Точечный прогноз
заключается в получении прогнозного
значения уp,
которое определяется путем подстановки
в уравнение регрессии соответствующего
(прогнозного) значения xp:
уp = a + b* xp
Интервальный
прогноз
заключается в построении доверительного
интервала прогноза, т. е. нижней и верхней
границ уpmin,
уpmax интервала,
содержащего точную величину для
прогнозного значения yp
(ypmin < yp <
ypmin) с заданной
вероятностью.
При построении
доверительного интервала прогноза
используется стандартная
ошибка прогноза:
 ,
,
где
![]()
Строится доверительный
интервал прогноза:
![]()
Множественный регрессионный анализ
(слайд
1)
Множественная регрессия применяется
в ситуациях, когда из множества факторов,
влияющих на результативный признак,
нельзя выделить один доминирующий
фактор и необходимо учитывать влияние
нескольких факторов. Например, объем
выпуска продукции определяется величиной
основных и оборотных средств, численностью
персонала, уровнем менеджмента и т. д.,
уровень спроса зависит не только от
цены, но и от имеющихся у населения
денежных средств.
Основная цель
множественной регрессии – построить
модель с несколькими факторами и
определить при этом влияние каждого
фактора в отдельности, а также их
совместное воздействие на изучаемый
показатель.
Таким образом,
множественная регрессия – это уравнение
связи с несколькими независимыми
переменными:
![]()
(слайд
2)
Построение уравнения множественной
регрессии
1. Постановка задачи
По имеющимся данным
n наблюдений
(табл. 3.1) за совместным изменением p+1
параметра y
и xj и
((yi,xj,i);
j=1,
2, …, p;
i=1,
2, …, n)
необходимо определить аналитическую
зависимость ŷ
= f(x1,x2,…,xp),
наилучшим образом описывающую данные
наблюдений.
Таблица 3.1
Данные наблюдений
|
y |
х1 |
х2 |
… |
хр |
|
|
1 |
y1 |
x11 |
х21 |
… |
xp1 |
|
2 |
y2 |
х12 |
х22 |
… |
xp2 |
|
… |
… |
… |
… |
… |
… |
|
n |
yn |
х1n |
x2n |
… |
xpn |
Каждая строка
таблицы представляет собой результат
одного наблюдения. Наблюдения различаются
условиями их проведения.
Вопрос о том, какую
зависимость следует считать наилучшей,
решается на основе какого-либо критерия.
В качестве такого критерия обычно
используется минимум суммы квадратов
отклонений расчетных значений
результативного показателя ŷi
от наблюдаемых
значений yi:
![]()
2. Спецификация модели
(слайд
3)
Спецификация модели включает в себя
решение двух задач:
– отбор факторов,
подлежащих включению в модель;
– выбор формы
уравнения регрессии.
2.1. Отбор факторов при построении множественной регрессии
Включение в
уравнение множественной регрессии того
или иного набора факторов связано прежде
всего с представлениями исследователя
о природе взаимосвязи моделируемого
показателя с другими экономическими
явлениями.
К факторам,
включаемым в модель, предъявляются
следующие требования:
1. Факторы должны
быть количественно измеримы.
Включение фактора в модель должно
приводить к существенному увеличению
доли объясненной части в общей вариации
зависимой переменной. Поскольку данная
величина характеризуется коэффициентом
детерминации,
включение нового фактора в модель должно
приводить к заметному изменению
коэффициента. Если этого не происходит,
то включаемый в анализ фактор не улучшает
модель и является лишним.
Например, если для
регрессии, включающей 5 факторов,
коэффициент детерминации составил
0,85, и включение шестого фактора дало
коэффициент детерминации 0,86, то вряд
ли целесообразно дополнять модель этим
фактором.
Если необходимо
включить в модель качественный фактор,
не имеющий количественной оценки, то
нужно придать ему количественную
определенность. В этом случае в модель
включается соответствующая ему
«фиктивная»
переменная,
имеющая конечное количество формально
численных значений, соответствующих
градациям качественного фактора (балл,
ранг).
Например, если
нужно учесть влияние уровня образования
(на размер заработной платы), то в
уравнение регрессии можно включить
переменную, принимающую значения: 0 –
при начальном образовании, 1 – при
среднем, 2 – при высшем.
Несмотря на то,
что теоретически регрессионная модель
позволяет учесть любое количество
факторов, на практике в этом нет
необходимости, т.к. неоправданное их
увеличение приводит к затруднениям в
интерпретации модели и снижению
достоверности результатов.
2. Факторы не
должны быть взаимно коррелированы
и, тем более, находиться в точной
функциональной связи. Наличие высокой
степени коррелированности между
факторами может привести к неустойчивости
и ненадежности оценок коэффициентов
регрессии, а также к невозможности
выделить изолированное влияние факторов
на результативный показатель. В результате
параметры регрессии оказываются
неинтерпретируемыми.
Пример.
Рассмотрим регрессию себестоимости
единицы продукции (у)
от заработной платы работника (х)
и производительности труда в час (z).
![]()
Коэффициент
регрессии при переменной z
показывает, что с ростом производительности
труда на 1 ед-цу в час себестоимость
единицы продукции снижается в среднем
на 10 руб. при постоянном уровне оплаты
труда.
А параметр при х
нельзя интерпретировать как снижение
себестоимости единицы продукции за
счет роста заработной платы. Отрицательное
значение коэффициента регрессии в
данном случае обусловлено высокой
корреляцией между х
и z
(0,95).
