Если робот Google не сможет получить доступ к вашей странице из-за правила в файле robots.txt, то она, скорее всего, не появится в результатах поиска Google, а если и появится, то без описания.
1. Проверьте, заблокирована ли страница в файле robots.txt
Если вы подтвердили право собственности на сайт в Search Console, сделайте следующее:
- Откройте инструмент проверки URL.
- Проверьте URL страницы, представленный в результате поиска Google.Должен быть выбран ресурс Search Console, который содержит этот URL.
- Найдите статус в разделе результатов проверки Индексирование страниц. Если там значится Заблокировано в файле robots.txt, то проблема подтверждена. Как ее устранить, описано далее.
Если вы не подтвердили право собственности на сайт в Search Console, сделайте следующее:
- Выполните поиск валидатора для файла robots.txt.
- Введите в валидаторе URL страницы, описание которой отсутствует. Это должен быть URL, указанный в результатах поиска Google.
- Если валидатор сообщает, что доступ к странице для робота Google запрещен, то проблема подтверждена. Как ее устранить, описано далее.
2. Измените правило
- Чтобы узнать, какое правило блокирует доступ к странице и где находится файл robots.txt, воспользуйтесь валидатором для robots.txt.
- Измените или удалите правило:
- Если вы пользуетесь сервисом веб-хостинга (например, если ваш сайт построен на Wix, Joomla или Drupal), мы не можем предоставить вам точное руководство по обновлению вашего файла robots.txt. Причина в том, что для каждого сервиса хостинга инструкции будут разными. Чтобы узнать, как разблокировать доступ Google к странице или сайту, поищите нужные сведения в документации своего хостинг-провайдера. Советуем выполнить поиск по запросу “robots.txt название_провайдера” или “открыть Google доступ к странице название_провайдера“. Пример: robots.txt Wix.
- Если у вас есть возможность вносить изменения непосредственно в файл robots.txt, удалите правило или обновите его иным образом с учетом синтаксиса robots.txt.
Эта информация оказалась полезной?
Как можно улучшить эту статью?
Google Search Console выдает ошибку “Доступ к отправленному URL заблокирован в файле robots.txt”, при том, что в самом файле robots главная для индексации не закрыта. А GSC говорит, что доступ к главной странице сайта закрыт.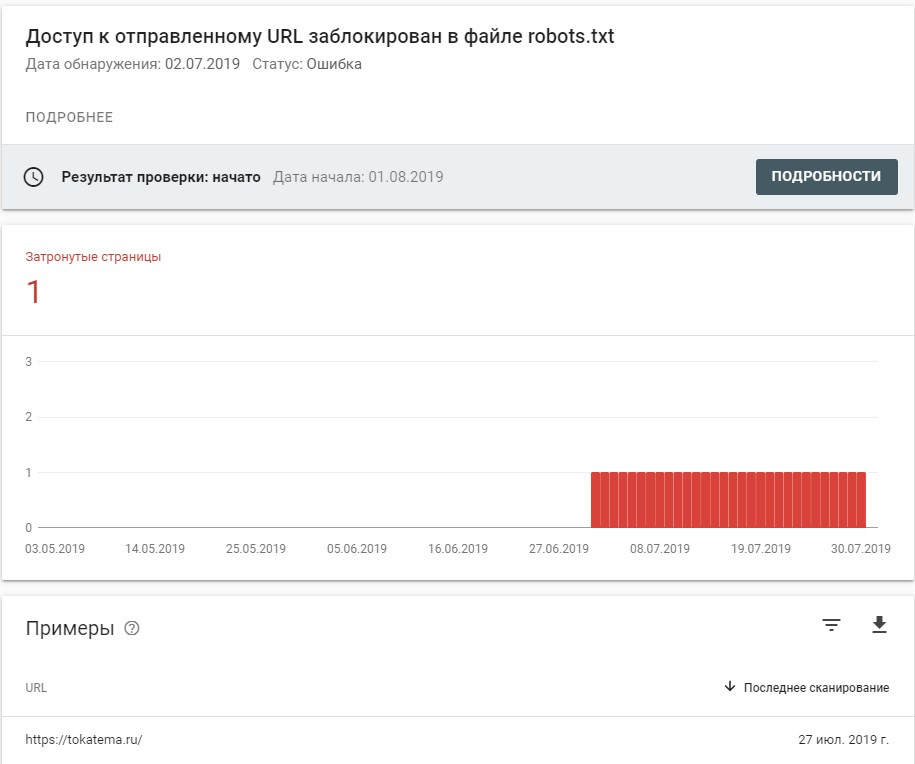
Как это можно решить?
Сама ошибка висит уже более месяца, повторная проверка результатов не даёт.
Сайт https://tokatema.ru
Robots: https://tokatema.ru/robots.txt
-
Вопрос заданболее трёх лет назад
-
1323 просмотра
Решение скрылось в совсем другом месте: плагин WP Security, опция Блокировать ложные Googlebots. После её отключения всё стало на свои места.
Пригласить эксперта
-
Показать ещё
Загружается…
24 мая 2023, в 13:38
1 руб./за проект
24 мая 2023, в 13:36
1000 руб./за проект
24 мая 2023, в 13:17
25000 руб./за проект
Минуточку внимания

Куча вопросов сыпется по поводу страниц с пометкой “Проиндексировано, несмотря на блокировку в файле robots.txt” в отчете в Google Searh Console.
Ходят мифы будто это Предупреждение – хуже ошибки, страшное зло, дубли, ужас, всё пропало…
Причины
Стоит разделить на официальную и не официальную.
Официально причиной называется
Этот статус установлен, так как мы не уверены, что вы хотите удалить страницу из результатов поиска.
Тут есть довод за и против:
ЗА: Часто в список попадают технические страницы только что появившиеся (этот же довод и ЗА неофициальный вариант)
ПРОТИВ: Почему то в иных случаях гугл уверен.
А теперь моё видение: robots.txt – превентивный запрет, соответственно нельзя сказать “Мы зашли на страницу и не знали что нельзя”. Де-юре при таком раскладе нельзя предъявить претензий, ответ будет “Вот смотрите у нас написано что можем, вот для чего, вот эти страницы, мы не уверены что их хотел удалить владелец”.
Что касается других способов, то там без посещения страницы запрет не виден, тут за руку не поймать.
Если бы robots.txt полностью запрещал посещение, могла сложиться ситуация что половина сайта видеоматериалы сексуального характера с несовершеннолетними, но закрытая в robots.txt. Вторая половина рассказы про лунтика, где ссылка на запрещенную с текстом “читать далее…”.
Индексируются ли дубли?
