Помогите, пожалуйста! Яндекс выкинул из поиска почти все страницы, которые были топовыми по запросам. Сайту 1 год, проблем никаких не было. Поисковик расценил эти страницы как дубли на главную страницу сайта. Вот сам сайт Ссылка
Какие это дубли, если тексты, заголовки совершенно разные? Если про ошибки сервера, то на этом же хостинге есть еще один сайт, на таком же движке, настроен аналогичным образом, меню и виджеты созданы аналогичным образом, но его проблема не коснулась.
Установлен плагин All in one seo pack, поставлены галочки на Канонические url и Запретить пагинацию для канонических URL. Могло ли это повлиять на выброс страниц из поиска как дублей?
В роботс также есть настройки запрета дублей, может некоторые из них некорректны и надо что-то исправить?
User-agent: *
Disallow: /cgi-bin
Disallow: /wp-
Disallow: /?
Disallow: /search/
Disallow: *?s=
Disallow: *&s=
Disallow: /trackback
Disallow: */trackback
Disallow: */*/trackback
Disallow: */feed
Disallow: /feed/
Disallow: /?feed=
Disallow: */*/feed
Disallow: */*/feed/*/
Disallow: /*?*
Disallow: /tag
Disallow: /tag/*
Disallow: /?s=*
Disallow: /page/*
Disallow: /author
Disallow: /2015
Disallow: */embed
Disallow: *utm=
Disallow: *openstat=
Disallow: /tag/ #
Disallow: /xmlrpc.php
Allow: */uploads
User-agent: GoogleBot
Disallow: /cgi-bin
Disallow: /?
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Disallow: *utm=
Disallow: *openstat=
Allow: */uploads
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Allow: /wp-*.jpg
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /wp-admin/admin-ajax.php
User-agent: Yandex
Disallow: /cgi-bin
Disallow: /?
Disallow: /wp-
Disallow: *?s=
Disallow: *&s=
Disallow: /search/
Disallow: /author/
Disallow: /users/
Disallow: */trackback
Disallow: */feed
Disallow: */rss
Disallow: */embed
Disallow: /xmlrpc.php
Allow: /wp-*.jpg
Allow: /wp-admin/admin-ajax.php
Allow: */uploads
Allow: /wp-*.jpeg
Allow: /wp-*.gif
Allow: /*/*.js
Allow: /*/*.css
Allow: /wp-*.png
Clean-Param: utm_source&utm_medium&utm_campaign
Clean-Param: openstat
Кстати, от рег ру приходило такое сообщение:
Технические работы
Здравствуйте! Вас приветствует Регистратор доменныx имен REG.RU!
Уважаемые клиенты!
Информируем вас о том, что 03.10.2018 года в период с 00:00 до 06:00 часов по московскому времени будут проводиться плановые работы по обновлению программного обеспечения серверов:
ххх.hosting.reg.ru
на которых располагаются следующие услуги:
- Web-хостинг (тариф ххх) для ххх
Планируемое время проведения технических работ в указанный период составит порядка 1 часов и 0 минут. В течение этого времени все сайты и сервисы на данном сервере будут недоступны.
Приносим свои извинения за возможные неудобства.
И привожу теперь скопированное из вебмастера (может, это технические работы на сервере повлияли? но другой сайт без проблем индексируется):
|
Обновление |
Статус и URL |
Последнее посещение |
Заголовок |
|---|---|---|---|
| 12.10.2018 |
/kontakty/ Дубль |
07.10.2018 | |
|
/peskostruynaya-kamera-apparat-dlya-peskostruya/ Дубль |
07.10.2018 | ||
| 10.10.2018 |
/rezinotehnicheskie-izdeliya/konveyernaya-lenta-bknl-tk/ Дубль |
06.10.2018 | |
|
/rezinotehnicheskie-izdeliya/remen-ventilyatornyy-klinovoy/ Дубль |
06.10.2018 | ||
| 07.10.2018 |
/ceny-na-elektromontazhnye-uslugi-vyzov-elektrika-voronezh/ Дубль |
04.10.2018 | |
|
/elevatornoe-oborudovanie/ Дубль |
03.10.2018 | ||
|
/elevatornoe-oborudovanie/konveyer-lentochnyy-skrebkovyy-shnek/ Дубль |
03.10.2018 | ||
|
/elevatornoe-oborudovanie/noriynyy-bolt-gayka-shayba/ Дубль |
03.10.2018 | ||
|
/elevatornoe-oborudovanie/noriynyy-kovsh-polimer-metall/ Дубль |
03.10.2018 | ||
|
/elevatornoe-oborudovanie/rolik-konveyernyy/ Дубль |
04.10.2018 | ||
|
/elevatornoe-oborudovanie/samoteki-zernovye/ Дубль |
04.10.2018 | ||
|
/poroshkovaya-kamera-pech-polimerizacii-poroshkovo-polimernaya-pokrasochnaya-liniya/ Дубль |
03.10.2018 | ||
|
/poroshkovaya-polimernaya-pokraska-peskostruynaya-obrabotka-metalla-diskov-dereva-stekla/ Дубль |
03.10.2018 | ||
|
/remont-peremotka-elektrodvigateley/ Дубль |
03.10.2018 | ||
|
/rezinotehnicheskie-izdeliya/remen-privodnoy-klinovoy/ Дубль |
04.10.2018 | ||
|
/ventilyator-voe-5-krylchatka-rabochee-koleso-lopatka/ Дубль |
03.10.2018 |
Полное руководство от Яндекса: Поиск и устранение дублей сайта
- 16.03.2018
-
Eye
4 707 -
Chatbubbles
0 -
Categories
SEO, Яндекс

- Причины появления дублей
- Поиск дублей
- Устранение дублей
- Ответы на вопросы
Для начала посмотрим, в чем же заключается опасность дублирующих страниц на сайте, попробуем найти дубли на ресурсе и их устранить для того, чтобы в будущем они не появлялись.
Опасность дублей на сайте
Перед тем как говорить о дублях, хочется дать определение, что же такое дублирующая страница сайта. Под дублями мы понимаем несколько страниц одного ресурса, который содержит в достаточной мере идентичный текстовый контент. Хочу обратить ваше внимание, что речь мы ведем только об одном ресурсе и говорим о текстовом контенте в том плане, что подразумеваем, что робот при определении дублирующих страниц смотрит только на текстовое содержимое страниц вашего сайта. Он не проверяет дизайн, либо изображение на данных страничках, а смотрит только на текст. В большинстве случаев дублирующие страницы – это одна и та же страница сайта, доступная по нескольким адресам.
Причины появления дублей
Причин появления дублей на сайте огромное количество.

Все они связаны с различными ошибками. Например, ошибки в содержимом страниц, когда некорректно указаны относительные ссылки, ошибки, связанные с отсутствием, либо недостаточным количеством текста на страницах, некорректные настройки 404 кода ответа, либо доступность служебных страниц сайта, либо особенности работы CMS, которую вы используете. Это большое количество дублирующих страниц зачастую гнетет вебмастеров, и они откладывают работу над дублями в долгий ящик и не хотят этим заниматься.
Проблемы, к которым приводят дубли
Но на самом деле делать этого не стоит, поскольку наличие дублей может привести к различным проблемам. Их можно разделить на три большие группы:
- Во-первых, это смена релевантной страницы в результатах поиска.
- Во-вторых, обход роботом большого количества дублирующих страниц вместо того, чтобы индексировать нужные странички сайта.
- И, в-третьих, это проблема со сбором статистики на вашем ресурсе.
Давайте рассмотрим более подробно каждую проблему.
Смена релевантной страницы

Я взял сразу пример из практики. На сайте есть страничка с бухгалтерскими услугами, которая доступна по двум адресам. Первый адрес находится в разделе «услуги», а второй адрес – это страничка в корне сайта. Контент данных страничек абсолютно одинаков. Поскольку робот не хранит в своей базе сразу несколько идентичных документов, он выбирает самостоятельно страницу для включения в поисковую выдачу. Кажется, что, по сути, не должно произойти ничего плохого, ведь странички абсолютно похожи между собой. Но вы же опытные вебмастера и знаете, что позиции конкретной страницы по запросам рассчитываются на основании нескольких сотен показателей. Поэтому при смене страницы в поисковой выдаче ее позиции могут измениться.