(слайд
4)
Считается, что две переменные явно
коллинеарны,
т.е. находятся между собой в линейной
зависимости, если коэффициент
интеркорреляции
(корреляции между двумя объясняющими
переменными) ≥ 0,7. Если факторы явно
коллинеарны, то они дублируют друг друга
и один из них рекомендуется исключить
из уравнения. Предпочтение при этом
отдается не тому фактору, который более
тесно связан с результатом, а тому,
который при достаточно тесной связи с
результатом имеет наименьшую тесноту
связи с другими факторами.
В этом требовании
проявляется специфика множественной
регрессии как метода исследования
комплексного воздействия факторов в
условиях их независимости друг от друга.
Наряду с парной
коллинеарностью может иметь место
линейная зависимость между более чем
двумя переменными – мультиколлинеарность,
т.е. совокупное воздействие факторов
друг на друга.
Наличие
мультиколлинеарности факторов может
означать, что некоторые факторы всегда
будут действовать в унисон. В результате
вариация в исходных данных перестанет
быть полностью независимой, что не
позволит оценить воздействие каждого
фактора в отдельности. Чем сильнее
мультиколлинеарность факторов, тем
менее надежна оценка распределения
суммы объясненной вариации по отдельным
факторам с помощью МНК.
(слайд
5) Включение
в модель мультиколлинеарных факторов
нежелательно по следующим причинам:
-
затрудняется
интерпретация параметров множественной
регрессии; параметры линейной регрессии
теряют экономический смысл; -
оценки параметров
не надежны, имеют большие стандартные
ошибки и меняются с изменением количества
наблюдений (не только по величине, но
и по знаку), что делает модель непригодной
для анализа и прогнозирования.
(слайд
6) Для
оценки мультиколлинеарности используется
определитель
матрицы парных коэффициентов
интеркорреляции:
(!)
Если факторы не коррелируют между собой,
то матрица коэффициентов интеркорреляции
является единичной, поскольку в этом
случае все недиагональные элементы
равны 0. Например, для уравнения с тремя
переменными
![]() матрица коэффициентов интеркорреляции
матрица коэффициентов интеркорреляции
имела бы определитель, равный 1, поскольку![]() и
и![]() .
.

(слайд
7)
(!)
Если между факторами существует полная
линейная зависимость
и все коэффициенты корреляции равны 1,
то определитель такой матрицы равен 0
(Если
две строки матрицы совпадают, то её
определитель равен нулю).

Чем ближе к 0
определитель матрицы коэффициентов
интеркорреляции, тем сильнее
мультиколлинеарность и ненадежнее
результаты множественной регрессии.
Чем ближе к 1
определитель
матрицы коэффициентов интеркорреляции,
тем меньше мультиколлинеарность
факторов.
(слайд
8)
Способы
преодоления мультиколлинеарности
факторов:
1)
исключение из модели одного или нескольких
факторов;
2)
переход к совмещенным уравнениям
регрессии, т.е. к уравнениям, которые
отражают не только влияние факторов,
но и их взаимодействие. Например, если
![]() ,
,
то можно построить следующее совмещенное
уравнение:![]() ;
;
3)
переход к уравнениям приведенной формы
(в уравнение регрессии подставляется
рассматриваемый фактор, выраженный из
другого уравнения).
(слайд
9)
2.2. Выбор формы уравнения регрессии
Различают следующие
виды уравнений
множественной регрессии:
-
линейные,
-
нелинейные,
сводящиеся к линейным, -
нелинейные, не
сводящиеся к линейным (внутренне
нелинейные).
В первых двух
случаях для оценки параметров модели
применяются методы классического
линейного регрессионного анализа. В
случае внутренне нелинейных уравнений
для оценки параметров применяются
методы нелинейной оптимизации.
Основное требование,
предъявляемое к уравнениям регрессии,
заключается в наличии наглядной
экономической интерпретации модели и
ее параметров. Исходя из этих соображений,
наиболее часто используются линейная
и степенная зависимости.
Линейная
множественная регрессия имеет вид:
![]()
Параметры bi
при факторах хi
называются коэффициентами
«чистой» регрессии.
Они показывают, на сколько единиц в
среднем изменится результативный
признак за счет изменения соответствующего
фактора на единицу при неизмененном
значении других факторов, закрепленных
на среднем уровне.
(слайд
10)
Например, зависимость спроса на товар
(Qd) от цены (P) и дохода (I) характеризуется
следующим уравнением:
Qd = 2,5 – 0,12P + 0,23 I.
Коэффициенты
данного уравнения говорят о том, что
при увеличении цены на единицу, спрос
уменьшится в среднем на 0,12 единиц, а при
увеличении дохода на единицу, спрос
возрастет в среднем 0,23 единицы.
Параметр а
не всегда может быть содержательно
проинтерпретирован.
Степенная
множественная регрессия имеет вид:
![]()
Параметры bj
(степени факторов хi)
являются коэффициентами эластичности.
Они показывают, на сколько % в среднем
изменится результативный признак за
счет изменения соответствующего фактора
на 1% при неизмененном значении остальных
факторов.
Наиболее широкое
применение этот вид уравнения регрессии
получил в производственных функциях,
а также при исследовании спроса и
потребления.
Например, зависимость
выпуска продукции Y от затрат капитала
K и труда L:
![]() говорит
говорит
о том, что увеличение затрат капитала
K на 1% при неизменных затратах труда
вызывает увеличение выпуска продукции
Y на 0,23%. Увеличение затрат труда L на 1%
при неизменных затратах капитала K
вызывает увеличение выпуска продукции
Y на 0,81 %.
Возможны и другие
линеаризуемые функции для построения
уравнения множественной регрессии:
-
экспонента
 ;
; -
гипербола
 .
.
Чем сложнее функция,
тем менее интерпретируемы ее параметры.
Кроме того, необходимо помнить о
соотношении между количеством наблюдений
и количеством факторов в модели. Так,
для анализа трехфакторной модели должно
быть проведено не менее 21 наблюдения.