Что такое дубли? Это страницы с идентичным контентом, расположенные по разным адресам.
Назревает вопрос, дубль ли страница закрытая в robots.txt, но тем не менее проиндексированная, при условии что контент идентичен. Казалось бы да. Однако не всё так просто.
Страницы закрытые в robots.txt, не смотря на попадание в индекс самих страниц, имеют заблокированный для ПС контент. В чем легко убедиться попробовав вбить в поиск ключевую фразу с такой страницы. Кроме того и в самом руководстве Гугл имеется запись суть которой сводится к этому, хоть и упомянута в контексте html-атрибутов:
Внимание! Поисковый робот не обнаружит директиву noindex, если страница заблокирована в файле robots.txt. Такая страница может быть представлена в результатах поиска (например, если на нее есть ссылка на другой странице).
Чем грозит наличие в выдаче этих страниц
На самом деле ничем. Для простых пользователей они не видны. Единственное по чему можно их найти это url. Много ли посетителей у вас с поиска, которые ищут не информацию, а адрес страницы?
Настолько ли ваш сайт затмевает всех, что “пустая” страница вашего сайта обходит всех конкурентов?
Стоит ли открывать страницы в robots.txt
Необходимо понимать последствия. Ради того чтоб убрать десяток страниц, никому не мешающих, вы можете открыть тысячи, по которым будет гулять Гугл и тратить краулинговый бюджет.
Наличие noindex, canonical или редиректа в конечном итоге приведет к тому что Предупреждение исчезнет. Однако это потребует большого количества ресурсов поисковой системы, которая и дальше продолжит периодически заглядывать, не убран ли запрет.
Хотя эти страницы и без того потихоньку отвалятся.
Меры предосторожности
В первую очередь не нужно плодить ссылки на закрытые страницы, это проблемы и помимо обозначенной в данной статье.
Многие вещи возможно реализовать по событиям js, это сократит вероятность.
Кроме того относительные url вместо абсолютных в скриптах осложнят распознание ссылок.
Robots.txt – это один из простейших файлов на вашем сайте. Но в нём же проще всего сделать опасную ошибку. Всего один символ, который стоит не на месте – и ваше SEO летит в тартарары. Поисковики не видят на вашем сайте того, что вы хотели им показать, но прекрасно считывают закрытую информацию. Ваша миссия провалена. Даже опытные SEO-шники иногда допускают такие ошибки, что уж говорить о начинающих. Если вы до сих пор не знаете, как правильно работать с robots.txt, или уже где-то ошиблись и не хотите, чтобы это повторилось, читайте наш разбор.
Краткая справка
Файл robots.txt – это свод правил для поисковых роботов. «Туда не ходи, сюда ходи» и всё такое. Здесь нужно перечислить весь контент, который вы хотите скрыть от роботов. И большинство поисковиков выполняет требования файла. Но не все. И нет, Google не среди непослушных. Также в этом файле можно объяснить некоторым ботам, как именно можно краулить разрешённый контент. А вот это для Google уже не будет руководством к действию.
Как выглядит файл
Общая схема такова:
Выглядит пугающе и непонятно, если вы ещё никогда не работали с такими файлами. Но синтаксис здесь на самом деле простой. Вы называете робота, к которому обращаетесь, и предъявляете ему список команд-директив. Как зовут роботов и что им приказывать, разберёмся дальше.
Имена агентов
Вы можете дать разные разрешения отдельным поисковикам. Для этого нужно знать, как обращаться к роботам каждой системы. Вот самые полезные из имён:
- Яндекс – Yandex.
- Google – Googlebot.
- Google Images – Googlebot-Image.
- Mail.ru – Mail.ru.
- Bing – Bingbot.
- Yahoo – Slurp.
- Baidu – Baiduspider.
- DuckDuckGo – DuckDuckBot.
Учтите, что имена нужно вводить именно так, как они здесь написаны, с дефисами и разным регистром.
Если вы хотите дать команду всем ботам, то вместо имени введите *. А если открыть доступ только Google, можно запретить краулинг всем роботам, кроме гугл-бота. Это выглядит так:
Боты выполняют наиболее конкретные команды, поэтому первую гугл-бот проигнорирует и спокойно будет сканировать сайт по разрешению второй директивы.
Вообще вы можете добавить сколько угодно индивидуальных директив и обратиться к бесконечному числу агентов. Но если вы так делаете, помните, что тогда робот-паук считывает только то, что обращено к нему. И для каждого бота вам нужно будет ввести весь список команд. Команды для второго робота первому не указ. Но если вы ввели две и больше директивы под одним именем, то всё нормально.
Директивы
Какие же приказы роботы поймут? Посмотрим на примере робота Google.
Disallow
Это «кирпич», выставленный на пути бота к какой-то странице. Если вы не хотите, чтобы в поиске были страницы вашего блога, вставьте такой код:
Здесь нужно внимательно следить за адресом страницы. Если там будет опечатка, или вы забудете вставить в строчку сам адрес, боты просто проигнорируют эту директиву.
Allow
Продолжаем историю с блогом. Вы написали мегаполезную статью и хотите поделиться ею со всем миром. Но поисковики её не увидят. Она же в закрытой части сайта. Надо открыть. Используем директиву:
Теперь робот увидит вашу статью, но остальной блог останется для него закрытым. Здесь тоже следите, правильно ли написан адрес.
Конфликты директив
Прервём список для важного уточнения. Иногда директивы из-за ошибки противоречат друг другу. Вот так, например:
Роботу одновременно разрешают и запрещают просматривать блог. Как разрешить противоречие? Google и Bing выбирают ту, в которой больше символов. То есть здесь они не пойдут в блог, потому что в запрете на один символ больше. А если бы команды были одинаковы по длине, тогда выбор этих систем пал на тот вариант, который даёт просмотреть больше страниц. То есть разрешительный. Другие роботы поступают по-другому: они принимают первую директиву, игнорируя другие.
Sitemap
Директива от адреса, где список со страницами лежит. Это те страницы, которые поисковик может просматривать и индексировать. Директива выглядит так:;
Она не относится к какому-то боту, а по умолчанию указывает путь всем. Поэтому её лучше включать в начале или конце robots.txt.
Эти три директивы, кроме Google, поддерживают так же Яндекс, Bing и большинство поисковиков.
Crawl-delay
А вот эту Google больше не поддерживает. Хотя Яндекс и Bing оставили её в списке используемых. Этой директивой можно задать количество секунд, которое должно пройти между загрузкой страниц. Паузы помогут снизить нагрузку на ваш сервер. Если вы зададите промежуток в 5 секунд, тогда за сутки бот проверит 17280 страниц. Если у вас их больше, стоит уменьшить паузу.