Как произошло и в нашем случае. По конкретному запросу «услуги бухгалтерского отчета» видно, что в середине июня произошло проседание позиций. Это как раз связано с тем, что сменилась релевантная страница в поисковой выдаче и спустя несколько дней, в районе 19 сентября, позиции восстановились, поскольку в поиск вернулась нужная страница сайта, который участвовал в выдаче до этого. Согласитесь, даже такое небольшое изменение позиций сайта может очень сильно повлиять на трафик, на ваш ресурс.
Обход дублирующих страниц

Вторая причина, по которой необходимо бороться с дублями, связана с тем, что робот начинает посещать большое количество дублирующих страниц. Поскольку количество запросов со стороны индексирующего робота ограничено, например, производительностью вашего сервера или CMS, вами с помощью директивы Crawl-delay, а также роботом, то при большом количестве дублирующих страниц начинает скачивать именно их вместо того, чтобы индексировать нужные вам страницы сайта.

В результате, в поисковой выдаче могут показываться неактуальные данные, и пользователи, переходя на ваш ресурс, не будут видеть информацию, которую вы размещали на сайте.

Тоже пример из практики по обходу дублирующих страниц. Очень большой интернет-магазин, где видно, что до конца мая робот каждый день скачивал чуть меньше 1 миллиона страниц с сайта. После обновления ресурса и внесения изменений на сайт видно, что робот резко увеличил нагрузку на ресурс и начал скачивать несколько миллионов страниц. Огромные цифры.

Если посмотреть, что именно скачивает индексирующий робот, то можно увидеть, что большое количество – этот желтый пласт, несколько десятков миллионов – это как раз дублирующие страницы. Их примеры можно будет посмотреть ниже:

Это страницы с некорректными параметрами, get параметрами в URL-адресе. Такие странички появились из-за некорректного обновления CMS, используемой на сайте.
Затруднение сбора статистики

И третья проблема, к которой могут привести дублирующие страницы – это проблемы со сбором статистики на вашем сайте. Например, в Яндекс. Вебмастере, либо в Яндекс. Метрике.

Если говорить о Яндекс. Вебмастере, то в разделе «Страницы в поиске» вы можете наблюдать такую картину. При каждом обновлении поисковой базы количество страниц в поиске остается практически неизменным, но видно, что робот на верхнем графике при каждом добавлении, добавляет и удаляет примерно одинаковое количество страниц. Происходит процесс, постоянно что-то добавляется/удаляется, но при этом в поиске количество страниц остается неизменным. Странная ситуация.
Смотрим раздел «Статистика обхода»:

Ежедневно робот посещает несколько тысяч новых страниц сайта. Это только новые страницы. При этом данные страницы при поисковой выдаче, как видно на графике ниже, опять-таки не попадают. Это опять же связано с обходом дублирующих страниц, которые потом в поисковую выдачу не включаются.

Если вы используете Яндекс. Метрику для сбора статистики посещаемости конкретной страницы, то может возникнуть следующая ситуация. Данная страница показывалась ранее по конкретному запросу и на нее были переходы из результатов поиска. Но видно, что в начале мая данные переходы прекратились. Страничка перестала показываться по запросам посетителей, пользователей поисковой системы перестали переходить по ней. Что же произошло на самом деле? В поисковую выдачу включилась дублирующая страница и пользователи поиска переходят именно на нее, а не на нужную страницу, за которой вы наблюдаете с помощью Яндекс. Метрики.
Проблемы, к которым приводят дубли
В результате три больших проблемы, к которым могут привести дублирующие страницы вашего сайта:
- Это смена релевантной страницы.
- Обход дублирующих страниц вместо нужных.
- Проблемы со сбором статистики
Согласитесь, три больших проблемы, которые должны вас как-то мотивировать к работе над дублирующими страницами сайта. Но чтобы что-то предпринять, сначала нужно найти дубли найти. Об этом следующий раздел.
Поиск дублей
Если немножко изменить довольно-таки популярный диалог, получилось бы следующее: «Видишь дублирующие страницы? – Нет. – И я нет, а они есть». Так же на самом деле, практически на каждом ресурсе в Интернете есть дублирующие страницы, осталось их только найти.
Источник для поиска дублей «Страницы в поиске»
Начнем с самого простого способа, будем искать дубли с помощью раздела «Страницы в поиске» в Яндекс. Вебмастере.

Всего 4 клика, с помощью которых можно увидеть все дублирующие страницы на вашем ресурсе. Первый клик – заходим в раздел «Страницы в поиске», переходим на вкладку «Исключенные страницы»:

Выбираем сортировку и нажимаем кнопку «применить»:
В результате чего на нашем экране видны все страницы, которые исключил робот из поисковой выдачи, поскольку посчитал дублирующими.
Согласитесь, очень легко, 4 клика, быстро, понятно и вот все дублирующие страницы с вашего ресурса удалены.
Если таких дублирующих страниц много, как в нашем случае их несколько десятков тысяч, можно полученную таблицу скачать в Excel’евском формате, либо CSV’шном и дальше использовать в своих интересах. Например, собрать какую-то статистику, посмотреть списком все страницы, которые исключил индексирующий робот.
Источник для поиска дублей «Статистика обхода»

Второй способ – это раздел «Статистика обхода». Соседний раздел, переходим в него, смотрим, что посещает индексирующий робот.

Внизу раздела можно включить сортировку по 200 коду и видно, какие страницы доступны для робота и какие страницы посещает робот. В этом разделе можно увидеть не только дублирующие страницы, но и различные служебные страницы сайта, которые так же индексировать не хотелось бы.
Источник для поиска дублей «Ваша фантазия»

Третий способ посложнее и вам нужно будет применить свою фантазию. Берем любую страницу на вашем сайте и добавляем к ней произвольный get-параметр. В данном случае к странице добавили параметр test со значением 123. Используемый инструмент – «проверка ответа сервера», нажимаем кнопку «Проверить» и смотрим код ответа от данной страницы. Если такая страница доступна, как в нашем случае, отвечает кодом ответа 200, это может привести к появлению дублирующих страниц на вашем сайте. Например, если робот найдет такую ссылку где-то в Интернете, он проиндексирует и потенциально страница может стать дублирующей, что не очень хорошо.
Источник для поиска дублей «Проверить статус URL»

И четвертый способ, с которым я надеюсь вы никогда не столкнетесь после сегодняшнего вебинара – это инструмент «Проверить статус URL». В ситуации, если нужная вам страница уже пропала из результатов поиска, вы можете использовать этот инструмент, чтобы посмотреть по каким причинам это произошло. В данном случае видно, что страница была исключена из поисковой выдачи, поскольку дублирует уже представленную в поиске страницу сайта, и вы видите соответствующую рекомендацию.
Источник для поиска дублей

Четыре простых способа, которые может использовать каждый вебмастер, каждый владелец сайта с помощью сервиса Яндекс. Вебмастер. Кажется, все очень легко и просто, я думаю, что никаких проблем у вас не возникнет. Но помимо этих четырех способов вы можете использовать свои способы, например, посмотреть логи вашего сервера, к каким страницам обращается робот и посетители, посмотреть статистику Яндекс. Метрики, а также поисковую выдачу. Возможно, там получится найти дублирующие страницы вашего ресурса.
После того, как мы нашли дубли, с ними нужно что-то делать, каким-то образом работать. Об этом следующий раздел.
Устранение дублей