(слайд
11) 3.
Оценка параметров модели
Параметры уравнения
множественной регрессии оцениваются,
как и в парной регрессии, методом
наименьших квадратов,
согласно которому следует выбирать
такие значения
параметров а
и bi,
при которых сумма квадратов отклонений
фактических значений результативного
признака yi
от теоретических
значений ŷ
минимальна,
т. е.:
![]()
Если
![]() ,
,
тогдаS
является функцией неизвестных параметров
a,
bi:
![]()
Чтобы найти минимум
функции, нужно найти частные производные
по каждому из параметров и приравнять
их к 0:

Отсюда получаем
систему уравнений:

(слайд
12) Ее
решение может быть осуществлено методом
определителей:
![]() ,
,
где ∆
– определитель системы;
∆a,
∆b1,
∆bp
– частные определители (∆j).
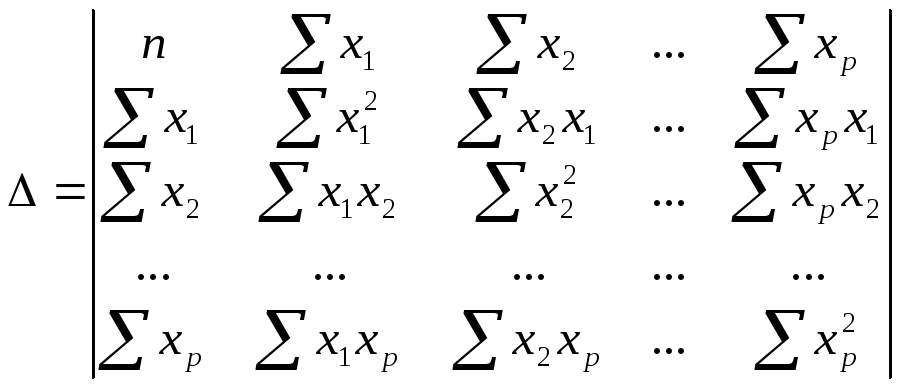 –определитель
–определитель
системы,
∆j
– частные
определители, которые получаются из
основного определителя путем замены
j-го столбца на столбец свободных членов
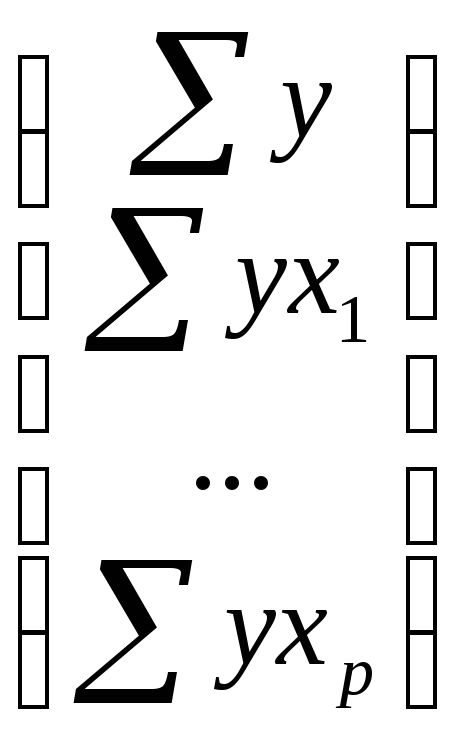 .
.
При использовании
данного метода возможно возникновение
следующих ситуаций:
1) если основной
определитель системы Δ равен
нулю и все определители Δj
также равны
нулю, то данная система имеет бесконечное
множество решений;
2) если основной
определитель системы Δ равен
нулю и хотя бы один из определителей Δj
также равен
нулю, то система решений не имеет.
(слайд
13) Помимо
классического МНК для определения
неизвестных параметров линейной модели
множественной регрессии используется
метод оценки параметров через
β-коэффициенты
– стандартизованные коэффициенты
регрессии.
Построение
модели множественной регрессии в
стандартизированном, или нормированном,
масштабе
означает, что все переменные, включенные
в модель регрессии, стандартизируются
с помощью специальных формул.
Уравнение
регрессии
в стандартизованном масштабе:
![]() ,
,
где
 ,
, – стандартизованные переменные;
– стандартизованные переменные;
![]() – стандартизованные
– стандартизованные
коэффициенты регрессии.
Т.е. посредством
процесса стандартизации точкой отсчета
для каждой нормированной переменной
устанавливается ее среднее значение
по выборочной совокупности. При этом в
качестве единицы измерения
стандартизированной переменной
принимается ее среднеквадратическое
отклонение σ.
β-коэффициенты
показывают,
на сколько сигм (средних квадратических
отклонений) изменится в среднем результат
за счет изменения соответствующего
фактора xi
на одну сигму при неизменном среднем
уровне других факторов.
Стандартизованные
коэффициенты регрессии βi
сравнимы
между собой, что позволяет ранжировать
факторы по силе их воздействия на
результат. Большее относительное влияние
на изменение результативной переменной
y оказывает
тот фактор, которому соответствует
большее по модулю значение коэффициента
βi.
В этом основное
достоинство стандартизованных
коэффициентов регрессии,
в отличие от коэффициентов «чистой»
регрессии, которые не сравнимы между
собой.
(слайд
14)
Связь коэффициентов «чистой» регрессии
bi
с коэффициентами βi
описывается соотношением:
 ,
,
или
![]()
Параметр a
определяется как
![]() .
.
Коэффициенты
β определяются при помощи
МНК
из следующей системы уравнений
методом определителей:

Для оценки параметров
нелинейных
уравнений множественной регрессии
предварительно осуществляется
преобразование последних в линейную
форму (с помощью замены переменных) и
МНК применяется для нахождения параметров
линейного уравнения множественной
регрессии в преобразованных переменных.