Noindex
Google отрицает, что эта директива когда-либо существовала, а 1 сентября 2019 года окончательно поставила точку, официально заявив, что noindex не поддерживается. Если хотите закрыть что-то от индексации, используйте другие способы: мета-теги для роботов или специальные заголовки.
Nofollow
Тоже никогда не имела официальной поддержки Google и от неё тоже отказались 1 сентября. Теперь запретить роботам переходить по ссылкам на странице только тегами и http-заголовками.
Clean-param
А это директива Яндекса. Её используют, чтобы очистить адрес страницы от идентификаторов сессий или пользователей, а также меток, которые не влияют на содержимое сайта.
Кириллица в robots.txt
Ещё одно отступление. В файл нельзя вставлять текст, написанный русскими буквами. Его нужно перевести в кодировку структуры вашего сайта.
А вам точно нужен robots.txt?
В принципе, небольшим сайтам не обязательно иметь этот файл. Но с ним лучше, чем без него. Благодаря ему, вы лучше контролируете, что поисковики могут и не могут делать на вашем сайте. То есть вы можете быть уверены, что:
- поисковые роботы не найдут страницы-дубликаты;
- некоторые части сайта останутся только для ваших глаз (например, ещё не протестированные страницы);
- нагрузка на сервер будет меньше;
- Google не будет впустую тратить бюджет на краулинг;
- ваши изображения, видео и файлы не попадут в поисковую выдачу.
Но с другой стороны, запреты на индексацию в robots.txt не дают 100%-ной гарантии, что закрытая страница не засветится в поиске. Например, если на эту страницу ведут ссылки с других сайтов, она может раскрыться в выдаче.
Работаем с файлом
Где найти robots.txt
Если на вашем сайте уже есть этот файл, значит, он лежит по адресу site-name.ru/robots.txt.
Делаем с нуля
Ну а если файла нет, надо его сделать. Открывайте блокнот и печатайте директивы. Или открывайте генераторы robots.txt и вбивайте данные туда. Эти генераторы помогают избежать большей части ошибок. Но они часто не очень хорошо кастомизируются.
Куда загрузить файл
На тот сайт, который вы имели в виду, когда прописывали все правила. Если это site-name.ru, то грузите прямо в корень, чтобы потом найти файл по адресу site-name.ru/robots.txt. А если blog.site-name.ru, то blog.site-name.ru/robots.txt.
Полезные советы
С общими правилами мы разобрались. Надеемся, вам стало понятнее, как работать с robots.txt. Перейдём к практическим советам.
Новая директива – новая строка
Если не разделять правила, робот может их не считать. Кроме того, когда всё написано в одну строчку, легче пропустить ошибку.
Используйте * для упрощения инструкций
Знак * можно использовать не только для обращения ко всем роботам, но и для сокращения адресов в командах. Например, вы не хотите, чтобы боты заходили на товарные страницы категорий с настроенными параметрами. Можно прописать адреса всех этих страниц.
Или заменить их одной строчкой и запретить краулинг всех страниц в products, которые заканчиваются вопросительным знаком. То есть все, в которых пользователь что-то настраивал.
Также можно полностью блокировать путь в любую категорию на сайте, если вам это нужно.
Ставьте $ в конце адреса
Чтобы показать боту, где заканчивается нужный URL, используйте знак доллара. Для примера: если вам нужно запретить ботам просматривать ваши pdf-ки, в вашем robots.txt должна быть такая строчка:
Это перекроет путь ко всем страницам, чей адрес заканчивается на .pdf, но не к тем, у которых в конце стоит что-то типа /file.pdf?id=1234455665.
Обращайтесь к каждому агенту только раз
Это не правило, а именно совет. Google считает команды правильно и в таком виде:
Но тогда у вас станет в два раза больше строчек, в которых можно ошибиться. Лучше упростите себе работу и объедините все директивы под одним обращением:
Конкретизируйте
Общие инструкции могут привести к катастрофическим последствиям. Представьте, что вы ведёте сайт на двух языках – русском и английском. Но вторая часть ещё не до конца готова, но уже размещена на ресурсе. Вы каждый день что-то дополняете и меняете. И вам не нужно, чтобы поисковые роботы постоянно это индексировали. Английская версия сайта доступна по адресу site-name.ru/en. Вы прописываете в robots.txt:
Робот не заходит в английскую версию, но заодно и на другие сайты:
/entrycode/enablenotifications/envydwarf/enoughofthiskerfuffle.pdf
Чтобы этого избежать, добавьте в код после en слэш.
Добавьте в robots.txt комментарии для людей
Да, файл называется «роботы». И да, мы там прописываем инструкции для роботов. Но люди их тоже читают. Оставьте комментарии для других разработчиков или же себя в будущем. Начинайте предложение с #, тогда роботы не будут читать этот комментарий.
Каждому поддомену – отдельный файл
Роботы выполняют инструкции только на том домене, куда загружен файл. Если у вас есть хотя бы один поддомен, например, blog.site-name.ru, значит, для него нужно делать отдельный robots.txt, итого два файла. Два поддомена – три файла и так далее. Каждый нужно выложить на своём поддомене.
Примеры файлов robots.txt
Вот вам примеры директив для вдохновения. Хотя, если они вам подойдут, можете спокойно копипастить их к себе в robots.txt.
Свободный доступ для всех ботов
User-agent: *Disallow:
Если вы не добавите сюда адрес, для ботов это будет значить, что ни у одной страницы нет запрета на краулинг. То есть вы дадите им доступ ко всем адресам на сайте.
Общий запрет
User-agent: *Disallow: /
Обратная ситуация. Доступ к любой странице перекрыт директивой.
Перекрытие доступа к одному разделу
User-agent: *Disallow: /folder/
Вместо folder пишем название вашего раздела.
Разрешить доступ к одному файлу из закрытой папки
User-agent: *Disallow: /folder/Allow: /folder/page.html
Тоже кастомизируем адреса под себя.
Скрываем любой файл
User-agent: *Disallow: /file.pdf
Запрет доступа к определённому формату файлов. На примере pdf.
User-agent: *Disallow: /*.pdf$
Перекрыть доступ одного бота к страницам с пользовательскими параметрами
User-agent: GooglebotDisallow: /*?
На месте Googlebot может быть любой другой агент.
Как проверить robots.txt на ошибки
Если вам важна видимость в Google, используйте его инструменты. В Яндексе они все объединены в Вебмастере. Итак, разберём ошибки на примере Google. Провести аудит можно через сервис Search Console. Вам нужен отчёт о доступности. Что вы можете там обнаружить?