Все дубли можно разделить на две большие группы:
- Это явные дубли. Это страницы одного сайта, которые содержат абсолютно идентичный контент.
- Это неявные дубли. Это страницы с похожим содержимым одного сайта.
Внутри этих больших групп представлено огромное количество видов конкретных дубей. Сейчас мы с вами обсудим каким образом можно их устранить.
Дубли: со слэшом в конце и без

Самый простой вид дублей – это страницы со слэшом в конце адреса и без слэша, как указано в нашем примере. Самый простой вид дублей и, естественно, простое их решение, устранение этих дублей. Для таких дублирующих страниц мы советуем использовать 301 серверное перенаправление с одного типа адресов на другой тип страниц. Вы спросите, а какие страницы нужно оставить для робота?
Здесь решение принимать только вам. Вы можете посмотреть результаты поиска и увидеть какие именно страницы вашего сайта присутствуют в поисковой выдаче на данный момент. Если сейчас индексируются и участвуют в поиске страницы без слэша, соответственно, со страниц со слэшом можно установить перенаправление на нужные вам. Это прямо укажет роботу на то, какие именно страницы нужно индексировать и включать в поисковую выдачу. Настроить редирект можно разными способами – с помощью служебного файла htaccess, либо в настройках CMS выбрать формат адресов.
Дубли: один товар в двух категориях

Второй вид дублей – это один и тот же товар, который находится в нескольких категориях. В данном случае у нас товар – мяч, он доступен по адресу с категорией, игрушки/мяч и доступен так же в корневой папке вашего сайта. Для робота, поскольку эти страницы абсолютно одинаковые, это как раз дубли. В такой ситуации я советую вам использовать атрибут rel=” canonical” с указанием адреса канонической страницы, ту страницу, которую необходимо включать в поисковую выдачу. Это будет прямое указание для робота, и в поиске будет участвовать именно нужный вам адрес.
Какой адрес выбирать? В такой ситуации стоит подумать о посетителях вашего сайта. Посмотрите, какой формат адресов будет удобен и поможет им лучше ориентироваться на вашем сайте при просмотре адресов, понимать, в какой категории, например, они находятся.
Дубли: версии для печати
Следующий пример дублирующих страниц – это страницы «Версии для печати»:

В качестве примера я взял страницу одного сайта, в котором собраны тексты песен. Видно, что с левой стороны у нас версия для обычных пользователей с дизайном, с фоном, со стилями, а с правой стороны – версия для печати для того, чтобы было удобно распечатать эту страничку на принтере. Поскольку данные страницы доступны по разным адресам, потенциально для робота они тоже дублирующие, потому что текстовое содержимое данных страниц абсолютно похожее.

Для подобных страниц, для того, чтобы дублирование в случае их наличия не возникло, я вам советую использовать запрет в файле robots.txt. Например, как в нашем случае запрет Disallow: /node_print.php* укажет роботу на то, что все страницы по подобным адресам индексировать нельзя. Одно простое правило позволит вам избежать проблем с дублирующими страницами.
Дубли: незначащие параметры
Следующий вид дублей – это страницы с незначащими параметрами.

Незначащие параметры – это те get-параметры в URL-адресе ваших страниц, которые совсем не меняют их содержимое. Посмотрим пример, который я взял. У нас есть страница без параметров – это страничка page, есть вторая страница с utm-метками, например, они используются в рекламных компаниях и есть страничка с параметрами идентификатора сессии, например, если у вас Foon. Поскольку эти параметры абсолютно не меняют контент страницы, для робота это дублирующие страницы сайта.
Для таких ситуаций у нас есть специальная директива Clean-param. Она так же располагается в файле robots.txt и в ней можно перечислить все незначащие параметры, которые используются на вашем сайте. В данном случае у нас два параметра: utm_source и sid. Указали их в директиве Clean-param. Эта директива поможет роботу не только указать на то, что данные параметры являются незначащими, но и укажет роботу на то, что на вашем сайте есть страницы по чистому адресу, без данных get-параметров. Если она была роботу ранее неизвестна, он придет и специально скачает страничку по чистому адресу и включит ее в поисковую выдачу.
Такая сложная логика, но эта логика позволит вам избежать проблем и ситуаций, а нужные вам странички по чистым адресам будут всегда присутствовать в поисковой выдаче. Чего не будет происходить, если вы используете запрет, как указано в примере ниже. В данном случае робот не узнает, что на вашем сайте есть такие страницы по чистым адресам. Поэтому для незначащих параметров используйте директиву Clean-param.
Дубли: страницы действий
Очень близко по смыслу это страницы действий на вашем сайте.

Например, если пользователь на вашем ресурсе добавляет товар в корзину, либо сравнивает его с другими товарами, возможно, перемещается по страницам с комментариями, добавляются дополнительные служебные параметры, которые характеризуют действия на вашем сайте. При этом контент на таких страницах может совсем не меняться, либо может меняться совсем незначительным способом.
Чтобы робот совсем не посещал такие страницы, не добавлял их в свою базу, для данных случаев советую использовать запрет в файле robots.txt. Вы можете перечислить в директиве Disallow по отдельности каждый из параметров, который характеризует действия на сайте, либо, если совсем не хотите, чтобы страницы с параметрами индексировались, используйте правила, которые указаны ниже. Одно такое правило позволит сразу избежать возможных проблем из-за наличия таких страниц действий.
Дубли: некорректные относительные адреса

В случае, если на вашем сайте, как в примере, о котором ранее я говорил, в интернет-магазине появились некорректные относительные адреса, то, примерно, у вас возникнет следующая ситуация. У вас одна и та же страничка, например, как наш мячик, будет находиться в разделе игрушки/мяч, так и станет доступна по большому количеству вложенностей этой категории. В данном случае – несколько раз повторяется категория «игрушки» и потом «мяч». И в конце обычные пользователи, и роботы видят товар, который находится на исходном адресе.
Во-первых, чтобы побороть такие страницы, стоит разобраться с причинами их появления. Просмотреть исходный код страниц вашего сайта и проверить, корректно ли вы используете относительные ссылки на вашем ресурсе. После того, как ошибку нашли, настройте возврат 404 кода на запрос индексирующего робота к таким страницам. Это сразу позволит избежать дублирования информации.
Дубли: похожие товары
Следующий вид дублей, он же относится и к неявным дублирующим страницам – это похожие товары.

Как правило, в интернет-магазинах один и тот же товар доступен в нескольких вариантах. Например, разного размера, цвета, мощности, все, что угодно. В большинстве случаев такие товары доступны по отдельным URL-адресам. Что, естественно, затрудняет работы индексирующего робота, поскольку, по сути, эти странички практически ничем не отличаются, поэтому для таких страниц я советую использовать один URL-адрес, по которому сразу можно выбрать варианты исполнения данного товара, размер, либо цвет.
Это позволит не только роботу хорошо ориентироваться на вашем ресурсе и позволит избежать дублирования информации, но и облегчит посетителям переходы по страничкам. Не нужно будет возвращаться обратно в каталог, выбирать нужный вариант, вы можете установить селектор, и ваши пользователи на одной странице смогут сразу выбрать тот вариант, который им нужен.
Если такой возможности нет, нет возможности разместить этот селектор, вы можете добавить на такие страницы, на страницы с вариантами, дополнительное какое-то описание, расписать, почему такая мощность и для каких вариантов она подходит, почему такой цвет лучше, чем другой цвет, может быть, оттенками отличается. Добавить различные отзывы покупателей, которые купили именно тот или иной вариант цвета. Так же вы можете закрыть с помощью тега noindex служебные текстовые части страниц. Это укажет роботу на то, что контентная страница на самом деле отличается и нужно в поисковую выдачу включать оба или несколько вариантов страниц.
Дубли: фото без описания
Очень похожие по смыслу – это страницы с фотографиями без описаний.
Например, если у вас фотогалерея, либо фотобанки. Что делаем для таких страниц? Добавляем либо какое-то текстовое описание, либо различные теги, которые будут характеризовать фотографию, которая размещена на страничке.
Дубли: фильтры и сортировки

