Новичку очень трудно найти нужный символ или слово в массе кода, однако это делается очень быстро и просто. Если не знаете как, то читайте дальше.
В следующей статье, мы приступим к редактированию шаблона, и нам придётся находить нужные элементы в коде темы.
Если кто-то ещё не видел, что из себя представляет код шаблона, то зайдите в Консоль — Внешний вид — Редактор.
Перед Вами откроется код файла style.css. Покрутите его вниз, и первое, что придёт Вам в голову будет: ё-моё, как же в этой массе английских слов, цифр и символов, найти то, что нам будет нужно.
Для полноты ощущения, можно открыть один из php файлов, которые расположены в колонке справа от поля редактора.
Только сразу отгоните мысль типа: «Я в этом до самой смерти не разберусь». Разберётесь, и я Вам в этом помогу.
Рассмотрим два варианта, в зависимости от начальных условий, нахождения нужного элемента в коде.
Вариант 1.
Условие: мы точно знаем то, что нам нужно найти.
Для примера возьмём код страницы.
Комбинация клавиш Contrl-F откроет окно поиска в правом верхнем углу, в которое можно ввести искомый элемент кода. Элемент и все его повторения подсветятся.
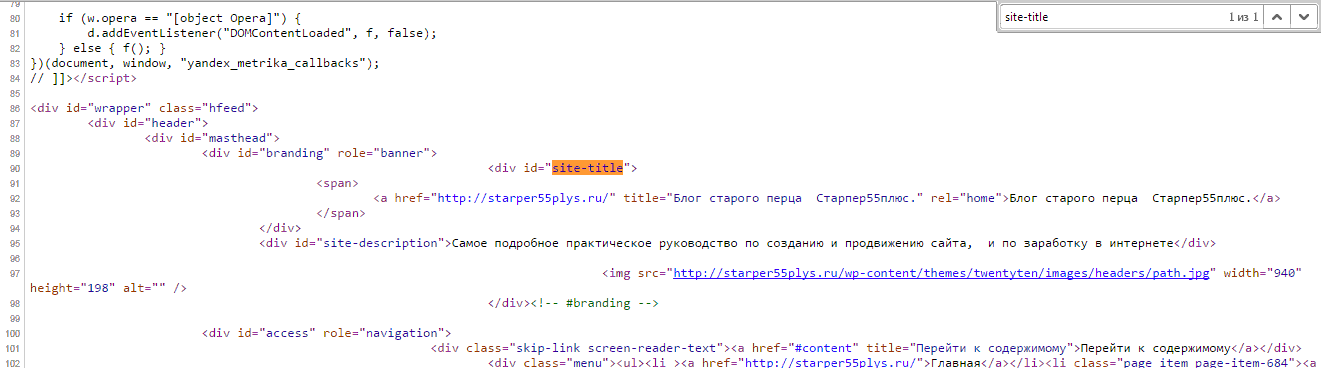
Этот поиск работает абсолютно для любого кода, открытого в браузере, то есть на странице.
Вариант 2.
Условие: мы видим элемент на странице, но не знаем ни его html, ни css.
В этом случае потребуется web-инспектор, или по другому Инструмент разработчика.
Инструмент разработчика есть во всех браузерах и открыть его можно или клавишей F12, или правой клавишей мыши, выбрав “Просмотреть код” или “Исследовать элемент”. В разных браузерах по разному.
Главное не выбирайте “Просмотреть код страницы”. Похоже, но не то.
После этого появится web-инспектор. Его интерфейс в разных браузерах немного отличается, но принцип действия везде одинаковый.
Я покажу на примере web-инспектора Chrome.
Заходим на страницу и открываем web-инспектор. По умолчанию он откроется в двух колонках, в левой будет html код всех элементов, находящихся на странице, а в правой — css оформление.
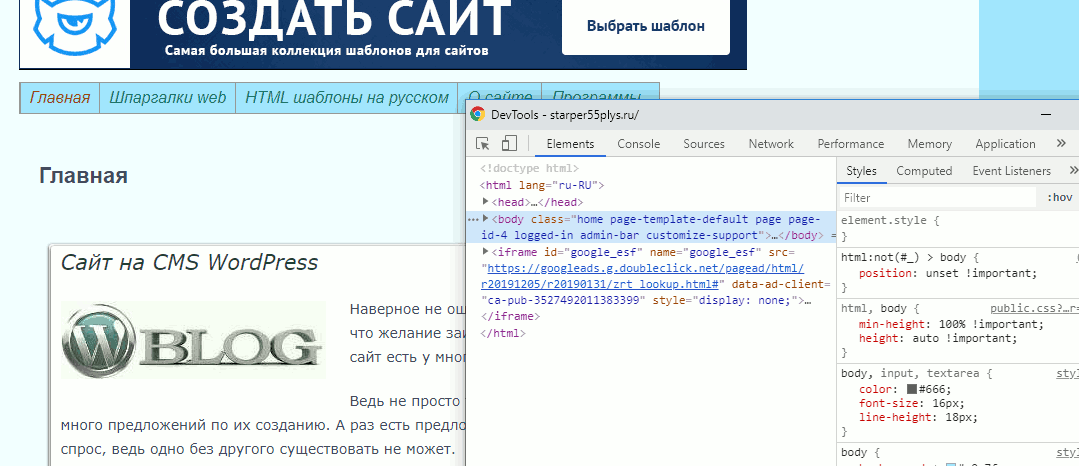
Изначально, код откроется в сложенном виде, то есть будут видны только основные элементы страницы, но если щёлкнуть по треугольничку в начале строки, то откроются все вложения, находящиеся в элементе.
И вот так, открывая вложение за вложением, можно добраться практически до любого элемента, находящегося на странице.
Определить, какой код, какому элементу соответствует, очень просто.
Надо просто вести по строкам курсором, и как только курсор оказывается на строке с кодом, так тут-же элемент, которому соответствует этот код, подсвечивается.