В случае внутренне
нелинейных
зависимостей для оценки параметров
приходится применять методы нелинейной
оптимизации.
(слайд
1) 4.
Проверка качества уравнения регрессии
Практическая
значимость уравнения множественной
регрессии оценивается с помощью
показателя множественной корреляции
и его квадрата – коэффициента детерминации.
Показатель
множественной корреляции
характеризует тесноту связи рассматриваемого
набора факторов с исследуемым признаком,
т.е. оценивает тесноту совместного
влияния факторов на результат.
Независимо от
формы связи показатель
множественной корреляции
рассчитывается по формуле:

Коэффициент
множественной корреляции принимает
значения в диапазоне 0 ≤ R
≤ 1. Чем ближе
он к 1, тем теснее связь результативного
признака со всем набором исследуемых
факторов.
При линейной
зависимости признаков формулу индекса
множественной корреляции можно записать
в виде:
![]() ,
,
где
![]() –
–
стандартизованные коэффициенты
регрессии,
![]() –
–
парные коэффициенты корреляции результата
с каждым фактором.
Данная формула
получила название линейного
коэффициента множественной корреляции,
или совокупного
коэффициента корреляции.
Индекс детерминации
для нелинейных по оцениваемым параметрам
функций принято называть «квази-![]() ».Для его
».Для его
определения по функциям, использующим
логарифмические преобразования
(степенная, экспонента), необходимо
сначала найти теоретические значения
ln
y,
затем трансформировать их через
антилогарифмы (антилогарифм ln
y
= y)
и далее определить индекс детерминации
как «квази-![]() »
»
по формуле:
![]() .
.
Величина «квази-![]() »
»
не будет совпадать с совокупным
коэффициентом корреляции, который может
быть рассчитан для линейного в логарифмах
уравнения множественной регрессии,
потому что в последнем раскладывается
на факторную и остаточную суммы квадратов
не![]() ,
,
а![]() .
.
(слайд
2)
Использование коэффициента множественной
детерминации
![]()
для оценки качества модели обладает
тем недостатком, что включение в модель
нового фактора (даже несущественного)
автоматически увеличивает величину![]() .
.
Поэтому при большом количестве факторов
предпочтительней использовать так
называемый скорректированный
(улучшенный) коэффициент множественной
детерминации
![]() ,
,
определяемый соотношением:
![]() ,
,
где n
– число наблюдений,
m
– число параметров при переменных х
(чем больше величина m,
тем сильнее различия между к-том множ.
детерминации
![]()
и скорректированным к-том
![]() ).
).
При заданном объеме
наблюдений и при прочих равных условиях
с увеличением числа независимых
переменных (параметров) скорректированный
к-т множ. детерминации убывает. Его
величина может стать и отрицательной
при слабых связях результата с факторами.
При небольшом числе наблюдений
нескорректированная величина к-та
имеет
тенденцию переоценивать долю вариации
результативного признака, связанную с
влиянием факторов, включенных в
регрессионную модель. Чем
больше объем совокупности, по которой
исчислена регрессия, тем меньше
различаются
![]() и
и
![]() .
.
Отметим, что низкое
значение коэффициента множественной
корреляции и коэффициента множественной
детерминации может быть обусловлено
следующими причинами:
– в регрессионную
модель не включены существенные факторы;
– неверно выбрана
форма аналитической зависимости, не
отражающая реальные соотношения между
переменными, включенными в модель.
(слайд
3)
Значимость уравнения множественной
регрессии в целом оценивается с помощью
F–
критерия Фишера:
![]()
Выдвигаемая
«нулевая» гипотеза H0 о статистической
незначимости уравнения регрессии
отвергается при выполнении условия F
> Fкрит,
где Fкрит
определяется по таблицам F-критерия
Фишера по двум степеням свободы k1
= m,
k2=
n-m–1
и заданному уровню значимости α.
Значимость одного
и того же фактора может быть различной
в зависимости от последовательности
введения его в модель.
(слайд
4) Мерой
для оценки включения фактора в модель
служит частный
F-критерий
(оценивает статистическую значимость
присутствия каждого из факторов в
уравнении):
 ,
,
где
![]() –
–
коэффициент множ. детерминации для
модели с полным
набором
факторов;
![]() –
–
тот же показатель, но без включения в
модель фактора х1;
n
– число наблюдений;
m
– число параметров при переменных х.
Если фактическое
значение F
превышает табличное, то дополнительное
включение в модель фактора xi
статистически оправдано и коэффициент
чистой регрессии bi
при факторе xi
статистически значим.
Если же фактическое
значение F
меньше табличного, то нецелесообразно
включать в модель дополнительный фактор,
поскольку он не увеличивает существенно
долю объясненной вариации результата,
а коэффициент регрессии при данном
факторе статистически не значим.
(слайд
5) Частный
F-критерий
оценивает значимость коэффициентов
чистой регрессии. Зная величину
![]() ,
,
можно определить и t-критерий
Стьюдента:
![]()
или
![]()
где mbi
– средняя квадратическая ошибка
коэффициента регрессии bi,
она может быть определена по формуле:
 .
.
Величина
стандартной ошибки совместно с
t-распределением Стьюдента при n-m-1
степенях свободы применяется для
проверки значимости коэффициента
регрессии и для расчета его доверительного
интервала.
