
[Удален]
19 июня 2010, 13:08
6538
Всех приветствую.
Только что залес в панель вебмастера Яндекса.
Решил проверить индексируется ли разные папки и файлы сайта.
Я запретил все в robots.txt
User-agent: *
Dissalow: /
При добавлении ссылки сайта в “Список URL” и его проверки в Результатах проверки URL появляется такая вот надпись: этот URL не принадлежит вашему домену – что это значит?
Причем такая ерунда появляется только если вначале ссылки написано http://
http://мой сайт/poslednie-novosti/ — этот URL не принадлежит вашему домену
www.мой сайт/poslednie-novosti/ — запрещен правилом /
Подскажите что это и стоит ли с этим бороться) и если стоит, то как?
P
На сайте с 09.01.2010
Offline
26
Заданный URL не принадлежит сайту, для которого производится анализ robots.txt. Возможно, вы указали адрес одного из зеркал вашего сайта или допустили ошибку в написании имени домена.
Справочник по ошибкам анализа robots.txt
Видимо основным зеркалом является www.мой сайт..
[Удален]
19 июня 2010, 14:02
#2
Зеркал у сайта никаких нет и никогда не было.
И как это сайт с www стал зеркалом или наоборот? не понимаю!
И что с этим теперь делать?
Никаких ошибок в написании домена нет точно.
T
На сайте с 12.03.2010
Offline
32
karaul777:
Зеркал у сайта никаких нет и никогда не было.
И как это сайт с www стал зеркалом или наоборот? не понимаю!
И что с этим теперь делать?
Никаких ошибок в написании домена нет точно.
для яндекса имеет занчение с WWW или без. Посмотрите как ваш сайт в выдаче идет, с www или без.
[Удален]
19 июня 2010, 14:51
#4
Triol:
для яндекса имеет занчение с WWW или без. Посмотрите как ваш сайт в выдаче идет, с www или без.
Сайт идет в выдаче с WWW
Но что это за проблема и как ее решить?
Как так вообще получилось?

На сайте с 24.06.2009
Offline
116
у меня кстати тоже самое. Но я сам прописал специально с www как главное зеркало, но там неожиданно вылезли дубли, а запретить через роботс их не могу, т.к. они с вв и выдается та же ошибка – что урл не принадлежит вашему сайту.
На сайте с 24.06.2009
Offline
116
у меня кстати тоже самое. Но я сам прописал специально с www как главное зеркало, но там неожиданно вылезли дубли, а запретить через роботс их не могу, т.к. они с вв и выдается та же ошибка – что урл не принадлежит вашему сайту.
[Удален]
19 июня 2010, 16:29
#7
Mills:
у меня кстати тоже самое. Но я сам прописал специально с www как главное зеркало, но там неожиданно вылезли дубли, а запретить через роботс их не могу, т.к. они с вв и выдается та же ошибка – что урл не принадлежит вашему сайту.
А где вы прописали сами специально?