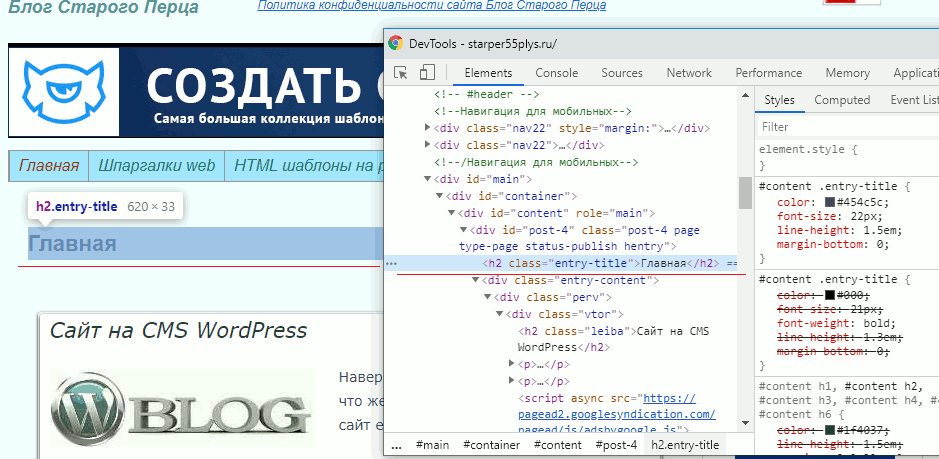
Теперь найдём css этого элемента. Для этого надо один раз щёлкнуть левой клавишей по строке с html, и в правой колонке отобразятся все стили, которые ему заданы, а так-же стили, влияющие на элемент, от родительских элементов.

Теперь, зная class или id элемента, можно спокойно идти в файл style.css, найти в нём нужный селектор, с помощью Поиска (Ctrl+F), и править внешний вид элемента.
Желаю творческих успехов.
Неужели не осталось вопросов? Спросить

Перемена
— Мам, ну почему ты думаешь, что если я была на дне рождения, то сразу пила?!
— Дочь а нечего что я папа?
Объявление в метро: «при обнаружении подозрительных предметов сделайте подозрительное лицо.
В раздел > > > Исправляем шаблон WordPress. Веб-инспектор
Раздел:
Сайтостроение /
JavaScript /
|
|
Что такое JavaScript
Небольшая книга о JavaScript, которая поможет вам в изучении JavaScript. В книге и рассылке сведения для начинающих: что такое JavaScript, как это работает, письма, которые помогут принять решение, надо ли вам это или нет, а также полезные ссылки на обучающие материалы. |

Иногда требуется программно найти определённый HTML-элемент в документе. В некоторых случаях сделать это можно перебором
всех элементов, как это мы уже делали ранее. Однако не всегда это удобно и уместно. Поэтому следует знать и другие способы.
Как всегда напоминаю, что полный обучающий курс по JavaScript можно найти здесь:
>>> JavaScript, jQuery и Ajax с нуля до гуру >>>
Способов поиска элемента с помощью JavaScript существует немало. В этой статье будут рассмотрены лишь некоторые, основанные на использовании следующих методов:
getElementById– поиск элемента по идентификатору IDgetElementsByTagName– поиск элементов по наименованию тегаgetElementsByClassName– поиск элементов по наименованию классаgetElementsByName– поиск элементов по имени
Обратите внимание, что первый метод ищет и возвращает только один элемент, поскольку подразумевается, что в пределах документа все идентификаторы должны быть уникальными.
Остальные методы ищут все элементы с совпадающими наименованиями и возвращают коллекцию (массив) элементов.
Далее разберём примеры использования всех этих методов, чтобы понять, как это можно использовать.
Поиск элемента по ID
Пример исходного кода:
<body>
<h2 id="header1">Заголовок 1</h2>
<h2 id="header2">Заголовок 2</h2>
<script>
<!--
function FindID(name)
{
var e = document.getElementById(name);
//Возвращает соответствующий элемент
return e;
}
var str = FindID('header1');
document.write(str.innerHTML, '<br>');
// -->
</script>
</body>
Браузер выведет следующее:

Метод getElementById находит в документе элемент с указанным
идентификатором и возвращает его. Ну а далее в сценарии мы выводим содержимое найденного элемента,
которое хранится в свойстве элемента innerHTML.
Поиск элементов по имени тега
Пример исходного кода:
<body>
<h2>Заголовок</h2>
<ul>
<liЭлемент списка 1</li>
<li>Элемент списка 2</li>
<li>Элемент списка 3</li>
<li>Элемент списка 4</li>
</ul>
<script>
<!--
function FindTag(name)
{
var r = [];
var e = document.getElementsByTagName(name);
for (var i = 0; i < e.length; i++)
r.push(e[i]);
//Возвращает список соответствующих элементов
return r;
}
var str = FindTag('li');
for (var i = 0; i < str.length; i++)
document.write(str[i].innerHTML, '<br>');
// -->
</script>
</body>
Браузер выведет следующее:

Поиск элементов по имени класса
Пример исходного кода:
<body>
<h2>Заголовок</h2>
<ul>
<li class="test">Элемент списка 1</li>
<li class="my test">Элемент списка 2</li>
<li class="my">Элемент списка 3</li>
<li class="test_4">Элемент списка 4</li>
</ul>
<script>
<!--
function FindClass(name)
{
var r = [];
var e = document.getElementsByClassName(name);
for (var i = 0; i < e.length; i++)
r.push(e[i]);
//Возвращает список соответствующих элементов
return r;
}
var str = FindClass('test');
for (var i = 0; i < str.length; i++)
document.write(str[i].innerHTML, '<br>');
// -->
</script>
</body>
Браузер выведет следующее:

Обратите внимание, что в поиск попадает и класс “my test”, потому что там есть слово test. Но это не страшно, поскольку имена классов обычно состоят из одного слова.