Адрес заблокирован robots.txt
Это значит, что хотя бы один из адресов в вашей карте сайта недоступен из-за директивы в robots.txt. В карте не должно быть ни одной страницы, которую вы не хотите индексировать и на которой работает редирект. Если у вас отображается эта ошибка, значит, в карту просочилось что-то запрещённое. Как найти, какая именно страница недоступна ботам? Перейдите в тестер robots.txt, там запрещающая директива будет видна. И исправьте ошибку: либо уберите ссылку на эту страницу из карты сайта, или разрешите к ней доступ.
Заблокировано robots.txt
Эта ошибка говорит о том, что бот не может проиндексировать какой-то контент. Если вам нужно, чтобы Google всё-таки его проиндексировал, откройте закрытый в robots.txt доступ. И убедитесь, что на контенте не висит тег noindex. А если контент должен остаться невидимым для поисковика, то всё равно уберите блок на краулинг, а контент перекройте тегами или http-заголовком. Тогда Google увидит запрет на индексацию и точно выполнит это требование.
Проиндексировано, но заблокировано robots.txt
Это значит, что Google проиндексировал часть закрытого контента. То есть вы попытались перекрыть доступ через robots.txt, но у вас не получилось. Google не видит запрет на индексацию, если доступ к странице закрыт. Решение такое же, как и в прошлом случае.
И ещё немного полезной информации:
- Максимальный размер robots.txt – около 500 кб.
- Где найти robots.txt в WordPress? Там же, где и у остальных: site-name.ru/robots.txt. Редактировать его можно через специальные плагины.
- Файл robots.txt Битрикс доступен для редактирования в админ панели в разделе Маркетинг – Поисковая оптимизация – Настройка robots.txt
Подробный SEO-гайд по Отчёту об индексировании Google Search Console. Разберёмся, как проверить индексацию сайта с его помощью, как «читать» статусы URL, какие ошибки можно обнаружить и как их исправить.
Перевод с сайта onely.com.
В Отчёте вы можете получить данные о сканировании и индексации всех URL-адресов, которые Google смог обнаружить на вашем сайте. Он поможет отследить, добавлен ли сайт в индекс, и проинформирует о технических проблемах со сканированием и индексацией.
Но перед тем, как говорить об Отчёте, вспомним все этапы индексации страницы в Google.
Как проходит индексация в Google
Чтобы страница ранжировалась в поиске и показывалась пользователям, она должна быть обнаружена, просканирована и проиндексирована.
Обнаружение
Перед тем, как просканировать страницу, Google должен её обнаружить. Он может сделать это несколькими способами.
Наиболее распространённые — с помощью внутренних или внешних ссылок или через карту сайта (файл Sitemap.xml).
Сканирование
Суть сканирования состоит и том, что поисковые системы изучают страницу и анализируют её содержимое.
Главный аспект в этом вопросе — краулинговый бюджет, который представляет собой лимит времени и ресурсов, который поисковая система готова «потратить» на сканирование вашего сайта.
Что такое «краулинговый бюджет, как его проверить и оптимизировать
Индексация
В процессе индексации Google оценивает качество страницы и добавляет её в индекс — базу данных, где собраны все страницы, о которых «знает» Google.
В этот этап включается и рендеринг, который помогает Google видеть макет и содержимое страницы. Собранная информация даёт поисковой системе понимание, как показывать страницу в результатах поиска.
Даже если Google нашёл и просканировал страницу, это не означает, что она обязательно будет проиндексирована.
Но главное, что вы должны понять и запомнить: нет необходимости в том, чтобы абсолютно все страницы вашего сайты были проиндексированы. Вместо этого убедитесь, что в индекс включены все важные и полезные для пользователей страницы с качественным контентом.
Некоторые страницы могут содержать контент низкого качества или быть дублями. Если поисковые системы их увидят, это может негативно отразится на всём сайте.
Поэтому важно в процессе создания стратегии индексации решить, какие страницы должны и не должны быть проиндексированы.
Ранжирование
Только проиндексированные страницы могут появиться в результатах поиска и ранжироваться.
Google определяет, как ранжировать страницу, основываясь на множестве факторов, таких как количество и качество ссылок, скорость страницы, удобство мобильной версии, релевантность контента и др.
Теперь перейдём к Отчёту.
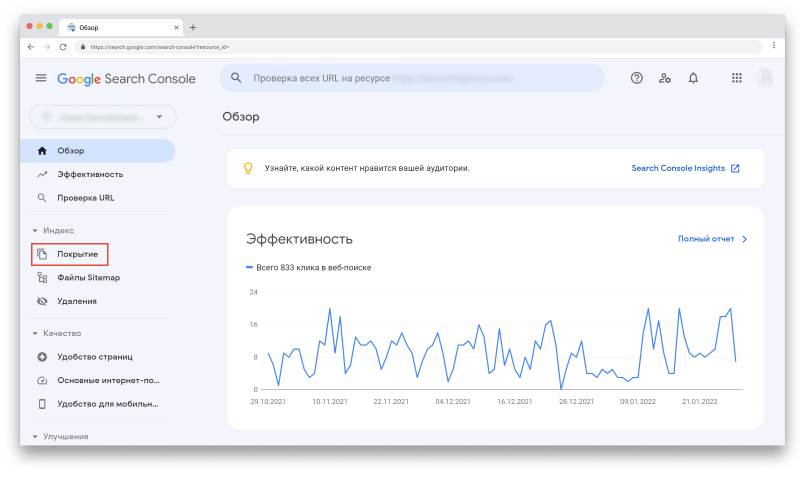
Как пользоваться Отчётом об индексировании в Google Search Console
Чтобы просмотреть Отчёт, авторизуйтесь в своём аккаунте Google Search Console. Затем в меню слева выберите «Покрытие» в секции «Индекс»:
Перед вами Отчёт. Отметив галочками любой из статусов или все сразу, вы сможете выбрать то, что хотите визуализировать на графике:
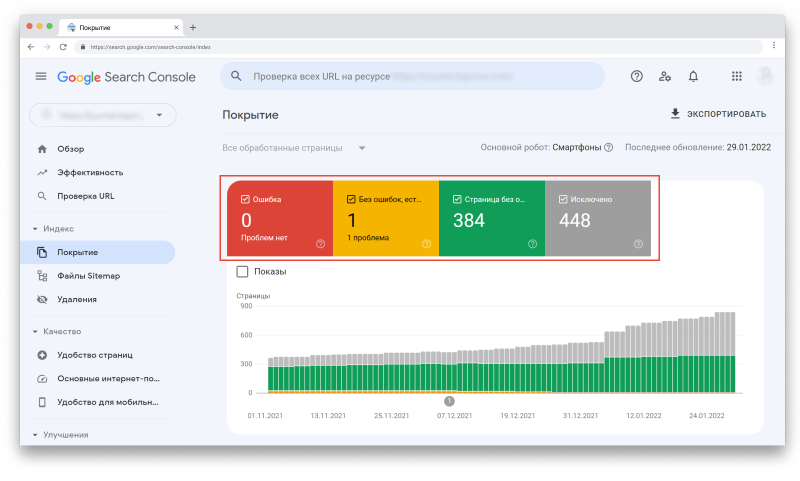
Вы увидите четыре статуса URL-адресов:
- Ошибка — критическая проблема сканирования или индексации.