На сайте с 23.11.2003
Offline
104
было такое недавно, пишите Платону – поправят.
T
На сайте с 12.03.2010
Offline
32
А вот что сам Яша говорит по этому поводу:
Yandex:
Почему анализатор выдает ошибку “Этот URL не принадлежит вашему домену”?
Скорее всего, в списке URL вы указали адрес одного из зеркал вашего сайта, например, http://site.ru вместо http://www.site.ru (формально, это два различных URL). Необходимо, чтобы проверяемые URL принадлежали сайту, для которого производится анализ robots.txt.
http://help.yandex.ru/webmaster/?id=999047
очень полезно тыкать ссылки вокруг той формы куда вы вбиваете адреса.)))
На сайте с 24.06.2009
Offline
116
это ясно…
а как в роботсе тогда запретить ненужный дубль c www?
я же могу прописать только Disallow: /что-то.
Когда копирую урл (дубль с www), то выдается сообщение, что он разрешен к индексации (хотя я его запретил через Disallow). А когда без www, то урл не принадлежит вашему сайту.
Правило может начинаться только с символа / или *.
Допускается только одно правило такого типа.
Количество правил в файле превышает 2048.
Правило должно всегда следовать за директивой User-agent. Возможно, файл содержит пустую строку после User-agent.
Правило превышает допустимую длину (1024 символа).
В качестве URL файла Sitemap должен быть указан полный адрес, включая протокол. Например, https://www.example.com/sitemap.xml
В директиве Clean-param указывается один или несколько параметров, которые робот будет игнорировать, и префикс пути. Параметры перечисляются через символ & и отделяются от префикса пути пробелом.
Как устранить проблему “Несоответствующие домены”
В URL целевой страницы товара должен использоваться тот же домен, что и в адресе сайта, указанном в аккаунте Merchant Center.
Эта ошибка означает, что ссылка на целевую страницу, указанная в фиде данных, не совпадает с доменом URL, который зарегистрирован в вашем аккаунте Merchant Center.
Вот несколько распространенных причин этой ошибки:
- Вы не зарегистрировали URL в своем аккаунте. Если вы указываете в фиде ссылки на свой сайт, вам нужно зарегистрировать его домен.
- Вы зарегистрировали URL, но он не соответствует ссылкам из вашего файла. Ссылки, указанные в фиде, должны соответствовать домену сайта, зарегистрированному в вашем аккаунте Merchant Center.
Например, если нужно отправить файл с URL http://www.example.com/item1.html, зарегистрируйте в своем аккаунте домен родительского сайта http://www.example.com/.
Подробнее о том, как изменить зарегистрированный URL сайта, написано здесь. Чтобы отправлять фиды для нескольких доменов, можно запросить мультиаккаунт.
Инструкции
Шаг 1. Посмотрите список товаров, в которых есть ошибки
- Войдите в аккаунт Merchant Center.
- Перейдите на вкладку Товары в меню навигации и выберите Диагностика.
- Нажмите Проблемы с товарами. Откроется список затронутых позиций.
Как скачать список всех затронутых товаров (в формате .csv)
Как скачать список всех товаров с конкретной проблемой (в формате .csv)
- Найдите проблему в одноименном столбце и нажмите на значок скачивания
 в конце строки.
в конце строки.
Как посмотреть 50 самых популярных товаров с определенной проблемой
- Найдите проблему в одноименном столбце и нажмите Посмотреть примеры в столбце “Затронутые товары”.
Шаг 2. Убедитесь, что все URL в фиде данных совпадают с URL, зарегистрированным в вашем аккаунте
- Отфильтруйте данные в скачанном отчете так, чтобы в столбце Issue title (Название проблемы) отображалось только следующее значение:
Mismatched domains (Несоответствующие домены). - Изучите список распространенных причин, приведенный в начале статьи, и определите, какая из них относится к вашей ситуации. Обновите сведения о товарах так, чтобы URL каждой позиции соответствовал домену, зарегистрированному в аккаунте Merchant Center.
Шаг 3. Повторно загрузите сведения о товарах
- После изменения данных о товаре отправьте их повторно, выбрав один из перечисленных ниже способов.
- Добавить фид напрямую
- Как отправить данные с помощью Content API
- Как импортировать данные с платформы электронной торговли
- Перейдите на страницу “Диагностика” и убедитесь, что проблема решена.
Обратите внимание, что изменения на этой странице могут появиться не сразу.
Статьи по теме
- Ссылка на изображение
[image_link] - Как подтвердить сайт своего магазина и заявить права на него
Эта информация оказалась полезной?
Как можно улучшить эту статью?
- Новые сообщения
- Участники
- Правила форума
- Поиск
- RSS
|
Как подключить SSL сертификат на сайт? |
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|
||||||
|