Поиск элементов по имени
Пример исходного кода:
<body>
<h2>Заголовок</h2>
<p name="p">
Первый абзац
</p>
<p name="p">
Второй абзац
</p>
<p name="p3">
Третий абзац
</p>
<script>
<!--
function FindName(name)
{
var r = [];
var e = document.getElementsByName(name);
for (var i = 0; i < e.length; i++)
r.push(e[i]);
//Возвращает список соответствующих элементов
return r;
}
var str = FindName('p');
for (var i = 0; i < str.length; i++)
document.write(str[i].innerHTML, '<br>');
// -->
</script>
</body>

Эта статья – лишь капля в море знаний о JavaScript. Если хотите испить эту чашу до дна, то изучить этот язык, а также jQuery и Ajax можно здесь:
>>> JavaScript, jQuery и Ajax с нуля до гуру >>>
|
|
Программирование на JavaScript
Видеокурс о программировании на JavaScript. Содержит 8 больших разделов от основ до работы с сетевыми запросами. |

|
|
Помощь в технических вопросах
Помощь студентам. Курсовые, дипломы, чертежи (КОМПАС), задачи по программированию: Pascal/Delphi/Lazarus; С/С++; Ассемблер; языки программирования ПЛК; JavaScript; VBScript; Fortran; Python; C# и др. Разработка (доработка) ПО ПЛК (предпочтение – ОВЕН, CoDeSys 2 и 3), а также программирование панелей оператора, программируемых реле и других приборов систем автоматизации. |

В этой статье мы изучим методы JavaScript для поиска элементов в HTML-документе: querySelector, querySelectorAll, getElementById и другие. Кроме них рассмотрим ещё следующие: matches, contains и closest. Первые два из них могут быть полезны для выполнения различных проверок, а третий использоваться, когда нужно получить родительский элемент по CSS-селектору.
Методы для выбора HTML-элементов
Работа с веб-страницей так или иначе связана с манипулированием HTML-элементами. Но перед тем, как над ними выполнить некоторые действия (например, добавить стили), их сначала нужно получить.
Выбор элементов в основном выполняется с помощью этих методов:
querySelector;querySelectorAll.
Они позволяют выполнить поиск HTML-элементов по CSS-селектору. При этом querySelector выбирает один элемент, а querySelectorAll – все.
Кроме них имеются ещё:
getElementById;getElementsByClassName;getElementsByTagName;getElementsByName.
Но они сейчас применяются довольно редко. В основном используется либо querySelector, либо querySelectorAll.
querySelectorAll
Метод querySelectorAll применяется для выбора всех HTML-элементов, подходящих под указанный CSS-селектор. Он позволяет искать элементы как по всей странице, так и внутри определённого элемента:
// выберем элементы по классу item во всем документе
const items = document.querySelectorAll('.item');
// выберем .btn внутри #slider
const buttons = document.querySelector('#slider').querySelectorAll('.btn');Здесь на первой строчке мы нашли все элементы с классом item. На следующей строчке мы сначала выбрали элемент с id="slider", а затем в нём все HTML-элементы с классом btn.
Метод querySelectorAll как вы уже догадались принимает в качестве аргумента CSS-селектор в формате строки, который соответственно и определяет искомые элементы. В качестве результата querySelectorAll возвращает объект класса NodeList. Он содержит все найденные элементы:

Полученный набор представляет собой статическую коллекцию HTML-элементов. Статической она называется потому, что она не изменяется. Например, вы удалили элемент из HTML-документа, а в ней как был этот элемент, так он и остался. Чтобы обновить набор, querySelectorAll нужно вызвать заново:
Узнать количество найденных элементов можно с помощью свойства length:
// выберем элементы с атрибутом type="submit"
const submits = document.querySelectorAll('[type="submit"]');
// получим количество найденных элементов
const countSubmits = submits.length;Обращение к определённому HTML-элементу коллекции выполняется также как к элементу массива, то есть по индексу. Индексы начинаются с 0:
// получим первый элемент
const elFirst = submits[0];
// получим второй элемент
const elSecond = submits[1];Здесь в качестве результата мы получаем HTML-элемент или undefined, если элемента с таким индексом в наборе NodeList нет.
Перебор коллекции HTML-элементов
Перебор NodeList обычно осуществляется с помощью forEach:
// получим все <p> на странице
const elsP = document.querySelectorAll('p');
// переберём выбранные элементы
elsP.forEach((el) => {
// установим каждому элементу background-color="yellow"
el.style.backgroundColor = 'yellow';
});Также перебрать набор выбранных элементов можно с помощью цикла for или for...of:
// получим все элементы p на странице
const elsP = document.querySelectorAll('p');
// for
for (let i = 0, length = elsP.length; i < length; i++) {
elsP[i].style.backgroundColor = 'yellow';
}
// for...of
for (let el of elsP) {
el.style.backgroundColor = 'yellow';
}querySelector
Метод querySelector также как и querySelectorAll выполняет поиск по CSS-селектору. Но в отличие от него, он ищет только один HTML-элемент:
// ищем #title во всём документе
const elTitle = document.querySelector('#title');
// ищем footer в <body>
const elFooter = document.body.querySelector('footer');На первой строчке мы выбираем HTML-элемент, имеющий в качестве id значение title. На второй мы ищем в <body> HTML-элемент по тегу footer.
В качестве результата этот метод возвращает найденный HTML-элемент или null, если он не был найден.
querySelector всегда возвращает один HTML-элемент, даже если под указанный CSS-селектор подходят несколько:
<ul id="list">
<li>First</li>
<li>Second</li>
<li>Third</li>
</ul>
<script>
// выберем <li>, расположенный в #list
const elFirst = document.querySelector('#list > li');
elFirst.style.backgroundColor = 'yellow';
</script>Задачу, которую решает querySelector можно выполнить через querySelectorAll:
const elFirst = document.querySelectorAll('#list > li')[0];Но querySelector в отличие от querySelectorAll делает это намного быстрее, да и писать так проще. То есть querySelectorAll не возвращает как querySelector сразу же первый найденный элемент. Он сначала ищет все элементы, и только после того, как он это сделает, мы можем уже обратиться к первому HTML-элементу в этой коллекции.
Обычно перед тем, как выполнить какие-то действия с найденным HTML-элементом необходимо сначала проверить, а действительно ли он был найден:
const elModal = document.querySelector('.modal');
// если элемент .modal найден, то ...
if (elModal) {
// переключим у elModal класс show
elModal.classList.toggle('show');
}Здесь мы сначала проверили существования HTML-элемента, и только потом выполнили над ним некоторые действия.
