential distinction between the frequentists and the non-frequentists is, I think, that the former, in an effort to avoid anything savouring of matters of opinion, seek to define probability in terms of the objective properties of a population, real or hypothetical, whereas the latter do not. [emphasis in original]
Applications[edit]
Managing and operating on frequency tabulated data is much simpler than operation on raw data. There are simple algorithms to calculate median, mean, standard deviation etc. from these tables.
Statistical hypothesis testing is founded on the assessment of differences and similarities between frequency distributions. This assessment involves measures of central tendency or averages, such as the mean and median, and measures of variability or statistical dispersion, such as the standard deviation or variance.
A frequency distribution is said to be skewed when its mean and median are significantly different, or more generally when it is asymmetric. The kurtosis of a frequency distribution is a measure of the proportion of extreme values (outliers), which appear at either end of the histogram. If the distribution is more outlier-prone than the normal distribution it is said to be leptokurtic; if less outlier-prone it is said to be platykurtic.
Letter frequency distributions are also used in frequency analysis to crack ciphers, and are used to compare the relative frequencies of letters in different languages and other languages are often used like Greek, Latin, etc.
See also[edit]
- Aperiodic frequency
- Count data
- Cross tabulation
- Cumulative distribution function
- Cumulative frequency analysis
- Empirical distribution function
- Law of large numbers
- Multiset multiplicity as frequency analog
- Probability density function
- Probability interpretations
- Statistical regularity
- Word frequency
References[edit]
- ^ a b Kenney, J. F.; Keeping, E. S. (1962). Mathematics of Statistics, Part 1 (3rd ed.). Princeton, NJ: Van Nostrand Reinhold.
- ^ Manikandan, S (1 January 2011). “Frequency distribution”. Journal of Pharmacology & Pharmacotherapeutics. 2 (1): 54–55. doi:10.4103/0976-500X.77120. ISSN 0976-500X. PMC 3117575. PMID 21701652.
- ^ Carlson, K. and Winquist, J. (2014) An Introduction to Statistics. SAGE Publications, Inc. Chapter 1: Introduction to Statistics and Frequency Distributions
- ^ Howitt, D. and Cramer, D. (2008) Statistics in Psychology. Prentice Hall
- ^ Charles Stangor (2011) “Research Methods For The Behavioral Sciences”. Wadsworth, Cengage Learning. ISBN 9780840031976.
- ^ Stat Trek, Statistics and Probability Glossary, s.v. Joint frequency
- ^ von Mises, Richard (1939) Probability, Statistics, and Truth (in German) (English translation, 1981: Dover Publications; 2 Revised edition. ISBN 0486242145) (p.14)
- ^ The Frequency theory Chapter 5; discussed in Donald Gilles, Philosophical theories of probability (2000), Psychology Press. ISBN 9780415182751 , p. 88.
- ^ Earliest Known Uses of Some of the Words of Probability & Statistics
- ^ Kendall, Maurice George (1949). “On the Reconciliation of Theories of Probability”. Biometrika. Biometrika Trust. 36 (1/2): 101–116. doi:10.1093/biomet/36.1-2.101. JSTOR 2332534.
Поможем решить контрольную, написать реферат, курсовую и диплом от 800р
Узнать стоимость
Статистическое распределение выборки
Содержание:
- Примеры использования формул и таблиц для решения практических задач
- Статистический интервальный ряд распределения
Предположим случай, когда из генеральной совокупности извлекается некоторая выборка, при этом каждому значению соответствует некоторый параметр, означающий количество раз, когда появлялось данное значение. Здесь $x_1$ было зафиксировано $n_1$ раз, $x_2$ было обнаружено $n_2$$x_k$ выявлено $n_k$. При этом
$sum_{i=1}^{k}n_i=n$
Где n — объём рассматриваемой выборки.
Определение 1
Используется следующая терминология: $x_k$ носят наименование вариантов, а последовательность таких вариантов, зафиксированный по возрастанию именуется вариационным рядом. Количество наблюдений каждого из вариантов носят название частот. При этом частное частот и выборки называют относительными частотами.
Определение 2
Статистическое распределение —это название всего набора вариантов и частот, которые с ними соотносятся. Чаще всего задаётся с помощью специальной таблицы, где представлены частоты, а также интервалы им соответствующие.
| $x_1$ | $x_2$ | … | $x_k$ |
| $n_1$ | $n_2$ | … | $n_k$ |
| $frac{n_1}{n}$ | $frac{n_2}{n}$ | $frac{n_k}{n}$ |
Здесь в первой строке представлены варианты, во второй частоты, в третьеq взяты относительные частоты.
Для определения размера интервала используется следующее выражение:
$d=frac{x_{max}- x_{min}}{1+3,332cdot lg n}$
Здесь $x_{max}$, $x_{min}$ наибольшее и наименьшее значения ряда вариантов, а n характеризуем объём выборки.