Соседние файлы в папке Эконометрика
- #
- #
- #
- #
- #
- #
- #
- #
Имеются данные о рейтинге авиакомпании и ее пассажирообороте. Сделайте точечный прогноз значения рейтинга авиакомпании при пассажирообороте, равном 15 млн. пасс/км (линейная регрессия).
| № п/п | х | y |
|---|---|---|
| 1 | 67,12 | 3,9 |
| 2 | 47,07 | 3,9 |
| 3 | 1,42 | 3,8 |
| 4 | 15,58 | 3,7 |
| 5 | 8,47 | 3,6 |
| 6 | 2,87 | 3,3 |
| 7 | 10,15 | 3,3 |
| 8 | 13,33 | 3,3 |
| 9 | 3,31 | 3,2 |
| 10 | 0,29 | 3,2 |
| 11 | 5,56 | 3,2 |
| 12 | 2,45 | 3,2 |
| 13 | 2,04 | 3,2 |
| 14 | 0,33 | 3,1 |
| 15 | 0,97 | 3,1 |
| 16 | 0,57 | 3,1 |
| 17 | 13,4 | 3,1 |
| 18 | 20,2 | 3,1 |
| 19 | 0,57 | 3,1 |
| 20 | 1,75 | 3 |
| 21 | 0,43 | 3 |
| 22 | 6,06 | 3 |
| 23 | 2,51 | 3 |
| 24 | 0,62 | 2,9 |
| 25 | 2,9 | 2,9 |
| 26 | 3,39 | 2,8 |
| 27 | 0,6 | 2,7 |
| 28 | 0,66 | 2,6 |
| 29 | 4,04 | 2,3 |
| 30 | 0,44 | 2,1 |
Решение:
Для расчёта параметров линейной регрессии
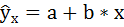
необходимо решить систему нормальных уравнений относительно a и b:
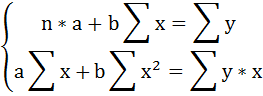
Построим таблицу исходных и расчётных данных.
Таблица 1 Расчетные данные для оценки линейной регрессии
| № п/п | х | y | x2 | x×y | 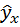 |
|---|---|---|---|---|---|
| 1 | 67,12 | 3,9 | 4505,094 | 261,768 | 4,085272 |
| 2 | 47,07 | 3,9 | 2215,585 | 183,573 | 3,759205 |
| 3 | 1,42 | 3,8 | 2,0164 | 5,396 | 3,016813 |
| 4 | 15,58 | 3,7 | 242,7364 | 57,646 | 3,247093 |
| 5 | 8,47 | 3,6 | 71,7409 | 30,492 | 3,131465 |
| 6 | 2,87 | 3,3 | 8,2369 | 9,471 | 3,040394 |
| 7 | 10,15 | 3,3 | 103,0225 | 33,495 | 3,158786 |
| 8 | 13,33 | 3,3 | 177,6889 | 43,989 | 3,210501 |
| 9 | 3,31 | 3,2 | 10,9561 | 10,592 | 3,047549 |
| 10 | 0,29 | 3,2 | 0,0841 | 0,928 | 2,998436 |
| 11 | 5,56 | 3,2 | 30,9136 | 17,792 | 3,08414 |
| 12 | 2,45 | 3,2 | 6,0025 | 7,84 | 3,033563 |
| 13 | 2,04 | 3,2 | 4,1616 | 6,528 | 3,026896 |
| 14 | 0,33 | 3,1 | 0,1089 | 1,023 | 2,999086 |
| 15 | 0,97 | 3,1 | 0,9409 | 3,007 | 3,009494 |
| 16 | 0,57 | 3,1 | 0,3249 | 1,767 | 3,002989 |
| 17 | 13,4 | 3,1 | 179,56 | 41,54 | 3,21164 |
| 18 | 20,2 | 3,1 | 408,04 | 62,62 | 3,322226 |
| 19 | 0,57 | 3,1 | 0,3249 | 1,767 | 3,002989 |
| 20 | 1,75 | 3 | 3,0625 | 5,25 | 3,022179 |
| 21 | 0,43 | 3 | 0,1849 | 1,29 | 3,000713 |
| 22 | 6,06 | 3 | 36,7236 | 18,18 | 3,092272 |
| 23 | 2,51 | 3 | 6,3001 | 7,53 | 3,034539 |
| 24 | 0,62 | 2,9 | 0,3844 | 1,798 | 3,003802 |
| 25 | 2,9 | 2,9 | 8,41 | 8,41 | 3,040881 |
| 26 | 3,39 | 2,8 | 11,4921 | 9,492 | 3,04885 |
| 27 | 0,6 | 2,7 | 0,36 | 1,62 | 3,003477 |
| 28 | 0,66 | 2,6 | 0,4356 | 1,716 | 3,004453 |
| 29 | 4,04 | 2,3 | 16,3216 | 9,292 | 3,059421 |
| 30 | 0,44 | 2,1 | 0,1936 | 0,924 | 3,000875 |
| Итого | 239,1 | 93,7 | 8051,407 | 846,736 | 93,7 |
Подставив в систему уравнений рассчитанные величины, определим параметры линейного уравнения:
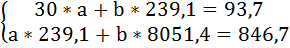
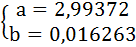
Таким образом, уравнение регрессии имеет вид:
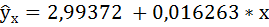
Это значит, что с увеличением пассажирооборота на 1 млн. пасс/км рейтинг авиакомпании увеличится на 0,016263.
Подставим в данное уравнение исходные значения х и найдём сумму расчётных значений у (последняя графа таблицы).
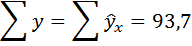
Так как суммы исходных и расчётных значений у совпадают, следовательно, параметры уравнения рассчитаны верно.
Если прогнозное значение пассажирооборота, составит 15 млн. пасс/км, то рейтинг авиакомпании будет равен:
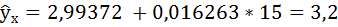
Ответ: значение рейтинга авиакомпании при пассажирообороте, равном 15 млн. пасс/км будет равно 3,2.