Методы getElement(s)By* для выбора HTML-элементов
Здесь мы рассмотрим методы, которые сейчас применяются довольно редко для поиска HTML-элементов. Но в некоторых случаях они могут быть очень полезны. Это:
getElementById– получает один элемент поid;getElementsByClassName– позволяет найти все элементы с указанным классом или классами;getElementsByTagName– выбирает элементы по тегу;getElementsByName– получает все элементы с указанным значением атрибутаname.
1. Метод getElementById позволяет найти HTML-элемент на странице по значению id:
<div id="comments">...</div>
...
<script>
// получим HTMLElement и сохраним его в переменную elComments
const elComments = document.getElementById('comments');
</script>В качестве результата getElementById возвращает объект класса HTMLElement или значение null, если элемент не был найден. Этот метод имеется только у объекта document.
Указывать значение id необходимо с учётом регистра. Так например, document.getElementById('aside') и document.getElementById('ASIDE') ищут элементы с разным id.
Обратите внимание, что в соответствии со стандартом в документе не может быть несколько тегов с одинаковым id, так как значение идентификатора на странице должно быть уникальным.
Тем не менее, если вы допустили ошибку и в документе существуют несколько элементов с одинаковым id, то метод getElementById более вероятно вернёт первый элемент, который он встретит в DOM. Но на это полагаться нельзя, так как такое поведение не прописано в стандарте.
То, что делает getElementById можно очень просто решить посредством querySelector:
// получим элемент #title
const elTitle = document.getElementById('title');
// получим элемента #title, используя querySelector
const elTitleSame = document.querySelector('#nav');Кстати, оба этих метода возвращают в качестве результата один и тот же результат. Это либо HTML-элемент (экземпляр класса HTMLElement) или null, если элемент не найден.
2. Метод getElementsByClassName позволяет найти все элементы с заданным классом или классами. Его можно применить для поиска элементов как во всём документе, так и внутри указанного. В первом случае его нужно будет вызывать как метод объекта document, а во втором – как метод соответствующего HTML-элемента:
// найдем элементы с классом control в документе
const elsControl = document.getElementsByClassName('control');
// выберем элементы внутри другого элемента, в данном случае внутри формы с id="myform"
const elsFormControl = document.forms.myform.getElementsByClassName('form-control');В качестве результата он возвращает живую HTML-коллекцию найденных элементов. Чем живая коллекция отличается от статической мы рассмотрим ниже.
Здесь мы сохранили найденные элементы в переменные elsControl и elsFormControl. В первой переменной будет находиться HTMLCollection, содержащая элементы с классом control. Во второй – набор элементов с классом form-control, находящиеся в форме с id="myform". Для получения этой формы мы использовали document.forms.myform.
Метод getElementsByClassName позволяет искать элементы не только по одному классу, но и сразу по нескольким, которые должны присутствовать у элемента:
// выберем элементы .btn.btn-danger
const elsBtn = document.getElementsByClassName('btn btn-danger');На querySelectorAll этот пример решается так:
const elsBtn = document.querySelectorAll('.btn.btn-danger');3. Метод getElementsByTagName предназначен для получения коллекции элементов по имени тега:
// найдем все <a> в документе
const anchors = document.getElementsByTagName('a');
// найдем все >li> внутри #list
const elsLi = document.getElementById('list').getElementsByTagName('li');На первой строчке мы выбрали все <a> в документе и присвоили полученную HTMLCollection переменной anchors. На второй – мы сначала получили #list, а затем в нём нашли все <li>.
Задачу по выбору элементов внутри другого элемента с помощью querySelectorAll выполняется намного проще:
const elsLi = document.querySelectorAll('#list li');Для выбора всех элементов можно использовать символ *:
// выберем все элементы в <body>
const els = document.body.getElementsByTagName('*');4. В JavaScript getElementsByName можно использовать для выбора элементов, имеющих определенное значение атрибута name:
// получим все элементы с name="phone"
const elsPhone = document.getElementsByName('phone');Через querySelectorAll это выполняется так:
const elsPhone = document.querySelectorAll('[name="phone"]');getElementsBy* и живые HTML-коллекции
В JavaScript getElementsByTagName, getElementsByClassName и getElementsByName в отличие от других методов (например, querySelectorAll) возвращают живую коллекцию HTML-элементов (на английском live HTMLCollection). То есть коллекцию содержимое которой автоматически обновляется при изменении DOM. Для наглядности рассмотрим следующий пример.
Например, на странице изначально имеется два <li>. Выберем их с помощью getElementsByTagName и сохраним полученную HTMLCollection в переменную els. Теперь с помощью els мы можем получить эту коллекцию. Сейчас в ней два <li>. Затем через 5 секунд, используя setTimeout добавим ещё один <li>. Если сейчас мы обратимся к переменной els, то увидим, что в ней уже находятся три <li>:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим живую коллекцию <li>
const els = document.getElementsByTagName('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
</script>
Как вы видите, здесь полученная коллекция является живой, то есть она может автоматически измениться. В ней сначала было два <li>. Но после того, как мы на страницу добавили ещё один подходящий элемент, в ней их стало уже три.