- Без ошибок, есть предупреждения — URL-адреса проиндексированы, но содержат некоторые некритичные ошибки.
- Страница без ошибок — страницы проиндексированы корректно.
- Исключено — страницы, которые не были проиндексированы из-за проблем (это самый важный раздел, на котором нужно сфокусироваться).
Фильтры «Все обработанные страницы» vs «Все отправленные страницы»
В верхнем углу вы можете отфильтровать, какие страницы хотите видеть:
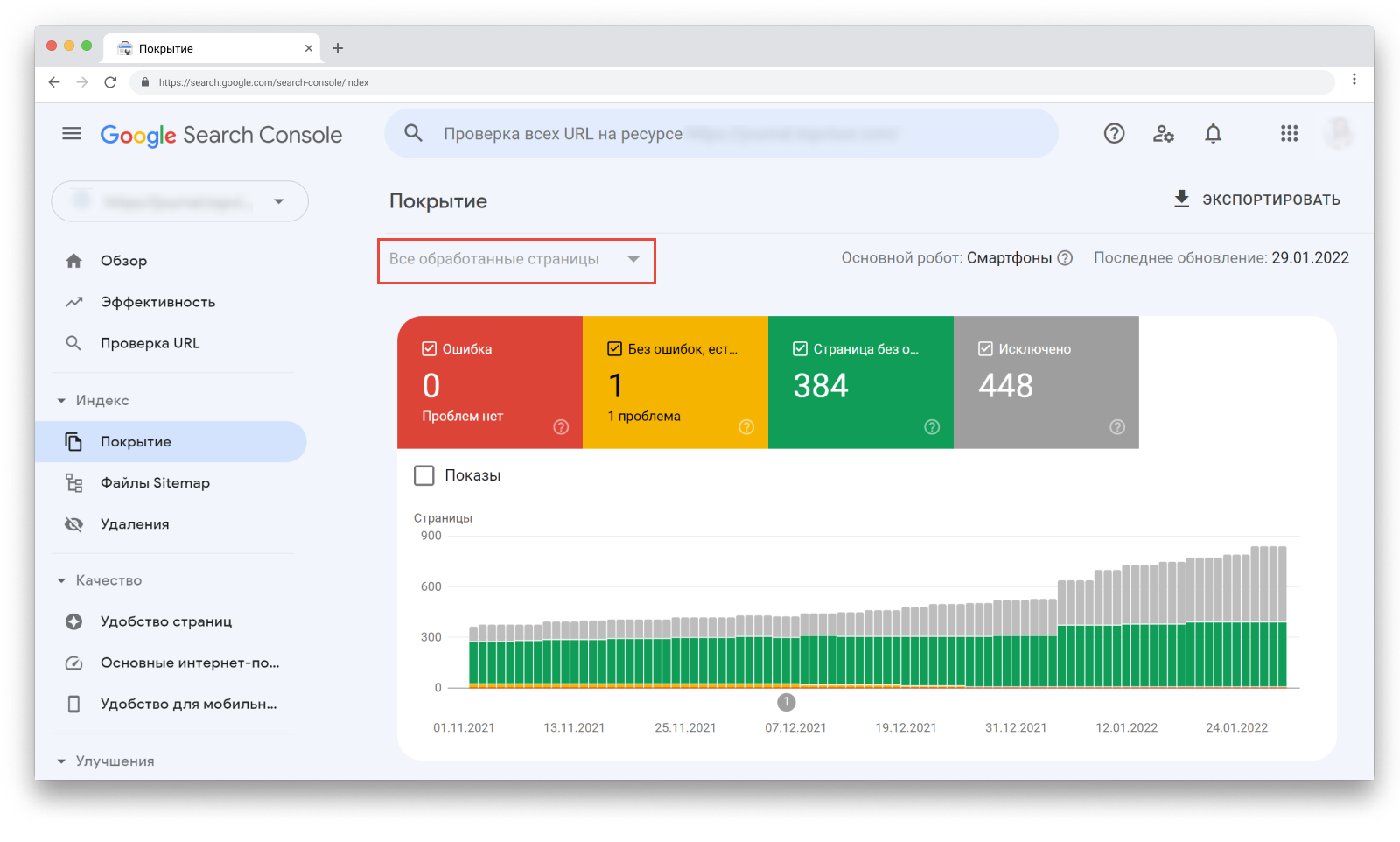
«Все обработанные страницы» показываются по умолчанию. В этот фильтр включены все URL-адреса, которые Google смог обнаружить любым способом.
Фильтр «Все отправленные страницы» включает только URL-адреса, добавленные с помощью файла Sitemap.
В чём разница?
Первый обычно включает в себя больше URL-адресов и многие из них попадают в секцию «Исключено». Это происходит потому, что карта сайта включает только индексируемые URL, в то время как сайты обычно содержат множество страниц, которые не должны быть проиндексированы.
Как пример — URL с параметрами на сайтах eCommerce. Googlebot может найти их разными способами, но не в карте сайта.
Так что когда открываете Отчёт, убедитесь, что смотрите нужные данные.
Проверка статусов URL
Чтобы увидеть подробную информацию о проблемах, обнаруженных для каждого статуса, посмотрите «Сведения» под графиком:

Тут показан статус, тип проблемы и количество затронутых страниц. Обратите внимание на столбец «Проверка» — после исправления ошибки, вы можете попросить Google проверить URL повторно.