Примеры использования формул и таблиц для решения практических задач
Пример 1
В ходе проведения измерений в однородных группах, были определены следующие значения выборки: 71, 72, 74, 70, 70, 72, 71, 74, 71, 72, 71, 73, 72, 72, 72, 74, 72, 73, 72, 74. Необходимо использовать данные значения, что определить ряд распределения частот и ряд распределения относительных частот.
Решение.
1) Составим статистический ряд распределения частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| ni | 2 | 4 | 8 | 2 | 4 |
2) Рассчитаем суммарный размер выборки: n=2+4+8+2+4=20. Определим относительные частоты, для этого используем формулы: ni/n=wi: wi=2/20=0.1; w2=4/20=0.2; w3=0.4; w4=4/20=0.1; w5=2/20=0.2. Теперь зафиксируем в таблице распределение относительных частот:
| xi | 70 | 71 | 72 | 73 | 74 |
| wi | 0.1 | 0.2 | 0.4 | 0.1 | 0.2 |
Контрольная сумма должна равняться единице: 0,1+0,2+0,4+0,1+0,2=1.
Полигон частот
Название «полигоном частот» применяют для обозначения ломаной линии, каждый отрезок, которой соединяют точки $(х_1,n_1),(х_2,n_2),…,(х_k,n_k)$. Для построения на графике полигона частот по оси абсцисс отмечают варианты $х_2$, при этом на оси ординат отсчитывают– соответствующие частоты $n_i$. Когда полученные точки $(х_i,n_i)$ соединяются с помощью отрезков, то автоматически получают полигон частот.
Статистический интервальный ряд распределения.
Статистическим дискретным рядом (или эмпирической функцией распределения) обычно пользуются, если число различающихся вариант в полученной выборке не слишком большое. Также применение возможно, когда дискретность имеет важное значение для экспериментатора. В тех случаях, когда важный для задачи признак генеральной совокупности Х распределяется непрерывным образом, либо его дискретность нет возможности учесть, то варианты предпочтительнее всего группировать, чтобы получить интервалы.
Статистическое распределение допустимо задавать в том числе в качестве последовательности интервалов и частот, соответствующих этим интервалам. При это за частоту какого-либо интервала принимается сумма всех частот, вошедших в данный интервал.
Особенно следует отметить ,что $h_i-h_{i-1}=h$ при всех i, т.е. группировка проводится с равным шагом h. Также в вопросе группировки можно ориентироваться на ряд полученных опытным путём рекомендацийу, касающихся таких параметров, как а, k и $h_i$:
1. $Rраз_{мах}=X_{max}-X_{min}$
2. $h=R/k$; k-число групп
3.$ kgeq 1+3.321lgn$ (формула Стерджеса)
4. $a=x_{min}, b=x_{max}$
5.$ h=a+h_i, i=0,1…k$
Определённую в ходе решения задачи группировку удобнее всего скомпоновать и перевести в вид специальной таблицы, которая также может именоваться — «статистический интервальный ряд распределения»:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Частоты | n1 | n2 | … | nk-1 | nk |
Таблицу подобного вида можно сделать, поменяв частоты $n_i$ на относительные частоты:
| Интервалы группировки | [h0;h1) | [h1;h2) | … | [hk-2;hk-1) | [hk-1;hk) |
| Отн. частоты | w1 | w2 | … | wk-1 | wk |

236
проверенных автора готовы помочь в написании работы любой сложности
Мы помогли уже 4 396 ученикам и студентам сдать работы от решения задач до дипломных на отлично! Узнай стоимость своей работы за 15 минут!
Пример 2
На склад пришла крупная партия деталей. Из них методом случайного отбора взято 50 экземпляров. Рассматривая изделия по одному, особенно интересующему признаку — размеру, определённому с точностью до 1 см, получим следующий вариационный ряд: 22, 47, 26, 26, 30, 28, 28, 31, 31, 31, 32, 32, 33, 33, 33, 33, 34, 34, 34, 34, 34, 35, 35, 36, 36, 36, 36, 36, 37, 37, 37, 37, 37, 37, 38, 38, 40, 40, 40, 40, 40, 41, 41, 43, 44, 44, 45, 45, 47, 50. Требуется произвести расчёт и определить статистический интервальный ряд распределения.
Решение
Найдём параметры выборки используя сведения из условия задачи.
$k geq1+3,321cdot lg50=1+3.32lg(5cdot10)=1+3.32(lg5+lg10)=6.6$
Получили a=22, k=7, h=(50-22)/7=4, hi=22+4i, i=0,1,…,7.
| Интервалы группировки | 22-26 | 26-30 | 30-34 | 34-38 | 38-42 | 42-46 | 46-50 |
| Частоты | 1 | 4 | 10 | 18 | 9 | 5 | 3 |
| Отн. частоты | 0.02 | 0.08 | 0.2 | 0.36 | 0.18 | 0.1 | 0.06 |
Десятичные логарифмы от 1 до 10
| n | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| lnn≈ | 0 | 0.3 | 0.48 | 0.6 | 0.7 | 0.78 | 0.85 | 0.9 | 0.95 | 1 |
Не получается написать работу самому?
Доверь это кандидату наук!