Если в коде приведённом выше заменить выбор элементов на querySelectorAll, то мы увидим, что в ней находится статическая (не живая) коллекция элементов:
// получим статическую коллекцию
const els = document.querySelectorAll('li'); <li>Как вы видите количество элементов в коллекции не изменилось. Чтобы после изменения DOM получить актуальную коллекцию элементов, их нужно просто выбрать заново посредством querySelectorAll:
<ul>
<li>One</li>
<li>Two</li>
</ul>
<script>
// получим статическую коллекцию <li>
let els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 2
// через 5 секунд добавим ещё один <li>
setTimeout(() => {
// вставим на страницу новый <li>
document.querySelector('ul').insertAdjacentHTML('beforeend', '<li>Three</li>');
// получим заново статическую коллекцию <li>
els = document.querySelectorAll('li');
// выведем количество <li> в консоль
console.log(`Количество <li>: ${els.length}`); // 3
}, 5000);
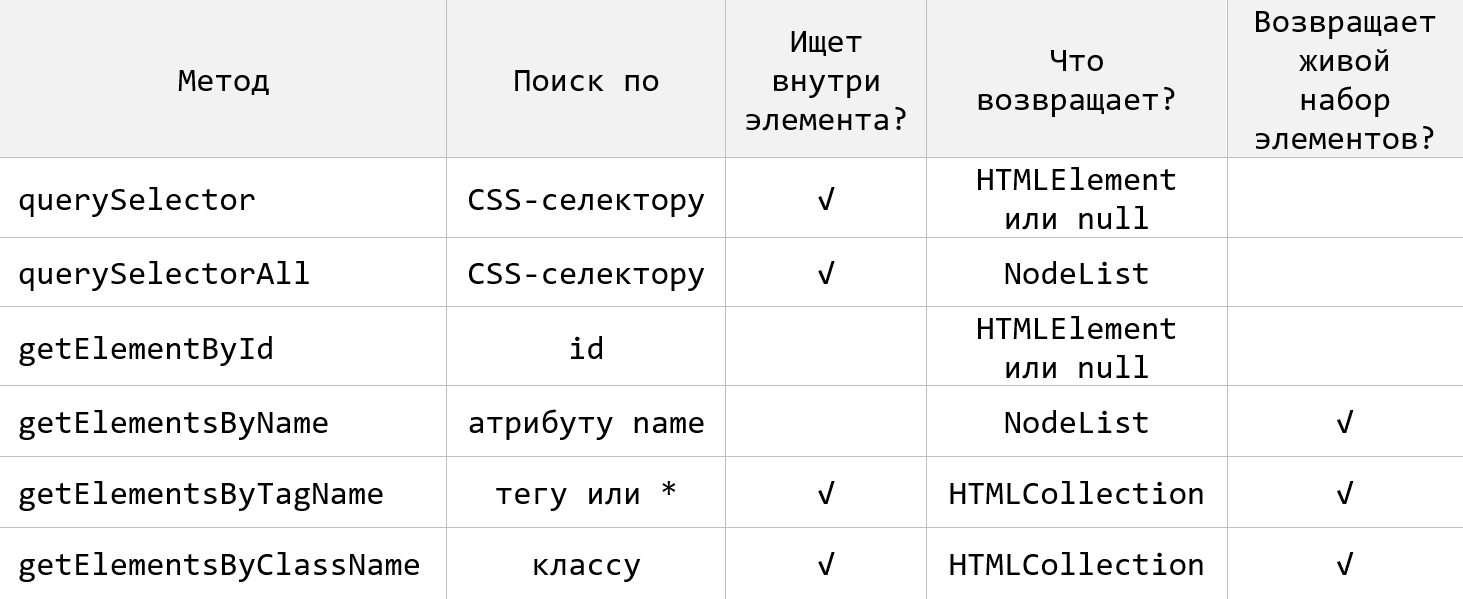
</script>Таким образом в JavaScript насчитывается 6 основных методов для выбора HTML-элементов на странице. По чему они ищут и что они возвращают приведено на следующем рисунке:
Экземпляры класса HTMLCollection не имеют в прототипе метод forEach. Поэтому если вы хотите использовать этот метод для перебора такой коллекции, её необходимо преобразовать в массив:
const items = document.getElementsByClassName('item');
[...items].forEach((el) => {
console.log(el);
});matches, closest и contains
В JavaScript имеются очень полезные методы:
matches– позволяет проверить соответствует ли HTML-элемент указанному CSS-селектору;closest– позволяет найти для HTML-элемента его ближайшего предка, подходящего под указанный CSS-селектор (поиск начинается с самого элемента);contains– позволяет проверить содержит ли данный узел другой в качестве потомка (проверка начинается с самого этого узла).
1. Метод matches ничего не выбирает, но он является очень полезным, так как позволяет проверить HTML-элемент на соответствие CSS-селектору. Он возвращает true, если элемент ему соответствует, иначе false.
// выберем HTML элемент, имеющий атрибут data-target="slider"
const elSlider = document.querySelector('[data-target="slider"]');
// проверим соответствует ли он CSS селектору 'div'
const result = element.matches('div');Пример, в котором выберем все <li>, расположенные внутри #questions, а затем удалим те из них, которые соответствуют селектору .answered:
// выберем все <li> в #questions
const els = document.querySelectorAll('#questions > li');
// переберём выбранные элементы
els.forEach((el) => {
// если элемент соответствует селектору .answered, то ...
if (el.matches('.answered')) {
// удалим элемент
el.remove();
}
});В этом примере проверим каждый <li> на соответствие селектору active. Выведем в консоль каждый такой элемент:
<ul>
<li>One</li>
<li class="active">Two</li>
<li>Three</li>
</ul>
<script>
document.querySelectorAll('li').forEach((el) => {
if (el.matches('.active')) {
console.log(el);
}
});
// li.active
</script>Ранее, в «старых» браузерах данный метод имел название matchesSelector, а также поддерживался с использованием префиксов. Если вам нужна поддержка таких браузеров, то можно использовать следующий полифилл:
if (!Element.prototype.matches) {
Element.prototype.matches = Element.prototype.matchesSelector || Element.prototype.webkitMatchesSelector || Element.prototype.mozMatchesSelector || Element.prototype.msMatchesSelector;
}2. Метод closest очень часто используется в коде. Он позволяет найти ближайшего предка, подходящего под указанный CSS-селектор. При этом поиск начинается с самого элемента, для которого данный метод вызывается. Если этот элемент будет ему соответствовать, то closest вернёт его.
<div class="level-1">
<div class="level-2">
<div class="level-3"></div>
</div>
</div>
<script>
const el = document.querySelector('.level-3');
const elAncestor = el.closest('.level-1');
console.log(elAncestor);
</script>Здесь мы сначала выбираем HTML-элемент .level-3 и присваиваем его переменной el. Далее мы пытаемся среди предков этого элемента включая его сам найти такой, который отвечает заданному CSS-селектору, в данном случае .level-1.