Например, если кликнуть на первую строку со статусом «Предупреждение», то вверху появится кнопка «Проверить исправление»:
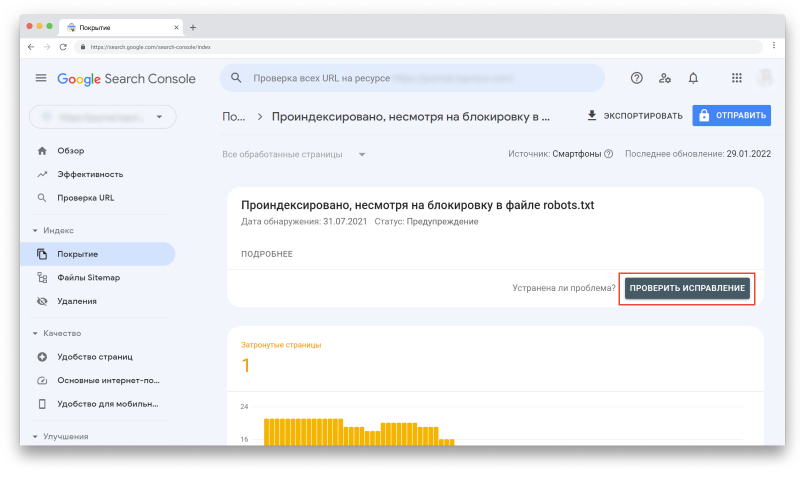
Вы также можете увидеть динамику каждого статуса: увеличилось, уменьшилось или осталось на том же уровне количество URL-адресов в этом статусе.
Если в «Сведениях» кликнуть на любой статус, вы увидите количество адресов, связанных с ним. Кроме того, вы сможете посмотреть, когда каждая страница была просканирована (но помните, что эта информация может быть неактуальна из-за задержек в обновлении отчётов).
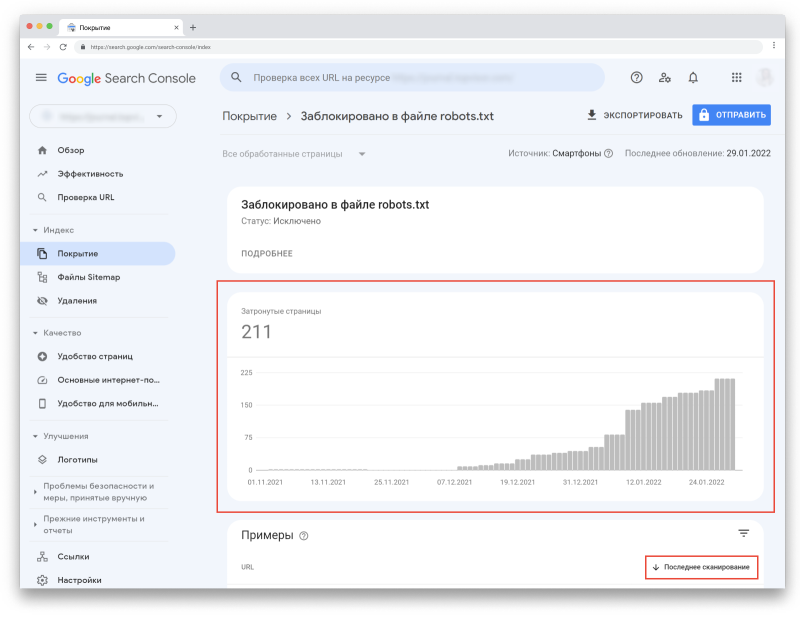
Что учесть при использовании отчёта
- Всегда проверяйте, смотрите ли вы отчёт по всем обработанным или по всем отправленным страницам. Разница может быть очень существенной.
- Отчёт может показывать изменения с задержкой. После публикации контента подождите несколько дней, пока страницы просканируются и проиндексируются.
- Google пришлёт уведомления на электронную почту, если увидит какие-то критичные проблемы с сайтом.
- Стремитесь к индексации канонической версии страницы, которую вы хотите показывать пользователям и поисковым ботам.
- В процессе развития сайта, на нём будет появляться больше контента, так что ожидайте увеличения количества проиндексированных страниц в Отчёте.
Как часто смотреть Отчёт
Обычно достаточно делать это раз в месяц.
Но если вы внесли значимые изменения на сайте, например, изменили макет страницы, структуру URL или сделали перенос сайта, мониторьте Отчёт чаще, чтобы вовремя поймать негативное влияние изменений.
Рекомендую делать это хотя бы раз в неделю и обращать особое внимание на статус «Исключено».
Дополнительно: инструмент проверки URL
В Search Console есть ещё один инструмент, который даст ценную информацию о сканировании и индексации страниц вашего сайта — Инструмент проверки URL.
Он находится в самом верху страницы в GSC:
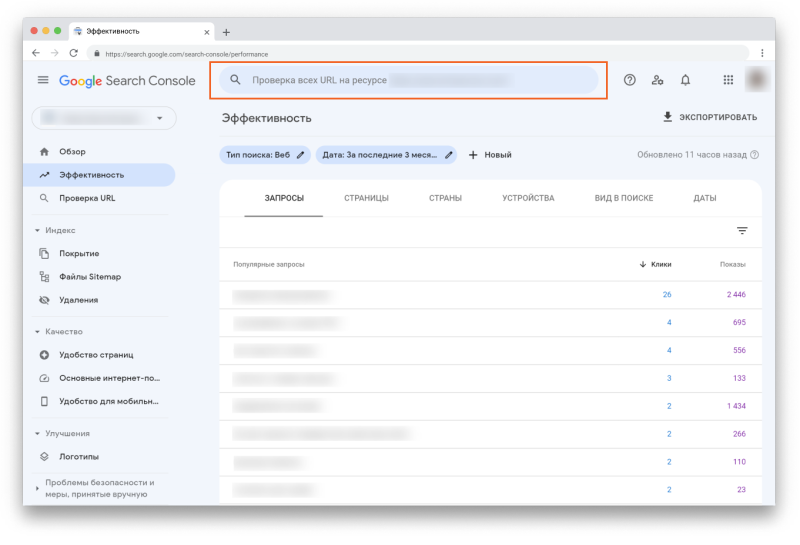
Просто вставьте URL, который вы хотите проверить, в эту строку и увидите данные по нему. Например:

Инструментом можно пользоваться для того, чтобы:
- проверить статус индексирования URL, и обнаружить возможные проблемы;
- узнать, индексируется ли URL;
- просмотреть проиндексированную версию URL;
- запросить индексацию, например, если страница изменилась;
- посмотреть загруженные ресурсы, например, такие как JavaScript;
- посмотреть, какие улучшения доступны для URL, например, реализация структурированных данных или удобство для мобильных.
Если в Отчёте об индексировании обнаружены какие-то проблемы со страницами, используйте Инструмент, чтобы тщательнее проверить их и понять, что именно нужно исправить.
Статус «Ошибка»
Под этим статусом собраны URL, которые не были проиндексированы из-за ошибок.
Если вы видите проблему с пометкой «Отправлено», то это может касаться только URL, которые были отправлены через карту сайту. Убедитесь, что в карте сайте содержатся только те страницы, которые вы действительно хотите проиндексировать.