Давайте к следующему варианту дублей – это страницы фильтров и сортировки. Например, когда на вашем сайте в каталоге можно отсортировать товары по цене, размеру, материалу. Для начала, при работе над такими страницами нужно подумать, полезны ли они пользователям поисковой системы или нет, в достаточной ли мере хорошо они отвечают на конкретные запросы пользователей.
Например, если у вас есть страница с сортировкой дешевых кондиционеров, а пользователи как раз и ищут дешевые кондиционеры, конечно, такие страницы стоит оставить доступными, они будут полезны пользователям поисковой системы. Если такие странички не нужны, я советую вам их запрещать в файле robots.txt. Как в примере ниже, страницы всей сортировки, размеров и фильтрации запретили с помощью директив Disallow. Это оставит для робота только нужные страницы вашего сайта, что ускорит их индексирование.
Дубли: страницы пагинации

Очень близко по смыслу – это страницы пагинации.
Но рекомендации здесь другие. Если ваш каталог достаточно большой и у вас много различных товаров, вы, скорее всего, используете пагинацию для того, чтобы пользователям было удобнее ориентироваться в каталоге и не видеть сразу все товары, представленные на вашем сайте. В таком случае мы рекомендуем размещать атрибут real=”canonical” с указанием канонической страницы, в данном случае это первая страница каталога, которая будет индексироваться и помазываться в поисковой выдаче. Пользователи, переходя из поиска, так же будут попадать на заглавную стартовую страницу конкретного раздела вашего каталога.
Как работать с дублями