Точечный и интервальный прогнозы для модели парной регрессии
Построение прогноза по модели парной линейной регрессии начинается с нахождения прогнозного значения объясняемой переменной у для заданного значения объясняемой переменной х0:
Прогноз возможен для математического ожидания М(у х = х0) зависимой переменной у или для индивидуального (конкретного значения) у* Во втором случае нас интересует доверительный интервал для точного, наперед заданного значения объясняющей переменной х0.
Доверительный интервал для среднего значения (математического ожидания) зависимой переменной нри данном значении переменной х0 определяется по формуле
где
Дисперсия интервального прогноза для среднего значения у определяется по формуле
где X 2 — выборочная дисперсия:
Доверительный интервал для индивидуальных значений зависимой переменной у*Х() при данном значении переменной х0 определяется но формуле
где
Дисперсия интервального прогноза для индивидуального значения г/* равна
Выводы по доверительным областям для зависимой переменной.
- 1. Прогноз значений зависимой переменной Y по уравнению линейной регрессии оправдан, если значение х0 объясняющей переменной X не выходит за диапазон ее значений по выборке. Причем чем ближе х0 к х, тем точнее прогноз, уже доверительный интервал (3.38) и (3.40).
- 2. Использование уравнения линейной регрессии вне изученного диапазона значений объясняющей переменной X, даже если оно экономически оправдано исходя из смысла решаемой задачи, может привести к значительным погрешностям.
Построим доверительные интервалы для среднего и индивидуального значений зависимой переменной для уравнения регрессии, полученного но данным примера 3.1. Решение. Ранее получено уравнениерегрессии у< = 3,295 + 2,283.г,.
Выборочная дисперсия
Среднее значение объясняющей переменной х = 13,8; Qv = 135,6.
Пусть доверительная вероятность у = 0,95.
Критическая точка ?кр = t0 05; 8 = 2,306.
Прогнозное значение зависимой переменной
Дисперсия интервального прогноза для среднего значения у (формула (3.39)):
Доверительный интервал для среднего значения у (формула (3.38)):
Дисперсия интервального прогноза для индивидуального значения у<) (формула (3.41)):
Доверительный интервал для индивидуального значения уо (формула (3.40)):
Средняя ошибка аппроксимации. Фактические значения результативного признака отличаются от теоретических. Чем меньше это отличие, тем ближе теоретические значения подходят к эмпирическим данным, это лучшее качество модели. Величина отклонений фактических и расчетных значений результативного признака по каждому наблюдению представляет собой ошибку аппроксимации. Для сравнения используются величины отклонений, выраженные в процентах к фактическим значениям.
Средняя ошибка аппроксимации рассчитывается по формуле
Прогноз по модели парной регрессии
Точечный прогноз по уравнению регрессии
Если известно значение независимой переменной х, то прогноз зависимой переменной осуществляется подстановкой этого значения в оценку детерминированной составляющей:
Вследствие несмещенности оценок параметров регрессии этот прогноз также является несмещенным
Показателем точности прогноза служит его дисперсия (чем она меньше, тем точнее прогноз):
Из формулы (1.2.3) видно, что чем больше объем выборки, тем точнее прогноз. При фиксированном объеме выборки прогноз тем точнее, чем больше «разнесены» выборочные данные и чем ближе значение независимой переменной к среднему выборочному значению.
Интервальный прогноз по уравнению регрессии
Поскольку согласно (1.2.3) у(х)
N^y(x), а дисперсия а 2
в (1.2.3) заменяется ее несмещенной оценкой по формуле (1.1.15), то за середину доверительного интервала для детерминированной составляющей выбирается точечный прогноз зависимой переменной, а ширина доверительного интервала — пропорциональной стандартному отклонению точечного прогноза:
где ta — двусторонняя критическая граница распределения Стью- дента с (п — 2) степенями свободы.
О Пример 1.1. Зависимость розничного товарооборота от числа занятых
Исследуем зависимость розничного товарооборота (млн руб.) магазинов от среднесписочного числа работников. Товарооборот как результирующий признак обозначим через у, а среднесписочное число работников как независимую переменную (фактор) — через х.
На объем товарооборота влияют также такие факторы, как объем основных фондов, их структура, площадь торговых залов и подсобных помещений, расположение магазинов по отношению к потокам покупателей и т. п. Предположим, что в исследуемой группе магазинов значения этих других факторов примерно одинаковы, поэтому различие их значений на изменении объема товарооборота сказывается незначительно.
В табл. 1.1 в столбцах 2 и 3 приведены значения соответственно среднесписочного числа работников и объема розничного товарооборота, а в следующих столбцах — значения расчетных величин, необходимых для определения оценок коэффициентов регрессии и дисперсии случайной составляющей (Zj=Xj-x, Ayj=yj-y,
Фактические и выравненные значения товарооборота (млн руб.) в зависимости от числа занятых
Найдя по итогам столбцов 2 и 3 средние х = 904/8 = 113, у = 9,6/8 = 1,2, последовательно заполняем столбцы 4—8 и подводим итоги по этим столбцам. Теперь можно определять эмпирические коэффициенты регрессии. По формулам (1.1.6) находим следующие точечные оценки коэффициентов регрессии:
Значение нулевого коэффициента &° представляет собой ординату эмпирической линии регрессии в точке х = х = 113, а коэффициент регрессии dj = 0,01924 — угловой коэффициент этой прямой линии.
На рис. 1.2 изображены система соединенных штриховой линией точек наблюдений и прямая эмпирической регрессии.