Начинается поиск всегда с самого этого элемента. В данном случае он не подходит под указанный селектор. Следовательно, этот метод переходит к его родителю. Он тоже не отвечает этому CSS-селектору. Значит, closest переходит дальше, то есть уже к его родителю. Этот элемент подходит под указанный селектор. Поэтому поиск прекращается и этот метод возвращает его в качестве результата.
Метод closest возвращает null, когда он дошёл бы конца иерархии и не нашёл элемент отвечающий указанному селектору. То есть, если такого элемента нет среди предков.
В этом примере найдем с помощью closest для .active его ближайшего родителя, отвечающего CSS-селектору #list > li:
<ul id="list">
<li>One</li>
<li>
Two
<ul>
<li>Four</li>
<li class="active">Five</li>
</ul>
</li>
<li>Three</li>
</ul>
<script>
const elActive = document.querySelector('.active');
const elClosest = elActive.closest('#list > li');
elClosest.style.backgroundColor = 'yellow';
</script>В JavaScript closest очень часто используется в обработчиках событий. Это связано с тем, чтобы события всплывают и нам нужно, например, узнать кликнул ли пользователь в рамках какого-то элемента:
document.addEventListener('click', (e) => {
if (e.closest.matches('.btn__action')) {
// пользователь кликнул внутри .btn__action
}
});3. Метод contains позволяет проверить содержит ли некоторый узел другой в качестве потомка. При этом проверка начинается с самого этого узла, для которого этот метод вызывается. Если узел соответствует тому для которого мы вызываем данный метод или является его потомком, то contains в качестве результата возвращает логическое значение true. В противном случае false:
<div id="div-1">
<div id="div-2">
<div id="div-3">...</div>
</div>
</div>
<div id="div-4">...</div>
<script>
const elDiv1 = document.querySelector('#div-1');
elDiv1.contains(elDiv1); // true
const elDiv3 = document.querySelector('#div-3');
elDiv1.contains(elDiv3); // true
const elDiv4 = document.querySelector('#div-4');
elDiv1.contains(elDiv4); // false
</script>Здесь выражение elDiv1.contains(elDiv1) возвращает true, так как проверка начинается с самого элемента. Это выражение elDiv1.contains(elDiv3) тоже возвращает true, так как elDiv3 находится внутри elDiv1. А вот elDiv1.contains(elDiv4) в качестве результата возвращает false, так как elDiv4 не находится внутри elDiv1.
В этом примере проверим с помощью contains содержит ли <p> другие узлы в качестве потомка:
<h1>Tag b</h1>
<p>This is <b>tag b</b>.</p>
<script>
const elP = document.querySelector('p');
const elB = document.querySelector('b');
const textNode = elB.firstChild;
const elH1 = document.querySelector('h1');
elP.contains(elP); // true
elP.contains(elB); // true
elP.contains(elH1); // false
elP.contains(textNode); // true
</script>Метод contains позволяет проверить является ли потомком не только узел-элемент, но и любой другой узел. Например, узнаем является ли потомком elDiv1 указанный текстовый узел:
const elDiv1 = document.querySelector('#div-1');
const textNode = document.querySelector('#div-3').firstChild;
elDiv1.contains(textNode); // trueЗадачи
1. Узнать количество элементов с атрибутом data-toggle="modal" на странице:
const count = document.querySelectorAll('[data-toggle="modal"]').length;
console.log(count);2. Найти все элементы <a> с классом nav внутри элемента <ul> :
const anchors = document.querySelectorAll('ul.nav a');3. Получить элемент по id, значение которого равно pagetitle:
var pagetitle = document.querySelector('#pagetitle');4. Выполнить поиск элемента по классу nav:
var el = document.querySelector('.nav');5. Найти элемент <h3>, находящийся в теге <div> с классом comments, который в свою очередь расположен в <main>:
var header = document.querySelector('main div.comments h3');6. Имеется страница. В ней следует выбрать:
- последний элемент с классом
article, расположенный в<main>(решение); - все элементы
.section, находящиеся в.asideкроме 2 второго (решение); - элемент
<nav>расположенный после<header>(решение).
Кажется, что программирование — это сложно, особенно если никогда не приходилось с ним сталкиваться. На самом деле всё зависит от задачи. Чтобы вносить небольшие изменения на сайт, хватит и азов, а их может освоить даже человек без технического образования. Об этих азах и пойдет речь в статье. Расскажем об устройстве исходного кода, о том, как начать в нём немного разбираться, и ответим на вопрос, зачем всё это вам нужно.
Примечание: мы не будем лезть в дебри и подробно описывать процесс программирования. Расскажем о том минимуме, что пригодится в работе над вашим сайтом.
Зачем понимать исходный код
Сначала поговорим о том, зачем вам нужно что-то знать о коде, если вы не программист. Да, здорово расширять свои границы. Но главное, что вы можете получить из этого знания — пользу для бизнеса.
Зная, как устроен исходный код, вы сможете:
- Больше понимать в SEO-продвижении.
Если просто смотреть на страницу сайта, вы не сможете проанализировать, правильно ли настроено SEO-продвижение, а инструменты для анализа не всегда могут быть под рукой. Только в коде проверяют, на месте ли метаданные и обязательные элементы — основная информация для успешного SEO. Поэтому заглядывать в исходный код становится обычной практикой маркетологов или владельцев бизнеса, которые сами занимаются продвижением.
Плюс вам больше не будет казаться магией работа SEO-специалиста. Вы будете говорить на одном языке и понимать, как поисковики видят ваш сайт и что можно улучшить.
- Анализировать сайты конкурентов на более глубоком уровне.
Если вы решите проанализировать сайты конкурентов, немного разбираясь в коде, вы сможете оценить не только визуальную и контентную стороны страниц. У вас получится определить, с помощью каких ключевых слов продвигается сайт, на какой CMS работает и немного больше понять стратегию продвижения конкурентов.
- Составлять грамотные ТЗ для разработчика самостоятельно.
Вам будет легче представить и объяснить разработчику, как вы видите свою задумку. А значит, на финальной стадии работ не окажется, что всё сделано не так, а деньги и время уже потрачены.
- Лучше понимать программистов.