При работе над дублями обязательно:
- Не недооцениваете риски, к которым могут привести дублирующие страницы на вашем сайте.
- Нашли дубли в Яндекс. Вебмастере, применили к ним различные изменения на вашем ресурсе, чтобы дубли в последующем не появлялись в поисковой выдаче.
- Следить за дублирующими страницами вы так же можете в разделе «Страницы в поиске», а с помощью инструмента «Важные страницы» можно смотреть за статусом наиболее востребованных страниц вашего сайта, что тоже очень полезно для того, чтобы моментально отреагировать на появление дублирующих страниц.
Полезное:
- Настройка индексирования сайта в Яндексе: от теории к практике
- Как поиск находит страницу сайта? Описание процесса индексации страниц сайта
Ответы на вопросы
«Если для пагинации задействовать real canonical, то как узнает робот о товарах на страницах далее первой?».
Неканонические страницы посещаются индексирующим роботом. Он же действительно должен узнать о товарах на таких страничках. Поэтому не переживайте, на индексирование товаров, которые размещены на второй, третьей и далее страницах пагинации, робот обязательно узнает, проиндексирует.
«У нас на сайте есть раздел с пресс-релизами. После публикации пресс-релиза на нашем сайте, мы размещаем тот же пресс-релиз на других ресурсах в Интернете. В результате страницы с пресс-релизом на нашем сайте получают статус недостаточно качественных, а пресс-релиз на спец. ресурсах нормально появляется в выдаче. Как сделать, чтобы текст нашего пресс-релиза был в поиске с нашего сайта и со специального сайта агрегатора?».
Во-первых, под дублями мы понимаем две странички одного и того же ресурса. В вашем случае речь идет о страницах абсолютно разных сайтов. Посмотрите, насколько ваша страница удобна для пользователей поисковых систем. Действительно текстовое содержимое агрегатора и вашего сайта может быть абсолютно одинаковым, но посмотрите, чем отличается навигация. Возможно, вам стоит пересмотреть навигацию, либо добавить более полезный и интересный материал для ваших пользователей: смежные темы, разделы, какую-то дополнительную информацию. Возможно, пользователи выбирают агрегатор по той причине, что на нем можно сразу увидеть смежные категории или смежную информацию.
«У какого параметра выше приоритет – Clean-param или у Disallow? Если присоединить Disallow, а потом Clean-param, что будет работать?»
Будет работать Disallow, потому что он запрещает индексировать роботу конкретные страницы. Он даже не будет совсем к ним обращаться. В зависимости от того, какой у вас дубль или какие служебные параметры вы используете. Выбирайте либо первый, либо второй вариант.
«Является ли дублем страница с одинаковым набором get-параметров, но расположенных в разном порядке?».
Да, для робота такие страницы могут быть дублирующими.
«У меня интернет-магазин, в котором около пяти миллионов страниц, в поиске примерно 500 тысяч и 1,5 миллиона дублей. Дубли в нашем случае появляются из-за использования get параметров и огромного количества utm меток. Я закрываю их в robots.txt, уходит из индекса, но опять появляется. А бывает и так, что очень многие не уходят из индекса, хотя в robots.txt были запрещены. Как часто робот обходит файл robots.txt, почему такие задержки и неучтенные директивы Disallow?».
Давайте начнем с конца вопроса. Файлик robots.txt индексирующий робот обновляет примерно два раза в сутки, поэтому о внесенных вами правилах он узнает достаточно быстро. В поисковой выдаче те изменения, которые вы внесли, применяются в течение недели-полутора, в зависимости от частоты обновления поисковой базы. Если даже по прошествии этого времени робот все равно включает запрещенные страницы в поисковую выдачу, проверьте, а действительно ли запрет установлен корректно. В Яндекс. Вебмастер есть инструмент «Анализ робота robots.txt», укажите в нем адрес вашего сайта и проверьте, а действительно ли запрет установлен корректно.
«Что делать, если за дубль страниц робот принимает схожие товары. Отличия title и заголовков, но схожее описание. Неужели нужно уникализировать каждый товар? Что делать, если их тысячи?».
Как раз это примеры, которые я вам говорил во время презентации. Посмотрите, если вам сложно уникализировать товар всю тысячу вариантов или вариаций, начните с того, какие товары у вас лучше продаются на сайте, которые будут полезнее вам в поисковой выдаче. Например, наиболее распространенный вариант товара или какая-то позиция, которая лучше всего продается. Начните писать уникальные описания для таких страниц, продолжите постепенно по уменьшению популярности. Возможно, вам не нужны все тысячи страниц в результатах поиска, возможно, их никто не ищет и вам нужно написать всего несколько десятков хороших описаний для товаров. Так же, как вариант, вы можете запретить общие фрагменты на странице с помощью тега noindex, чтобы робот увидел, что их текстовый контент действительно отличается.
«Есть ли разница для поискового робота, когда проблема дублей решается с помощью 301 редиректа или rel canonical? Что лучше?».
Как я говорил, в зависимости от ситуации лучше тот или второй вариант.
«Повторите, пожалуйста, для чего нужен clean-param в случае незначащих параметров».
Clean-param нужен в случае незначащих параметров. В чем его отличительная особенность? Индексирующий робот, если сталкивается со страницами с незначащими параметрами и видит директиву Clean-param, идет в свою внутреннюю базу и проверяет наличие страницы по чистому адресу, без данных параметров в адресе. Если такая страница не проиндексирована по каким-то причинам, он старается ее проиндексировать и в случае успеха включает именно ее в поисковую выдачу. Страницы с незначащими параметрами в поиск не попадают
«Что посоветуете по настройке индексации форумов? Что стоит запретить, разрешить? По моим наблюдениям, робот активно индексирует одну-две страницы форума и не особо индексирует последующие. Так ли это?».
На самом деле для робота это совсем разные странички, страницы пагинации на форуме. Для форума такие страницы стоит оставить, потому что их содержимое отличается, разные сообщения на первой и второй странице пагинации. По поводу запретов, на одном из предыдущих вебинаров я рассказывал, что именно стоит запрещать к индексированию на этих сайтах. Это так же применимо и к форумам – все служебные страницы, страницы фильтров, сортировки.
«После исправления дублей как быстро обновиться информация у вебмастера на странице в поиске?».
Обычно изменения начинают происходить в течении недели после внесения изменений на ваш сайт. Робот начинает отслеживать эти изменения, в поиске они проявляются в течении недели.
«Подскажите, пожалуйста, изначально не могли определиться с тем, как описать URL-адреса – транслитом или кириллицей. В итоге была выбрана кириллица и все URL были на ней. В итоге поняли, что для нас будет лучше перейти на транслит и переделали все URL-адреса на транслит. В поисковых запросах выделяются страницы с кириллицей в URL и с транслитом. URL кириллицы определяется, как 404 и перекидывает на главную страницу сайта. Являются ли эти страницы дублями и удалит ли их робот из поисковых запросов?».
Поскольку контент таких страниц отличается, по одним адресам у вас страницы 404 может быть. С содержимым главной страницы, а по другим – действительно нужные странички вашего сайта, то такие страницы не будут считаться дублирующими страницами. Немножко отойдя от темы, я советую вам в будущем, при смене формата адресов страниц на сайте, использовать 301 серверный редирект со старых страниц на новые страницы.
«Насколько плохо, если страница имеет глубину вложенности 6?».
На самом деле ничего плохого в этом нет. Но нужно понимать, что, в случае, если на вашем сайте нет файла Sitemap, а роботу для того, чтобы узнать о наличии этой странички с 6 уровнем вложенности нужно будет скачать 5 других страниц вашего сайта, чтобы узнать о ее наличии. Поэтому в принципе ничего плохого нет, но смотрите за тем, чтобы файлик Sitemap с такой страницей был у вас и робот знал об этом файле.
«Одна и та же статья в основном домене и поддомене рассматривается как дубли?».
Нет, дублирования в данном случае нет.
«Якоря дублями не считаются, так как поддержка мне отписывала когда-то, что они не учитывают такие параметры».
Да, если вы используете именно анкоры в url-адресах, они дублирующими считаться не будут. Для робота это один и тот же адрес страницы.
Источник (видео): Поисковая оптимизация сайта: ищем дубли страниц
 Для Вас есть бесплатная группа ожидания – ХОЧУ В БЛОГЕРЫ (КЕЙСЫ, ФИШКИ, чего нет в свободном доступе…) делюсь практическими советами и присылаю ценную информацию по развитию блогов на поиске.
Для Вас есть бесплатная группа ожидания – ХОЧУ В БЛОГЕРЫ (КЕЙСЫ, ФИШКИ, чего нет в свободном доступе…) делюсь практическими советами и присылаю ценную информацию по развитию блогов на поиске.
А когда будет набор в Школу Блогеров, сообщу Вам заранее. Жду Вас здес…
Здравствуйте коллеги. Пишет Денис Повага. И сегодня важный короткий выпуск. Тем, кто использует SEO Yoast плагин (его используют все в классе блогеров), нужно внести небольшие поправки в файле функций вашей темы. Сделать это необходимо всем ОБЯЗАТЕЛЬНО!
Прежде чем начнем, хочу сказать по поводу набора в нашу школу блогеров. Всё больше и больше просятся в ученики. Но пишу для всех — набор был давно завершен. Мест больше нет!
А теперь, по статье…
Дело в том, что после обновления плагина, пропала возможность исключать мусорные страницы навигации через принудительное добавление мета тега noindex
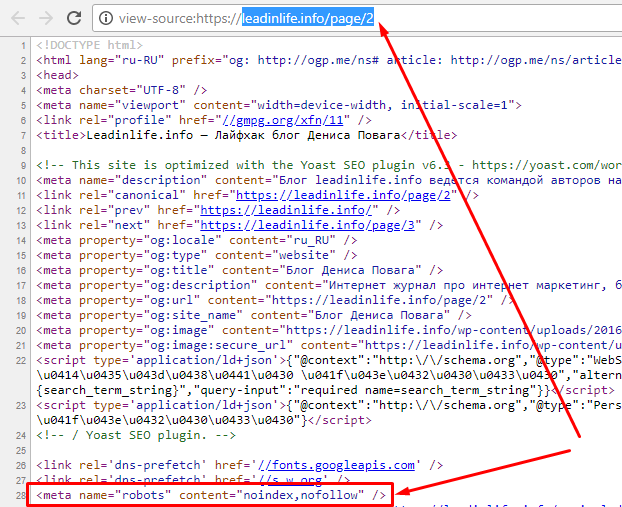
и дело в том, что раньше у плагина передвигался ползунок, на вкладке дополнительно (кто немного заглядывал, мог обратить внимания)… и там всем отключалось при настройке блога — запрет на индексацию страниц вида — …page/2/ …page/3/ …page/4/ …page/5/ и так далее! все эти страницы однотипные по шаблону, и считаются дублирующими, или мусорными. Не несут никакой пользы для сайта. И если у вас на сайте много таких страниц, а их у вас точно уже много, то это приведет к дисбалансу и есть возможность выхватить фильтр от поисковых систем за спам.
Они уже начинают постепенно копиться в индексе поиска… Что не есть хорошо!!!
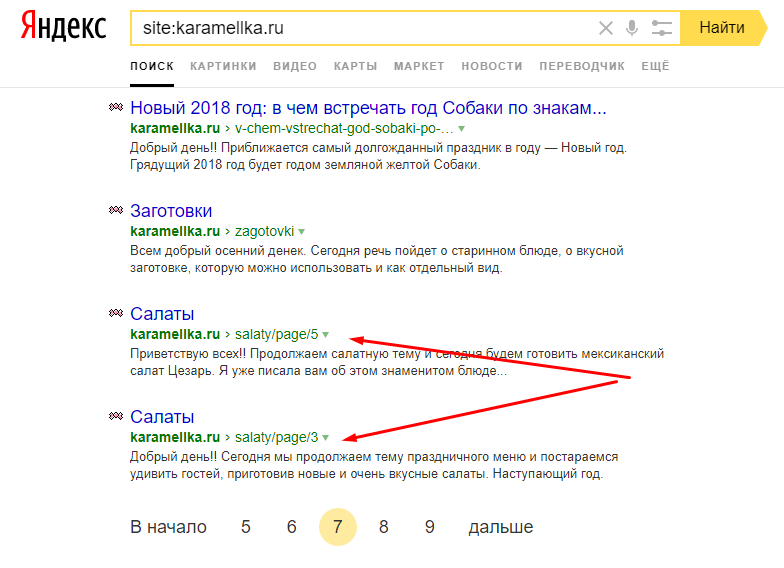
И даже в Яндекс Вебмастере, начинается проявляться проблема. А точнее подсвечивается ошибка:
Страница дублирует уже представленную в поиске страницу…
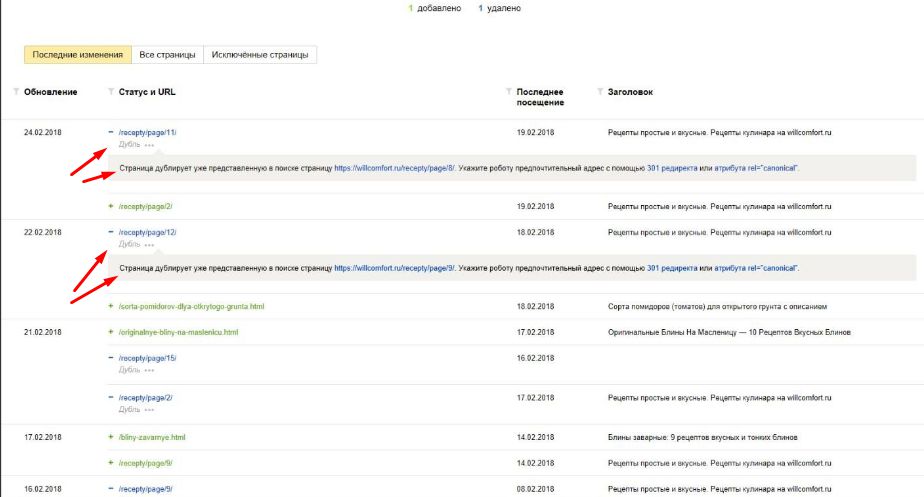
На скрине быть может не совсем всё четко видно. Но суть в том, что проблема имеется!
И важно её исправить… Подобные проблемы — являются критичными для большинства сайтов. На некоторые можно закрывать глаза проблемы, что мы и делаем иногда. Но только не на эту!!!
Если закрыть глаза на эту проблему, то будет понижение сайта в поиске. Это на самом деле критично, и обязательно!!! То, что будет показано ниже, нужно делать всем без исключения…
Те, кто старался, но ничего не вышло — пишите., Помогу! Те, кто не старается даже разобраться, разбирайтесь пожалуйста! Ниже всё показано…
Итак. Что нужно сделать? Всё просто…
Всё просто, как и в прошлом выпуске, идем в файловый менеджер на вашем хостинге переходим в папку с вашей темой (/domains/ваш сайт/public_html/wp-content/themes/colormag) скорее всего, тема стоит colormag или другая… далее открываем файл functions.php.
На спринтхост это здесь:
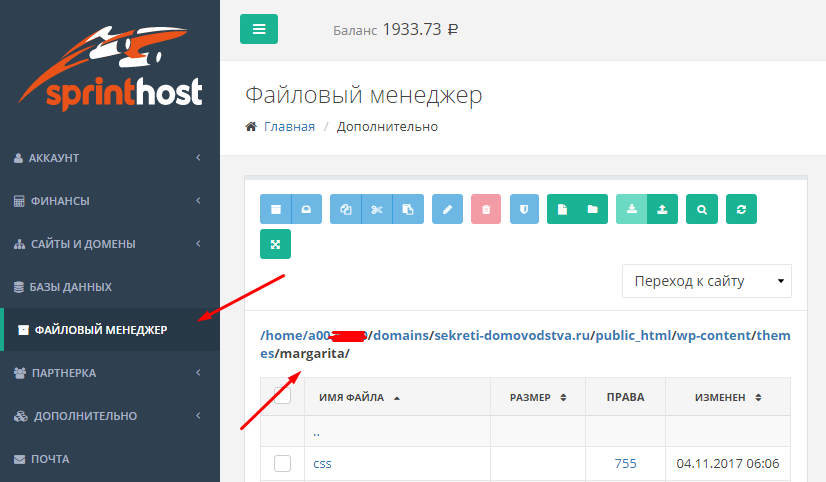
…и ниже будет сам файл functions.php