Ошибка сервера (5xx)
Эта проблема говорит об ошибке сервера со статусом 5xx, например, 502 Bad Gateway или 503 Service Unavailable.
Советую регулярно проверять этот раздел и следить, нет ли у Googlebot проблем с индексацией страниц из-за ошибки сервера.
Что делать. Нужно связаться с вашим хостинг-провайдером, чтобы исправить эту проблему или проверить, не вызваны ли эти ошибки недавними обновлениями и изменениями на сайте.
Как исправить ошибки сервера — рекомендации Google
Ошибка переадресации
Редиректы перенаправляют поисковых ботов и пользователей со старого URL на новый. Обычно они применяются, если старый адрес изменился или страницы больше не существует.
Ошибки переадресации могут указывать на такие проблемы:
- цепочка редиректов слишком длинная;
- обнаружен циклический редирект — страницы переадресуют друг на друга;
- редирект настроен на страницу, URL которой превышает максимальную длину;
- в цепочке редиректов найден пустой или ошибочный URL.
Что делать. Проверьте и исправьте редиректы каждой затронутой страницы.
Доступ к отправленному URL заблокирован в файле robots.txt
Эти страницы есть в файле Sitemap, но заблокированы в файле robots.txt.
Robots.txt — это файл, который содержит инструкции для поисковых роботов о том, как сканировать ваш сайт. Чтобы URL был проиндексирован, Google нужно для начала его просканировать.
Что делать. Если вы видите такую ошибку, перейдите в файл robots.txt и проверьте настройку директив. Убедитесь, что страницы не закрыты через noindex.
Страница, связанная с отправленным URL, содержит тег noindex
По аналогии с предыдущей ошибкой, эта страница была отправлена на индексацию, но она содержит директиву noindex в метатеге или в заголовке ответа HTTP.
Что делать. Если страница должна быть проиндексирована, уберите noindex.
Отправленный URL возвращает ложную ошибку 404
Ложная ошибка 404 означает, что страница возвращает статус 200 OK, но её содержимое может указывать на ошибку. Например, страница пустая или содержит слишком мало контента.
Что делать. Проверьте страницы с ошибками и посмотрите, есть ли возможность изменить контент или настроить редирект.
Отправленный URL возвращает ошибку 401 (неавторизованный запрос)
Ошибка 401 Unauthorized означает, что запрос не может быть обработан, потому что необходимо залогиниться под правильными user ID и паролем.
Что делать. Googlebot не может индексировать страницы, скрытые за логинами. Или уберите необходимость авторизации или подтвердите авторизацию Googlebot, чтобы он мог получить доступ к странице.
Отправленный URL не найден (ошибка 404)
Ошибка 404 говорит о том, что запрашиваемая страница не найдена, потому что была изменена или удалена. Такие страницы есть на каждом сайте и наличие их в малом количестве обычно ни на что не влияет. Но если пользователи будут находить такие страницы, это может отразиться негативно.
Что делать. Если вы увидели эту проблему в отчёте, перейдите на затронутые страницы и проверьте, можете ли вы исправить ошибку. Например, настроить 301-й редирект на рабочую страницу.
Дополнительно убедитесь, что файл Sitemap не содержит URL, которые возвращают какой-либо другой код состояния HTTP кроме 200 OK.
При отправке URL произошла ошибка 403
Код состояния 403 Forbidden означает, что сервер понимает запрос, но отказывается авторизовывать его.
Что делать. Можно либо предоставить доступ анонимным пользователям, чтобы робот Googlebot мог получить доступ к URL, либо, если это невозможно, удалить URL из карты сайта.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Страница может быть непроиндексирована из-за других ошибок 4xx, которые не описаны выше.
Что делать. Чтобы понять, о какой именно ошибке речь, используйте Инструмент проверки URL. Если устранить ошибку невозможно, уберите URL из карты сайта.
Статус «Без ошибок, есть предупреждения»
URL без ошибок, но с предупреждениями, были проиндексированы, но могут требовать вашего внимания. Тут обычно случается две проблемы.
Проиндексировано, несмотря на блокировку в файле robots.txt
Обычно эти страницы не должны быть проиндексированы, но скорее всего Google нашёл ссылки, указывающие на них, и посчитал их важными.
Что делать. Проверьте эти страницы. Если они всё же должны быть проиндексированы, то обновите файл robots.txt, чтобы Google получил к ним доступ. Если не должны — поищите ссылки, которые на них указывают. Если вы хотите, чтобы URL были просканированы, но не проиндексированы, добавьте директиву noindex.
Страница проиндексирована без контента
URL проиндексированы, но Google не смог прочитать их контент. Это может быть из-за таких проблем:
- Клоакинг — маскировка контента, когда Googlebot и пользователи видят разный контент.
- Страница пустая.
- Google не может отобразить страницу.
- Страница в формате, который Google не может проиндексировать.
Зайдите на эти страницы сами и проверьте, виден ли на них контент. Также проверьте их через Инструмент проверки URL и посмотрите, как их видит Googlebot. После того, как устраните ошибки, или если не обнаружите каких-либо проблем, вы можете запросить у Google повторное индексирование.
Статус «Страница без ошибок»
Здесь показываются страницы, которые корректно проиндексированы. Но на эту часть Отчёта всё равно нужно обращать внимание, чтобы сюда не попали страницы, которые не должны были оказаться в индексе. Тут тоже есть два статуса.
Страница была отправлена в Google и проиндексирована
Это значит, что страницы отправлена через Sitemap и Google её проиндексировал.
Страница проиндексирована, но её нет в файле Sitemap
Это значит, что страница проиндексирована даже несмотря на то, что её нет в Sitemap. Посмотрите, как Google нашёл эту страницу, через Инструмент проверки URL.
Чаще всего страницы в этом статусе — это страницы пагинации, что нормально, учитывая, что их и не должно быть в Sitemap. Посмотрите список этих URL, вдруг какие-то из них стоит добавить в карту сайта.
Статус «Исключено»
В этом статусе находятся страницы, которые не были проиндексированы. В большинстве случаев это вызвано теми же проблемами, которые мы обсуждали выше. Единственное различие в том, что Google не считает, что исключение этих страниц вызвано какой-либо ошибкой.
Вы можете обнаружить, что многие URL здесь исключены по разумным причинам. Но регулярный просмотр Отчёта поможет убедиться, что не исключены важные страницы.
Индексирование страницы запрещено тегом noindex
Что делать. Тут то же самое — если страница и не должна быть проиндексирована, то всё в порядке. Если должна — удалите noindex.