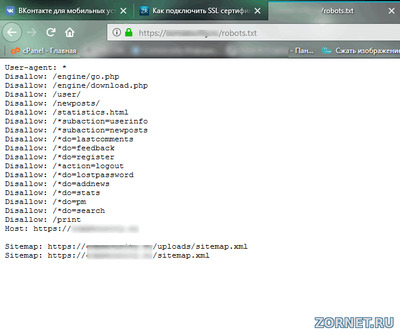

Файл robots.txt — это инструкция для поисковых роботов (Яндекса, Гугла), которая помогает им правильно индексировать ваш сайта, разрешать или запрещать индексацию разделов, страниц. Правильный robots.txt для WordPress позволяет индексировать только страницы и записи, не засоряя поисковую выдачу дублями страниц и различным мусором.
Итак, сразу к делу. Вот оптимальный файл robots.txt для сайта на WordPress (пояснения смотрите ниже):
User-agent: * Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /feed/ Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */comments Disallow: /category/*/* Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Disallow: /?s= User-agent: Yandex Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /feed/ Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */comments Disallow: /category/*/* Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Disallow: /?s= Host: maxtop.org Sitemap: http://maxtop.org/sitemap.xml.gz Sitemap: http://maxtop.org/sitemap.xml
Важно: измените адрес сайта с maxtop.org на ваш собственный!
А теперь расскажу по порядку, какие строки за что отвечают.
1. Как выбрать робота, к которому вы обращаетесь?
User-agent — это обращение к определенному поисковому роботу. Помимо того, что у каждой поисковой системы свой робот (Яндекс, Google), так еще и в рамках одного поисковика есть десяток специфических роботов. Например, YandexBot — основной робот Яндекса, YandexMedia — робот, индексирующий мультимедиа — картинки, аудио, видео, YandexImages — специализированный индексатор картинок (в Яндекс-картинки). Есть даже специальные роботы, которые сканируют микроразметку сайта.
Но нам особо вдаваться в детали не надо, только запомните, что звездочкой (*) отмечается обращение ко всем поисковым роботам.
Итак, к роботу мы обратились, теперь надо дать ему команду. Эти команды или директивы могут быть следующие:
Disallow: — запрет на индексацию раздела, страницы, регулярного выражения. Вы говорите роботу: «Вот это не смотри и в поисковую выдачу не добавляй». Нужно для запрета индексации служебных разделов, административной панели и для удаления дублей страниц. Дубли — это одинаковые страницы, доступные по разным адресам. Например, данная статья, которую вы читаете доступна по адресам:
http://maxtop.org/?p=1575
http://maxtop.org/robots-txt-dlya-wordpress/
Однако нам обе ссылки не нужны, т.к. это будет дубль страницы. И в роботс.тхт мы можем закрыть такие и подобные дубли.
Allow: — призыв к индексации страниц, разделов, ссылок. Вы говорите роботу: «Это обязательно нужно проиндексировать и добавить в поисковую выдачу!»
Host: — это указание основного хоста или адреса вашего сайта (совпадает с доменным именем сайта).
Sitemap: — это указание адреса карты сайта (в формате xml или в заархивированном виде). Вы помогаете роботу найти карту сайта, которая отражает структуру материалов у вас на сайте.
Внимание: убедитесь, что у вас установлен плагин карты сайта и что по указанному адресу действительно открывается карта сайта! Если нет — установите плагин Google (XML) Sitemaps Generator for WordPress.
3. Регулярные выражения в файле robots.txt.
Чтобы вручную не прописывать сотни ссылок для запрета или разрешения индексации можно применить регулярные выражения, которые значительно упростят вашу работу. Рассмотрим пример:
Disallow: /category/*/*
Звездочка обозначает подстановку любой части url. Таким образом, приведенная директива запрещает индексацию всех ссылок, содержащих часть «category». Это необходимо для устранения дублей, когда одна запись на вашем сайте доступна по прямой ссылке и по ссылке с префиксом «category».
Другой пример:
Disallow: /?s=
Это запрет индексации всех результатов поиска на сайте (все, что выдается в окне поиска по сайту).
А теперь не забудьте настроить файл .htaccess для своего сайта.

Поделитесь этой записью с друзьями, буду благодарен!