…и далее, в самом верху найдете вот такую подобную информацию, но у вас скорее всего не будет строчки:
is_paged() OR // Все и любые страницы пагинации
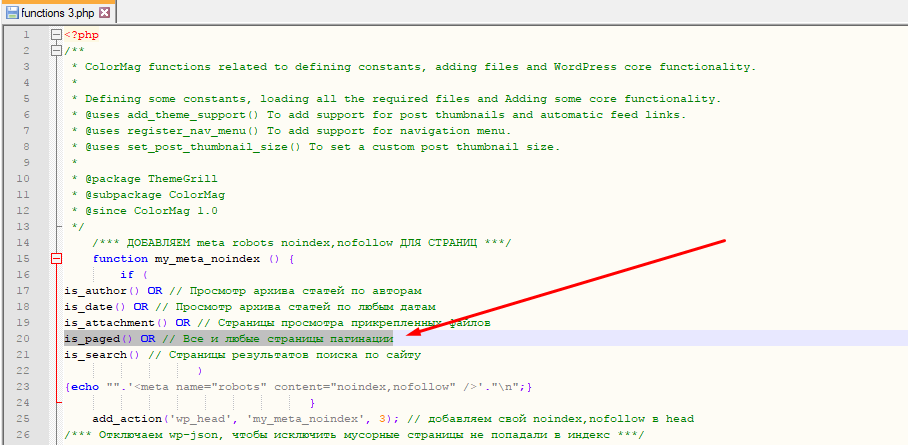
Сделайте также, как на скрине выше. Просто добавьте предпоследнюю строку также:
is_paged() OR // Все и любые страницы пагинации
и после сохраните файл.
Ранее, по курсу вам настраивалось уже исключение запрет лишних страниц их поиска, чтобы они туда не попадали. И на не нужных страницах , в коде добавлялся тот самый мета тег