Если не учитывать, что мы имеем не теоретическую, а эмпирическую линию регрессии (которая действительно является приближением теоретической линии регрессии), то коэффициент
а, = 0,01924 показывает, что увеличение среднесписочной численности на одного человека приводит к увеличению товарооборота в среднем на 19,24 тыс. руб. Это своего рода эмпирический норматив приростной эффективности использования работников для данной группы магазинов. Если увеличение численности на одного работника приводит к меньшему росту товарооборота, то прием его на работу необоснован.
Теперь можно вычислить выравненные значения (значения ординат эмпирической линии регрессии):
и использовать столбцы 9—11 табл. 1.1. Итог столбца 11, в свою очередь, позволяет получить оценку дисперсии случайной составляющей:
Зная дисперсию случайной составляющей, можно проверить статистические гипотезы о параметрах регрессии и уравнении
Рис. 1.2. Фактические (штриховая ломаная линия) и выравненные (сплошная прямая линия) значения товарооборота
в целом, а также построить интервальные оценки параметров регрессии и прогнозного значения детерминированной составляющей.
Для проверки гипотезы о том, значимо ли отличается от нуля выборочный коэффициент ос,, находим согласно равенству (1.1.18) его эмпирическую значимость
которую теперь надо сравнить с теоретическим значением ta(n — 2), найденным по таблице распределения Стьюдента (см. табл. П.5.2).
Выбираем уровень значимости ос равным 5% (т. е. с вероятностью 0,05 мы допускаем, что гипотеза Н0: ос, = 0 будет отвергнута в том случае, когда она на самом деле верна). По табл. П.5.2 находим /005(6) = 2,45. Эмпирическая значимость (14,198) существенно
больше теоретической (2,45), поэтому d1 значимо отличается от нуля, т. е. принимаем гипотезу Н <.ос, *0.
Этот вывод подтверждается и высоким значением коэффициента детерминации:
который показывает, что в исследуемой ситуации 97,1% общей вариабельности розничного товарооборота объясняется изменением числа работников, в то время как на все остальные факторы приходится лишь 2,9% вариабельности.
Этот статистический вывод не абсолютен. Допустим, что в магазинах исследуемой группы стало больше работников, при этом предельная эффективность работника падает и на первый план выходит влияние других факторов. По-видимому, это прежде всего доля дефицитных товаров в ассортименте, комплекс факторов, характеризующих культуру обслуживания, и расположение магазинов.
Построим интервальные оценки параметров регрессии а 0 , а,
в форме d° ± /а(Ьо, 6с, ± /„6^. Здесь середины интервалов являются точечными оценками коэффициентов регрессии, которые уже рассчитаны: &°=у = 1,2; а, =0,01924. При выборе уровня значимости 5% получаем /0,05(6) = 2,45. Остается только найти стандартные ошибки коэффициентов регрессии. Согласно формулам (1.1.8), (1.1.7)
заменяя а на 6, получаем
Отсюда окончательно получаем, что с вероятностью 0,95 истинные значения параметров лежат в следующих пределах:
Найденные отклонения фактических значений от выравненных (столбец 10) позволяют провести сравнительный анализ работы различных магазинов рассматриваемой группы. Прежде всего необходимо обратить внимание на магазины с отрицательным отклонением (3, 4 и 6-й). Особенно велико отклонение у 4-го магазина. В реальной ситуации необходимо внимательно обследовать эти магазины и установить причины отклонения фактического значения товарооборота от выравненного («нормативного») значения. Это может быть расположение магазина в стороне от основных потоков покупателей, плохое снабжение товарами повышенного спроса, устаревшее оборудование, неудовлетворительный кадровый состав и т. п. При статистическом анализе с учетом сделанных ранее предположений и на основе имеющихся данных приходим к выводу, что в этих магазинах, по-видимому, имеются резервы в организации труда работников. Напротив, в 1, 2, 5, 7 и 8-м магазинах эффективность использования работников выше статистического норматива, но может оказаться, что эти магазины объективно находятся в лучших условиях.
Полученное уравнение регрессии может быть использовано для прогноза. В частности, пусть намечается открытие магазина такого же типа с численностью работников х = 140, тогда достаточно обоснованный объем товарооборота следует установить по уравнению регрессии
С точки зрения принятой теоретической схемы полученный прогноз у(х) является лишь точечной оценкой истинной детерминированной составляющей у (х), а сама составляющая лежит внутри доверительного интервала у (x) ± , в котором согласно формуле (1.2.4)
В результате получаем следующий доверительный интервал для теоретического значения прогноза:
или
Вопросы и задачи
1. Предскажите время реакции полуторамесячного ребенка по следующим данным:
Построение интервального прогноза по модели парной линейной регрессии
Если построенное уравнение регрессии и показатели тесноты связи признаны статистически значимыми, то такую модель можно использовать для построения прогноза.
Точечный прогноз упрог„. определяется, если в уравнение регрессии подставить значение факторной переменной хпрогнпри котором нас интересует значение прогнозируемой эндогенной переменной.
Однако вероятность осуществления точечного прогноза невелика, поэтому прибегают к интервальному прогнозу, вероятность которого составляет 95 %. Расчеты, необходимые для интервального прогноза:
где Snp0ZH‘ — стандартная ошибка прогноза; S — стандартная ошибка уравнения регрессии (корень из остаточной дисперсии на одну степень свободы); п — объем выборки; х„рогн — значение факторной переменной, при которой прогнозируется эндогенная переменная; х, — индивидуальные значения независимой переменой; х — среднее арифметическое значений факторного признака.
Стандартная ошибка уравнения регрессии рассчитывается по формуле:
Доверительный интервал прогноза:
где t — табличное значение t-критерия Стьюдента при уровне значимости 0,05 и числе степеней свободы п-2.