Когда программист будет объяснять вам, в каких правках нуждается сайт компании, вы всё поймёте и сможете на равных обсудить это с сотрудником. Вам будет проще нанимать человека на IT-должность и разбираться в сметах на обслуживание сайта.
- Экономить, самостоятельно внося изменения в сайт.
Экономнее изучить азы программирования и быстро устранять проблемы самостоятельно вместо того, чтобы нанимать программиста для выполнения небольших, но частых задач. Например, менять размеры баннеров или цвет текста на странице.
Что такое исходный код сайта
Национальная библиотека им. Н. Э. Баумана говорит, что исходный код — это текст компьютерной программы, который может прочитать человек, на языке программирования или языке разметки.
Именно код скрывается за внешней стороной любой интернет-страницы. Он выглядит как список пронумерованных строк с информацией о том или ином элементе страницы.
Как посмотреть код любого сайта
Расскажем, как посмотреть исходный код страницы в браузере Google Chrome*. В остальных браузерах этот процесс примерно такой же.
Код вызывается одной из комбинаций:
- комбинация клавиш Ctrl + U или правая кнопка мыши → «Просмотр кода страницы» — вызывает «полотно» кода в отдельном окне браузера. Вы сможете увидеть структуру всей страницы. Вот как это выглядит:
Чтобы не утонуть в огромном количестве новых символов, нужно разобраться, что такое HTML, CSS и JavaScript.
Что такое HTML
HTML — язык гипертекстовой разметки. На нём написано большинство сайтов в интернете.
Что можно узнать о сайте из исходного кода
Код сайта предназначен в первую очередь для браузера и поисковых систем. Браузеру он говорит, что и в каком порядке выводить на странице. Поисковые системы берут из исходного кода всю информацию о странице: заголовок, описание, метаданные — всё то, что потребуется, чтобы показать страницу в выдаче поисковика. Обычный пользователь тоже может прочитать этот специальный текст — достаточно знать, как он устроен.
Все элементы кода нужны для правильного расположения разделов и деталей страницы. Всё это вы сможете найти и проанализировать, внимательно изучив исходный код сайта:
- текст, который есть на странице;
- цвета, шрифты и размеры элементов страницы;
- иллюстрации, фотографии и другие детали;
- ссылки;
- важные теги, метатеги и атрибуты кода;
- скрипты, счётчики, генераторы заявок, коды идентификации в системах и пр.;
- данные JavaScript;
- ошибки и поломки в коде и прочее.
Чтобы лучше понять теорию, разберёмся в коде страниц блога RU-CENTER: найдём теги, картинки и другую информацию.
Для начала открываем страницу и вызываем интерактивный код (Ctrl + Shift + I). Откроется интерактивная панель с кодом, поделённая на две области. Слева — HTML-код (вкладка Elements), справа — CSS (вкладка Styles). Нам пока нужна левая часть с HTML.
Основные теги
HTML-страница состоит из набора тегов, которые вместе с содержимым называются элементами — это строительный материал веб-страницы. Другими словами, теги — команды для браузера, чтобы он понял, как нужно показывать сайт пользователю. Указывая в коде определенные теги, вы говорите браузеру: «Это текст, а это картинка, это ссылка, а это кнопка или форма». И браузер показывает все элементы интерфейса так, как вы их разместили.
Теги обычно открываются и закрываются так: <tag> — открытие тега, </tag> — закрытие.
Теги делятся на два вида: блочные и строчные.
- Блочные теги всегда занимают отдельную строку в коде и обозначают целый элемент страницы сайта. Пример: заголовки или параграфы.
Немного разобрались с основными HTML-элементами, теперь поговорим о том, что такое CSS.
Что такое CSS
CSS (Cascading Style Sheets) — каскадные таблицы стилей. Это язык, который отвечает за внешний вид HTML-документа, — CSS и HTML действуют в одной связке.
Если HTML отвечает за структуру, то CSS определяет стиль документа: дизайн, вёрстку, адаптацию для разных устройств.
Страница сайта, написанная только на HTML, выглядит просто как текст, поделённый на абзацы, с разными начертаниями шрифтов, гиперссылками, списками и таблицами:
А так выглядит та же страница, но со стилями CSS:
Раньше, примерно до 1996 года, стили были встроены в HTML, код становился громоздким и в нём было сложно разобраться. Тогда появился CSS со своим языком, правилами и возможностью вынести все стили в отдельный файл. Процесс создания сайтов стал более гибким, управлять стилями оказалось проще — теперь стиль абзаца не нужно править в HTML-файле вручную для каждого абзаца— достаточно в CSS-файле отредактировать одно правило. Плюс стало проще читать и обслуживать HTML-код.
Главный тег для элементов CSS — <style>. Стили, которые нужно подключить к HTML-документу, как правило, выносят в отдельный CSS-файл, а после прописывают ссылку на него в коде HTML.
Что такое JavaScript
JavaScript — логический язык программирования. Он сложнее, чем HTML или CSS, поддерживается всеми современными браузерами, его используют практически все сайты.
В отличие от HTML и CSS, JavaScript позволяет использовать на сайтах более мощные и сложные функции, создавать интерактивные страницы с динамичными элементами. Например:
- отслеживать аналитику,
- создавать анимации,
- встраивать всплывающие окна и другое.
На сайте скрипты на этом языке найти просто. Открываем интерактивный код, нажимаем Ctrl + F и вводим в поле поиска JavaScript:
Здесь мы видим, что тег с пометкой javascript отвечает за отслеживание взаимодействий пользователя с сайтом: это тег Google Аналитики*. Но мы не будем подробно останавливаться на нём в этой статье.
Как познакомиться с кодом поближе
Поговорили о теории, теперь — практика. Глубоко копать не будем, чтобы не запутаться. Покажем, как отредактировать код в браузере, а после — провести мини-SEO-аудит, используя только выдачу поисковика и страницу вашего сайта. Начнём с редактирования кода.
Как редактировать HTML-код прямо в браузере
Вы можете отредактировать код любой интернет-страницы с одним «но»: эти изменения будут видны только вам и после перезагрузки страницы всё вернётся к прежнему виду. Поэтому смелее — вы точно ничего не сломаете.