Так, вот. Чтобы этот мета тег добавился для всех страниц навигации, и нужно сделать также, как показано на этом скриншоте:
Далее сохраняем. И всё готово.
Проверить просто.
Открываем любую страницу навигации:
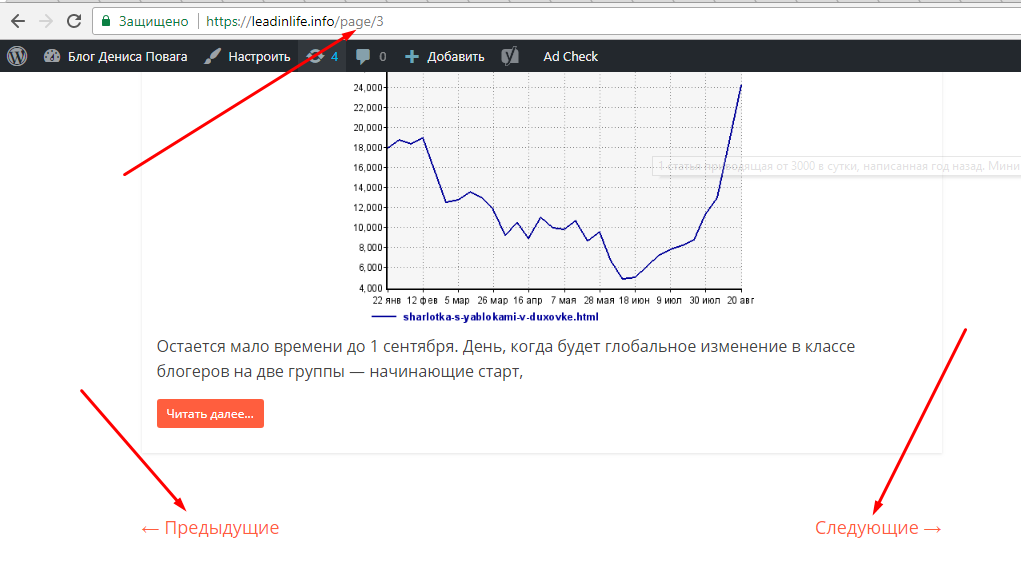
После правой кнопкой мыши нажимаем: «Просмотр кода страницы»
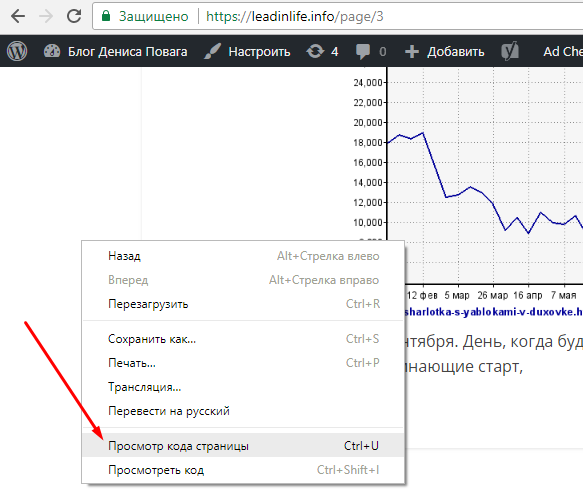
и далее, находим строку
![]()
я её нашел быстро, через поиск (Ctrl+F в браузере), вбил noindex
и увидел полную строку…
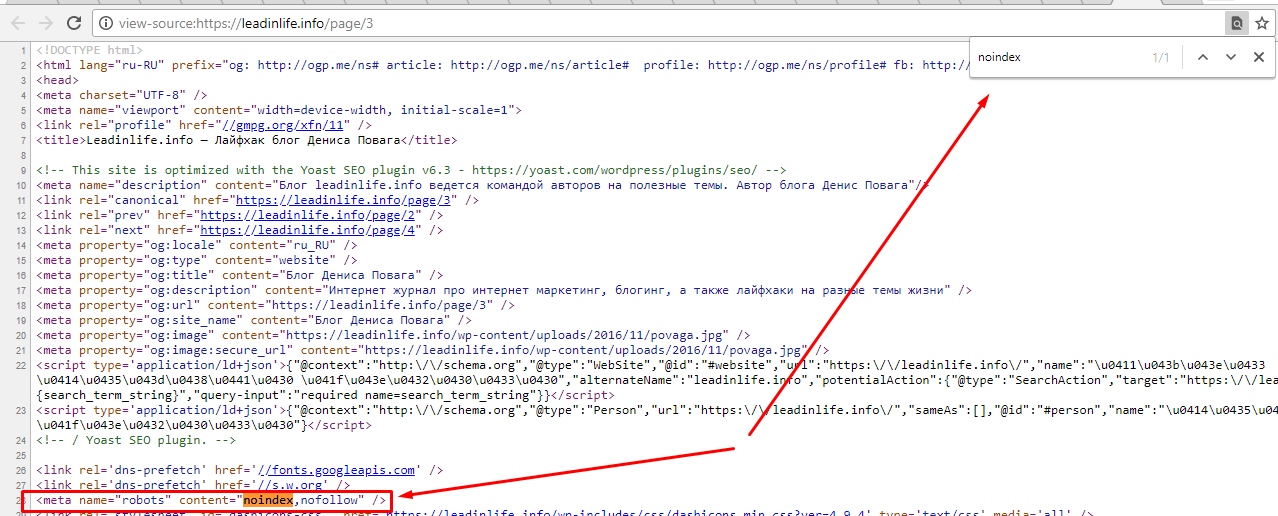
Если эта строка есть хотя бы на одной из страниц навигации — всё отлично!!! Вы справились.
Обратите внимание! В статьях, и на главной страницы, этой строки быть не должно.
Эта строка для поискового робота означает — запрещено индексировать текст данной страницы и переходить по ссылкам на странице:
![]()
На этом всё. Если не получается или возникают вопросы, пишите в комментариях ниже…
p.s. Если у вас близко не то, что вы видите в файле functions.php , то вы скорее всего не среди учеников школы блогеров, и полный код был представлен в моем курсе Редактор Блога, или вот он:
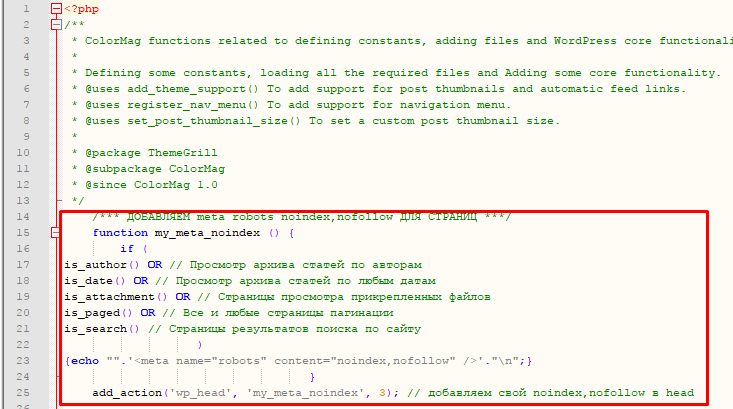
Также, если ваш сайт молодой, и вы при этом беспорядочно и без надобности используете МЕТКИ (теги), то их логично тоже внести в этот список, чтобы не плодить лишние дубли в индексе.
![]()
Информация по первоисточнику уходит корнями в 2012 год. Кому интересно читаем тут: http://alaev.info/blog/post/4143
А также про мета теги яндекса: https://yandex.ru/support/webmaster/controlling-robot/html.html
На этом всё.
С уважением, Денис Повага
Автор публикации