АНАЛИЗ ОСТАТКОВ ПО МОДЕЛИ РЕГРЕССИИ
1. Требования к остаткам для качественной модели регрессии.
Понятие гомоскедастичности и гетероскедастичности остатков модели. Методы проверки ряда остатков модели на гетероскедастичносгь
Методика проведения теста Голдфелда — Квандта на гетероскедастичность остатков
Понятие автокорреляции в остатках. Методика проверки ряда остатков на наличие автокорреляции с помощью критерия Дарбина — Уотсона
Требования к остаткам для качественной модели регрессии
Для того чтобы построенная регрессионная модель адекватно описывала моделируемое явление или процесс и имела высокую прогностическую силу, ряд остатков по модели должен удовлетворять следующим требованиям:
- 1. Дисперсия остатков должна быть одинакова для различных наблюдений.
- 2. Остатки не должны зависеть друг от друга, т. е. не должно быть автокорреляции в остатках.
- 3. Остатки должны быть распределены по нормальному закону распределения.
После построения модели регрессии, расчета коэффициента корреляции, коэффициента детерминации, средней относительной ошибки аппроксимации, оценки статистической значимости параметров уравнения регрессии с помощью t-критерия Стьюдента и оценки статистической значимости уравнения регрессии в целом с помощью F-критерия Фишера необходимо проверить ряд остатков модели на постоянство их дисперсии и на автокорреляцию. [1]
После построения модели проверяют ряд ее остатков, и, если выявлено свойство гетероскедастичности остатков, модель не используют для прогноза и анализа явления, а строят новую модель, остатки которой гомоскедастичны.
Возможные причины гетероскедастичности остатков:
- 1) неучет в модели важных факторов, влияющих на моделируемый признак;
- 2) неверная форма модели.
Проверка выполнения требования гомоскедастичности остатков может быть произведена:
- 1) графическим методом, с помощью построения точечного графика зависимости остатков от теоретических значений результативного признака, а также графика зависимости остатков от значений факторного признака; в случае гомоскедастичности облако остатков находится в области, параллельной оси абсцисс; все прочие случаи указывают на гетероскедастичность остатков;
- 2) с помощью специальных тестов, среди которых:
- а) тест Голдфелда — Квандта;
- б) тест ранговой корреляции Спирмена;
- в) тест Уайта;
- г) тест Парка;
- д) тест Глейзера и др.
Примеры выявления гетероскедастичности в остатках визуально, графическим методом представлены на рис. 7.1-7.3.
Графики зависимости остатков от значений факторного признака выводятся автоматически при использовании надстройки «Анализ данных», инструмент анализа «Регрессия», если поставить галочку в диалоговом окне напротив опции «График остатков».
Рис. 7.1. Гетероскедастичные остатки
Рис. 7.2. Гетероскедастичные остатки 2
Рис. 7.3. Гетероскедастичные остатки 3 Пример графика гомоскедастичных остатков приведен на рис. 7.4.
Рис. 7.4. Гомоскедастичные остатки
Очень часто визуально сложно определить гомоскедастичны остатки или гетероскедастичны, поэтому используются более однозначные и точные количественные критерии.
3. МЕТОДИКА ПРОВЕДЕНИЯ ТЕСТА ГОЛ ДФЕ Л ДА — КВАНДТА НА ГЕТЕРОСКЕДАСТИЧНОСТЬ ОСТАТКОВ
Наиболее популярным критерием является критерий, предложенный С. Голдфелдом и Р. Квандтом в 1965 г. Процедура проверки остатков на го- москедастичность по тесту Голдфелда — Квандта следующая:
- 1) все наблюдения упорядочиваются по возрастанию фактора х;
- 2) упорядоченную совокупность делят на три группы, причем первая и третья должны быть равного объема; при малом числе наблюдений упорядоченную по признаку х совокупность можно разделить на две равные части; при большом числе наблюдений упорядоченную по признаку х совокупность делят на три равные части; авторы метода рекомендуют, чтобы объемы первой и третьей части удовлетворяли условию п7 = п3 = 3/8*и; из дальнейшего анализа исключается средняя часть наблюдений упорядоченной совокупности;
- 3) по первой и третьей группе наблюдений отдельно строят уравнения регрессии и определяют остаточные суммы квадратов по каждому уравнению SS и SSy,
- 4) находят отношение:
В числителе должна быть большая из сумм квадратов;
- 5) определяют табличное значение F-критерия Фишера при уровне значимости 0,05 и числе степеней свободы П]-т, где т — число оцениваемых параметров;
- 6) сравнивают расчетное значение F-критерия с табличным, если ^Расч>^табл, то остатки гетероскедастичны, т. е. чем больше найденное отношение Грасч, тем сильнее вероятность гетероскедастичности остатков; чем больше Граем превышает Гтабл, тем более нарушена предпосылка о равенстве остаточных дисперсий. [2]
Статистика DW принимает значения от 0 до 4. Если полученное значение DW не слишком отличается от 2, то можно сделать вывод об отсутствии автокорреляции в остатках.
Использование критерия Дарбина — Уотсона показано графически на схеме (рис. 7.5).
Рис. 7.5. Схема применения критерия Дарбина — Уотсона
Нижняя и верхняя границы критерия DWt и DW,, берутся из статистических таблиц с учетом уровня значимости 0,05, объема статистической совокупности (числа наблюдений) и количества параметров при факторном признаке в уравнении регрессии (для парной линейной регрессии такой параметр один — Ь).
[spoiler title=”источники:”]
http://studref.com/468914/ekonomika/prognoz_modeli_parnoy_regressii
http://bstudy.net/830446/ekonomika/postroenie_intervalnogo_prognoza_modeli_parnoy_lineynoy_regressii
[/spoiler]