Обычно это делается, чтобы:
- Визуально менять тексты и данные на сайте, проверять новые форматы.
- Тестировать блоки и элементы: заголовки, сноски, абзацы, врезки и т. п.
- Править информацию на странице, чтобы показать скриншоты дизайнерам, редакторам или разработчикам.
Давайте немного поменяем текст на странице блога RU-CENTER. Открываем страницу в браузере Google Chrome*. Находим заголовок, нажимаем на него правой кнопкой мыши и выбираем в меню «Просмотр кода».
Мы хотим исправить этот заголовок. Нажимаем дважды левой кнопкой мыши на текст в строке кода, пишем новый заголовок и нажимаем Enter:
Или, например, хотим мы поменять текст на кнопке. Кликаем на неё правой кнопкой мыши, выбираем в меню пункт «Просмотреть код»:
И меняем его — в области кода левой кнопкой мыши дважды нажимаем на текст, печатаем новую фразу и нажимаем Enter:
А ещё поменяем иллюстрацию. Кликаем на изображение правой кнопкой мыши и выбираем пункт «Просмотреть код»:
Попробуйте поэкспериментировать на своём сайте. Это интересно и полезно: вы сможете внести изменения, сделать скриншот наиболее удачной версии и использовать его при составлении ТЗ на доработку сайта.
Как редактировать CSS-код прямо в браузере
CSS-код можно редактировать так же, как и HTML: открываем код страницы в браузере и заменяем или удаляем элементы. Если обновить страницу, всё вернётся на свои места.
Изменим размер картинки на странице RU-CENTER. Открываем код изображения, находим внизу окна кода нужное поле:
Уменьшим иллюстрацию, изменив значения в блоке:
Проверьте основные теги для SEO на вашем сайте
Мы разобрались в HTML-тегах, узнали, как отредактировать код сайта в браузере и ничего не сломать. Теперь давайте проведём мини-SEO-аудит сайта, используя только его страницу и выдачу поисковика.
Для тренировки и насмотренности попробуйте найти в коде своей страницы указанные ниже теги. Они обязательно должны быть на каждой странице сайта как самые важные для SEO-продвижения.
Title
<title>Заголовок страницы</title>. Это самый важный тег для SEO, его нужно заполнять для каждой страницы сайта. Информация из title не показывается напрямую на странице, но отображается в названии страницы в верхней области браузера:
Найдём title на странице RU-CENTER. Открываем код сайта с помощью инструментов разработчика. Нажимаем Ctrl + F и вводим в поле поиска title. Вот и наш заголовок:
Подробнее о тегах и основных ошибках SEO-продвижения сайта вы можете прочитать в нашей статье.
Где бесплатно научат понимать код и программировать
В статье мы дали общую информацию об устройстве HTML-кода сайта. Чтобы окунуться в тему глубже, вы можете пройти специальные курсы. Сейчас их много, мы дадим список из нескольких самых популярных вариантов.
- Html Academy. Бесплатные задания после регистрации.
- «Нетология». Курсы: «Основы HTML и CSS», «Python-разработка для начинающих» и др.
- Geekbrains. Интенсивы: «Основы программирования», «Python для начинающих» и др.
- Яндекс Практикум. Все курсы можно попробовать бесплатно, например: «Как стать веб-разработчиком», «Как стать Python-разработчиком» и др.
- «Смотри.Учись». Курс «PHP. Базовый курс» и др.
- Гарвард, Основы программирования. Видео-лекции на YouTube.
- Поиск по id
- Поиск по тегу
- Получить всех потомков
-
Поиск по
name: getElementsByName - Другие способы
Стандарт DOM предусматривает несколько средств поиска элемента. Это методы getElementById, getElementsByTagName и getElementsByName.
Более мощные способы поиска предлагают javascript-библиотеки.
Поиск по id
Самый удобный способ найти элемент в DOM – это получить его по id. Для этого используется вызов document.getElementById(id)
Например, следующий код изменит цвет текста на голубой в div‘е c id="dataKeeper":
document.getElementById('dataKeeper').style.color = 'blue'
Поиск по тегу
Следующий способ – это получить все элементы с определенным тегом, и среди них искать нужный. Для этого служит document.getElementsByTagName(tag). Она возвращает массив из элементов, имеющих такой тег.
Например, можно получить второй элемент(нумерация в массиве идет с нуля) с тэгом li:
document.getElementsByTagName('LI')[1]
Что интересно, getElementsByTagName можно вызывать не только для document, но и вообще для любого элемента, у которого есть тег (не текстового).
При этом будут найдены только те объекты, которые находятся под этим элементом.
Например, следующий вызов получает список элементов LI, находящихся внутри первого тега div:
document.getElementsByTagName('DIV')[0].getElementsByTagName('LI')
Получить всех потомков
Вызов elem.getElementsByTagName('*') вернет список из всех детей узла elem в порядке их обхода.
Например, на таком DOM:
<div id="d1">
<ol id="ol1">
<li id="li1">1</li>
<li id="li2">2</li>
</ol>
</div>
Такой код:
var div = document.getElementById('d1')
var elems = div.getElementsByTagName('*')
for(var i=0; i<elems.length; i++) alert(elems[i].id)
Выведет последовательность: ol1, li1, li2.
Поиск по name: getElementsByName
Метод document.getElementsByName(name) возвращает все элементы, у которых имя (атрибут name) равно данному.
Он работает только с теми элементами, для которых в спецификации явно предусмотрен атрибут name: это form, input, a, select, textarea и ряд других, более редких.
Метод document.getElementsByName не будет работать с остальными элементами типа div,p и т.п.
Другие способы
Существуют и другие способы поиска по DOM: XPath, cssQuery и т.п. Как правило, они реализуются javascript-библиотеками для расширения стандартных возможностей браузеров.
Также есть метод getElementsByClassName для поиска элементов по классу, но он совсем не работает в IE, поэтому в чистом виде им никто не пользуется.
Частая опечатка связана с отсутствием буквы s в названии метода getElementById, в то время как в других методах эта буква есть: getElementsByName.
Правило здесь простое: один элемент – Element, много – Elements. Все методы *Elements* возвращают список узлов.