0
1-2 раза в год, веду до результата в блогинге, при наличии мест.
Для связи: ok.ru/denis.povaga
Комментарии: 2964Публикации: 801Регистрация: 12-03-2013
Если страницы сайта доступны по разным адресам, но имеют одинаковое содержимое, робот Яндекса может посчитать их дублями и объединить в группу дублей.
Примечание. Дублями признаются страницы в рамках одного сайта. Например, страницы на региональных поддоменах с одинаковым содержимым не считаются дублями.
Если на сайте есть страницы-дубли:
-
Из результатов поиска может пропасть нужная вам страница, так как робот выбрал другую страницу из группы дублей.
Также в некоторых случаях страницы могут не объединяться в группу и участвовать в поиске как разные документы. Таким образом конкурировать между собой. Это может оказать влияние на сайт в поиске.
-
В зависимости от того, какая страница останется в поиске, адрес документа может измениться. Это может вызвать трудности при просмотре статистики в сервисах веб-аналитики.
-
Индексирующий робот дольше обходит страницы сайта, а значит данные о важных для вас страницах медленнее передаются в поисковую базу. Кроме этого, робот может создать дополнительную нагрузку на сайт.
- Как определить, есть ли страницы-дубли на сайте
- Как избавиться от страниц-дублей
Страницы-дубли появляются по разным причинам:
-
Естественным. Например, если страница с описанием товара интернет-магазина присутствует в нескольких категориях сайта.
-
Связанным с особенностями работы сайта или его CMS (например, версией для печати, UTM-метки для отслеживания рекламы и т. д.)
Чтобы узнать, какие страницы исключены из поиска из-за дублирования:
-
Перейдите в Вебмастер на страницу Страницы в поиске и выберите Исключённые страницы.
-
Нажмите значок
 и выберите статус «Удалено: Дубль».
и выберите статус «Удалено: Дубль».
 и выберите статус
и выберите статус Также вы можете выгрузить архив — внизу страницы выберите формат файла. В файле дублирующая страница имеет статус DUPLICATE. Подробно о статусах
Если дубли появились из-за добавления GET-параметров в URL, об этом появится уведомление в Вебмастере на странице Диагностика.
Примечание. Страницей-дублем может быть как обычная страница сайта, так и ее быстрая версия, например AMP-страница.
Чтобы оставить в поисковой выдаче нужную страницу, укажите роботу Яндекса на нее . Это можно сделать несколькими способами в зависимости от вида адреса страницы.
Контент дублируется на разных URLКонтент главной страницы дублируется на других URLВ URL есть или отсутствует / (слеш) в конце адресаВ URL есть несколько / (слешей)URL различаются значениями GET-параметров, при этом контент одинаковВ URL есть параметры AMP-страницы
Пример для обычного сайта:
http://example.com/page1/ и http://example.com/page2/Пример для сайта с AMP-страницами:
http://example.com/page/ и http://example.com/AMP/page/В этом случае:
-
Установите редирект с HTTP-кодом 301 с одной дублирующей страницы на другую. В этом случае в поиске будет участвовать цель установленного редиректа.
-
Добавьте в файл robots.txt директиву Disallow, чтобы запретить индексирование страницы-дубля.
Если вы не можете ограничить такие ссылки в robots.txt, запретите их индексирование при помощи мета-тега noindex. Тогда поисковой робот сможет исключить страницы из базы по мере их переобхода.
Также вы можете ограничить AMP-страницы, которые дублируют контент страниц другого типа.
Чтобы определить, какая страница должна остаться в поиске, ориентируйтесь на удобство посетителей вашего сайта. Например, если речь идет о разделе с похожими товарами, вы можете выбрать в качестве страницы для поиска корневую или страницу этого каталога — откуда посетитель сможет просмотреть остальные страницы. В случае дублирования обычных HTML и AMP-страниц, рекомендуем оставлять в поиске обычные HTML.
https://example.com и https://example.com/index.phpВ этом случае:
-
Установите редирект с HTTP-кодом 301 с одной дублирующей страницы на другую. В этом случае в поиске будет участвовать цель установленного редиректа.
Рекомендуем устанавливать перенаправление с внутренних страниц на главную. Если вы настроите редирект со страницы https://example.com/ на https://example.com/index.php, контент страницы https://example.com/index.php будет отображаться по адресу https://example.com/ — согласно правилам обработки редиректов.
http://example.com/page/ и http://example.com/pageВ этом случае установите редирект с HTTP-кодом 301 с одной дублирующей страницы на другую. Тогда в поиске будет участвовать цель установленного редиректа.
Не рекомендуем в этом случае использовать атрибут rel=canonical, так как он может игнорироваться. При редиректе пользователи будут попадать сразу на нужный URL страницы.
Если проблема на главной странице, настраивать на ней ничего не нужно. Поисковая система распознает страницы http://example.com и http://example.com/ как одинаковые.
Яндекс индексирует ссылки со слешем на конце и без одинаково. При выборе URL, который останется в поиске, нужно учесть, по какому адресу сейчас индексируются страницы, если редирект еще не был установлен. Например, если в поиске уже участвуют страницы без слеша, стоит настроить перенаправление со страниц со слешем на ссылки без слеша. Это позволит избежать дополнительной смены адреса страниц в поиске.
http://example.com/page////something/В этом случае поисковая система убирает дублирующиеся символы. Страница будет индексироваться по адресу http://example.com/page/something/.
Если в URL есть (например, http://example.com/page/something/\\), поисковая система воспринимает такую страницу как отдельную. Она будет индексироваться по адресу http://example.com/page/something/\\.
В этом случае:
-
Установите редирект с HTTP-кодом 301 с одной страницы на другую. В этом случае в поиске будет участвовать цель установленного редиректа.
-
Укажите предпочитаемый (канонический) адрес страницы, который будет участвовать в поиске.
-
Добавьте в файл robots.txt директиву Disallow, чтобы запретить индексирование страницы.
Если вы не можете ограничить такие ссылки в robots.txt, запретите их индексирование при помощи мета-тега noindex. Тогда поисковой робот сможет исключить страницы из базы по мере их переобхода.
Используйте рекомендации, если различия есть в тех параметрах, которые не влияют на контент. Например, такими параметрами могут быть UTM-метки:
https://example.com/page?utm_source=instagram&utm_medium=cpcВ этом случае добавьте в файл robots.txt директиву Clean-param, чтобы робот не учитывал параметры в URL. Если в Вебмастере отображается уведомление о дублировании страниц из-за GET-параметров, этот способ исправит ошибку. Уведомление пропадет, когда робот узнает об изменениях.
Совет. Директива Clean-Param является межсекционной, поэтому может быть указана в любом месте файла. Если вы указываете другие директивы именно для робота Яндекса, перечислите все предназначенные для него правила в одной секции. При этом строка User-agent: * будет проигнорирована.
- Пример директивы Clean-param
-
#для адресов вида: example.com/page?utm_source=instagram&utm_medium=cpc example.com/page?utm_source=link&utm_medium=cpc&utm_campaign=new #robots.txt будет содержать: User-agent: Yandex Clean-param: utm /page #таким образом указываем роботу, что нужно оставить в поиске адрес https://example.com/page #чтобы директива применялась к параметрам на страницах по любому адресу, не указывайте адрес: User-agent: Yandex Clean-param: utm
Если у вас нет возможности изменить robots.txt, укажите предпочитаемый (канонический) адрес страницы, который будет участвовать в поиске.
http://example.com/page/ и http://example.com/page?AMPВ этом случае добавьте директиву Clean-param в файл robots.txt, чтобы робот не учитывал параметры в URL.
Если AMP-страницы формируются не GET-параметром, а при помощи директории формата /AMP/, их можно рассматривать как обычные контентные дубли.
Робот узнает об изменениях, когда посетит ваш сайт. После посещения страница, которая не должна участвовать в поиске, будет исключена из него в течение трех недель. Если на сайте много страниц, этот процесс может занять больше времени.
Проверить, что изменения вступили в силу, можно в Яндекс Вебмастере на странице Страницы в поиске.
Привет!
Подскажите в чем может быть дело, пожалуйста:
После обновления поисковой базы яндекс исключил из поиска страницы как дубли других, переписывался с сп, сказали что удалил из-за “почти одинакового текстового контента” этих страниц. Печаль в том, что они то не дубли, а совсем разные страницы, и текстового контента на некоторых вообще нет, не пойму с чего роботу так показалось. Вот посмотрите, это из вебмастера:
1)
/foto-i-video-galereya
/spa
Дубль
Страница дублирует уже представленную в поиске страницу http://solnechny.by/spa. Укажите роботу предпочтительный адрес с помощью 301 редиректа или атрибута rel=”canonical”.
2)
/kosmeticheskie-uslugi
/spa
Дубль
Страница дублирует уже представленную в поиске страницу http://solnechny.by/spa. Укажите роботу предпочтительный адрес с помощью 301 редиректа или атрибута rel=”canonical”.
3)
/besplatnyj-wi-fi
/spa
Дубль
Страница дублирует уже представленную в поиске страницу http://solnechny.by/spa. Укажите роботу предпочтительный адрес с помощью 301 редиректа или атрибута rel=”canonical”.
4)
/detskij-kukolnyj-teatr
/ceny
Дубль
Страница дублирует уже представленную в поиске страницу http://solnechny.by/ceny. Укажите роботу предпочтительный адрес с помощью 301 редиректа или атрибута rel=”canonical”.
Ну вот 4 примера из 10-15 исключенных.
И еще инфа из моей переписки с сп яндекса:
“В данном случае нужно сравнивать текстовое содержимое страниц http://solnechny.by/plyazh и http://solnechny.by/besplatnyj-wi-fi , они практически совпадает (во вложении текст, который получает наш робот).”
P.S. страницу /plyazh я удалил за ненадобностью недавно, ну тут есть код, так что норм.
Вложение:
Access-Control-Allow-Origin: *
Content-Type: text/html; charset=utf-8
<html>
<head>
<title>Not found</title>
<link rel=”stylesheet” href=”static/style404.css” type=”text/css” media=”screen” />
</head>
<body style=”background:#ffffff;”>
<div id=”error-404″ style=”margin-bottom: 120px;width:700px;”> <img src=”static/404-img.png” alt=”” />
<div id=”error-message” style=”text-align:center;width: 350px;”><h1>Page not found</h1><p>Sorry but the page you are looking for cannot be found.</p>
<p>Message error:<p>
<pre style=”color:red;white-space:pre-wrap;text-align:left;”>
local variable ‘fileView’ referenced before assignment
</pre>
<p>You may also return to main page <a
href=”https://ossa2.yandex.ru/kiwiview/” >https://ossa2.yandex.ru/kiwiview/</a>, as you may just find something else.</p></div></div>
</body>
</html>
Access-Control-Allow-Origin: *
Content-Type: text/html; charset=utf-8
<html>
<head>
<title>Not found</title>
<link rel=”stylesheet” href=”static/style404.css” type=”text/css” media=”screen” />
</head>
<body style=”background:#ffffff;”>
<div id=”error-404″ style=”margin-bottom: 120px;width:700px;”> <img src=”static/404-img.png” alt=”” />
<div id=”error-message” style=”text-align:center;width: 350px;”><h1>Page not found</h1><p>Sorry but the page you are looking for cannot be found.</p>
<p>Message error:<p>
<pre style=”color:red;white-space:pre-wrap;text-align:left;”>
local variable ‘fileView’ referenced before assignment
</pre>
<p>You may also return to main page <a
href=”https://ossa2.yandex.ru/kiwiview/” >https://ossa2.yandex.ru/kiwiview/</a>, as you may just find something else.</p></div></div>
</body>
</html>