Индексирование страницы запрещено с помощью инструмента удаления страниц
У Google есть Инструмент удаления страниц. Как правило с его помощью Google удаляет страницы из индекса не навсегда. Через 90 дней они снова могут быть проиндексированы.
Что делать. Если вы хотите заблокировать страницу насовсем, вы можете удалить её, настроит редирект, внедрить авторизацию или закрыть от индексации с помощью тега noindex.
Заблокировано в файле robots.txt
У Google есть Инструмент проверки файла robots.txt, где вы можете в этом убедиться.
Что делать. Если эти страницы и не должны быть в индексе, то всё в порядке. Если должны — обновите файл robots.txt.
Помните, что блокировка в robots.txt — не стопроцентный вариант закрыть страницу от индексации. Google может проиндексировать её, например, если найдёт ссылку на другой странице. Чтобы страница точно не была проиндексирована, используйте директиву noindex.
Подробнее о блокировке индексирования при помощи директивы noindex
Страница не проиндексирована вследствие ошибки 401 (неавторизованный запрос)
Обычно это происходит на страницах, защищённых паролем.
Что делать. Если они и не должны быть проиндексированы, то ничего делать не нужно. Если вы не хотите, чтобы Google обнаруживал эти страницы, уберите существующие внутренние и внешние ссылки на них.
Страница просканирована, но пока не проиндексирована
Это значит, что страница «ждёт» решения. Для этого может быть несколько причин. Например, с URL нет проблем и вскоре он будет проиндексирован.
Но чаще всего Google не будет торопиться с индексацией, если контент недостаточно качественный или выглядит похожим на остальные страницы сайта.
В этом случае он поставит её в очередь с низким приоритетом и сфокусируется на индексации более важных страниц. Google говорит, что отправлять такие страницы на переиндексацию не нужно.
Что делать. Для начала убедитесь, что это не ошибка. Проверьте, действительно ли URL не проиндексирован, в Инструменте проверки URL или через инструмент «Индексация» в Анализе сайта в Топвизоре. Они показывают более свежие данные, чем Отчёт.
Как исправить ошибку, когда страница просканирована, но не проиндексирована (на английском)
Обнаружена, не проиндексирована
Это значит, что Google увидел страницу, например, в карте сайта, но ещё не просканировал её. В скором времени страница может быть просканирована.
Иногда эта проблема возникает из-за проблем с краулинговым бюджетом. Google может посчитать сайт некачественным, потому что ему не хватает производительности или на нём слишком мало контента.
Что такое краулинговый бюджет и как его оптимизировать
Возможно, Google не нашёл каких-либо ссылок на эту страницу или нашёл страницы с большим ссылочным весом и посчитал их более приоритетными для сканирования.
Если на сайте есть более качественные и важные страницы, Google может игнорировать менее важные страницы месяцами или даже никогда их не просканировать.
Вариант страницы с тегом canonical
Эти URL — дубли канонической страницы, отмеченные правильным тегом, который указывает на основную страницу.
Что делать. Ничего, вы всё сделали правильно.
Страница является копией, канонический вариант не выбран пользователем
Это значит, что Google не считает эти страницы каноническими. Посмотрите через Инструмент проверки URL какую страницу он считает канонической.
Что делать. Выберите страницу, которая по вашему мнению является канонической, и разметьте дубли с помощью rel=”canonical”.
Страница является копией, канонические версии страницы, выбранные Google и пользователем, не совпадают
Вы выбрали каноническую страницу, но Google решил по-другому. Возможно, страница, которую вы выбрали, не имеет столько внутреннего ссылочного веса, как неканоническая.
Что делать. В этом случае может помочь объединение URL повторяющихся страниц.
Как правильно настроить внутренние ссылки на сайте
Не найдено (404)
URL нет в Sitemap, но Google всё равно его обнаружил. Возможно, это произошло с помощью ссылки на другом сайте или ранее страница существовала и была удалена.
Что делать. Если вы и не хотели, чтобы Google индексировал страницу, то ничего делать не нужно. Другой вариант — поставить 301-й редирект на работающую страницу.
Страница с переадресацией
Эта страница редиректит на другую страницу, поэтому не была проиндексирована. Обычно, такие страницы не требуют внимания.
Что делать. Эти страницы и не должны быть проиндексированы, так что делать ничего не нужно.
Для постоянного редиректа убедитесь, что вы настроили перенаправление на ближайшую альтернативную страницу, а не на Главную. Редирект страницы с 404 ошибкой на Главную может определять её как soft 404.
@JohnMu what does Google do when a site redirects all its 404s to the homepage? Seeing more and more sites do this and it’s such an anti-pattern.
— Joost de Valk (@jdevalk) January 7, 2019
Yeah, it’s not a great practice (confuses users), and we mostly treat them as 404s anyway (they’re soft-404s), so there’s no upside. It’s not critically broken/bad, but additional complexity for no good reason – make a better 404 page instead.
— ? John ? (@JohnMu) January 8, 2019
Ложная ошибка 404
Обычно это страницы, на которых пользователь видит сообщение «не найдено», но которые не сопровождаются кодом ошибки 404.
Что делать. Для исправления проблемы вы можете:
- Добавить или улучшить контент таких страниц.
- Настроить 301-й редирект на ближайшую альтернативную страницу.
- Настроить сервер, чтобы он возвращал правильный код ошибки 404 или 410.
Страница является копией, отправленный URL не выбран в качестве канонического
Эти страницы есть в Sitemap, но для них не выбрана каноническая страница. Google считает их дублями и канонизировал их другими страницами, которые определил самостоятельно.
Что делать. Выберите и добавьте канонические страницы для этих URL.
Страница заблокирована из-за ошибки 403 (доступ запрещён)
Что делать. Если Google не может получить доступ к URL, лучше закрыть их от индексации с помощью метатега noindex или файла robots.txt.
URL заблокирован из-за ошибки 4xx (ошибка клиента)
Сервер столкнулся с ошибкой 4xx, которая не описана выше.
Гайд по ошибкам 4xx и способы их устранения (на английском)
Попробуйте исправить ошибки или оставьте страницы как есть.
Ключевые выводы
- Проверяя данные в Отчёте помните, что не все страницы сайта должны быть просканированы и проиндексированы.
- Закрыть от индексации некоторые страницы может быть так же важно, как и следить за тем, чтобы нужные страницы сайта индексировались корректно.
- Отчёт об индексировании показывает как критичные ошибки, так и неважные, которые не обязательно требуют действий с вашей стороны.
- Регулярно проверяйте Отчёт, но только для того, чтобы убедиться, что всё идёт по плану. Исправляйте только те ошибки, которые не соответствуют вашей стратегии индексации.
